1. Введение
В этом руководстве мы поймем, как работать с данными событий и Apache Druid . Мы рассмотрим основы данных событий и архитектуры друидов. В рамках этого мы создадим простой конвейер данных, используя различные функции Druid, которые охватывают различные режимы приема данных и различные способы запроса подготовленных данных.
2. Основные понятия
Прежде чем мы углубимся в детали работы Apache Druid, давайте сначала рассмотрим некоторые основные понятия. Область, которая нас интересует, — это массовая аналитика данных о событиях в реальном времени.
Следовательно, крайне важно понимать, что мы подразумеваем под данными о событиях и что требуется для их анализа в режиме реального времени в масштабе.
2.1. Что такое данные о событиях?
Данные о событии относятся к части информации об изменении, которое происходит в определенный момент времени . Данные о событиях почти повсеместно используются в современных приложениях. От классических журналов приложений до данных современных датчиков, генерируемых вещами, они есть практически везде. Они часто характеризуются машиночитаемой информацией, генерируемой в массовом масштабе.
Они обеспечивают несколько функций, таких как прогнозирование, автоматизация, связь и интеграция, и это лишь некоторые из них. Кроме того, они важны в архитектуре, управляемой событиями.
2.2. Что такое Апач Друид?
Apache Druid — это аналитическая база данных в реальном времени, предназначенная для быстрого анализа событийно-ориентированных данных . Druid был запущен в 2011 году, с открытым исходным кодом под лицензией GPL в 2012 году и переведен на лицензию Apache в 2015 году. Он управляется Apache Foundation при участии сообщества нескольких организаций. Он обеспечивает прием данных в режиме реального времени, высокую производительность запросов и высокую доступность.
Название Druid связано с тем, что его архитектура может меняться для решения различных типов проблем с данными. Он часто используется в приложениях бизнес-аналитики для анализа большого объема данных в реальном времени и исторических данных.
3. Архитектура друидов
Druid — это распределенный источник данных, ориентированный на столбцы, написанный на Java . Он способен принимать огромные объемы данных о событиях и предлагать запросы с малой задержкой поверх этих данных. Кроме того, он предлагает возможность произвольно нарезать данные.
Довольно интересно понять, как архитектура Druid поддерживает эти функции. В этом разделе мы рассмотрим некоторые важные части архитектуры друидов.
3.1. Дизайн хранилища данных
Важно понимать, как Druid структурирует и хранит свои данные, что позволяет разделять и распределять их. Druid по умолчанию разделяет данные во время обработки и сохраняет их в куски и сегменты:
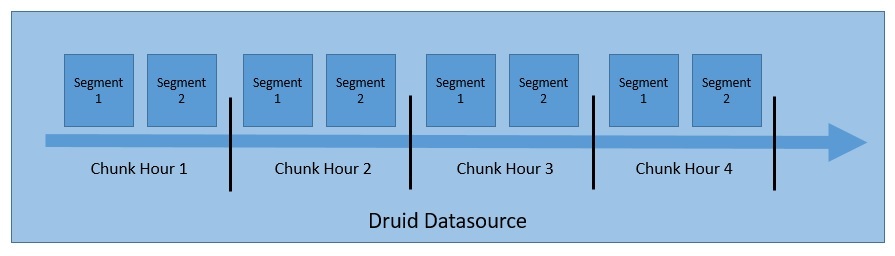
Druid хранит данные в так называемом «источнике данных» , который логически похож на таблицы в реляционных базах данных. Кластер Druid может обрабатывать несколько источников данных параллельно, получаемых из разных источников.
Каждый источник данных секционируется — по времени по умолчанию, а также по другим атрибутам, если они настроены таким образом. Временной диапазон данных называется «фрагментом» — например, данные за час, если данные разделены по часам.
Каждый фрагмент далее разбивается на один или несколько «сегментов» , которые представляют собой отдельные файлы, состоящие из множества строк данных. Источник данных может иметь от нескольких сегментов до миллионов сегментов.
3.2. Друидские процессы
Druid имеет многопроцессорную и распределенную архитектуру . Следовательно, каждый процесс можно масштабировать независимо, что позволяет нам создавать гибкие кластеры. Давайте разберемся с важными процессами, которые являются частью Друида:
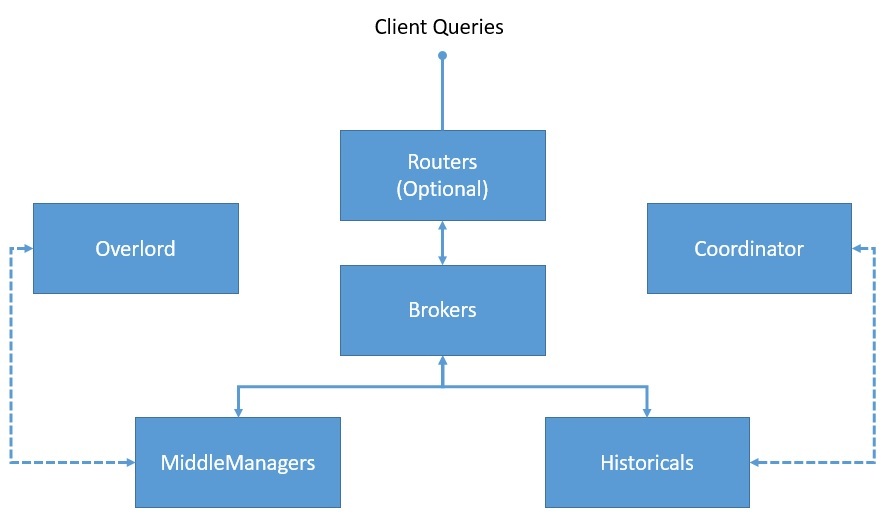
- Координатор : этот процесс в основном отвечает за управление сегментами и их распределение, а также связывается с историческими процессами для загрузки или удаления сегментов на основе конфигураций.
- Overlord : это основной процесс, который отвечает за прием задач, координацию распределения задач, создание блокировок вокруг задач и возврат статуса вызывающим абонентам.
- Брокер : это процесс, которому отправляются все запросы для выполнения в распределенном кластере; он собирает метаданные из Zookeeper и направляет запросы процессам, имеющим нужные сегменты
- Маршрутизатор : это необязательный процесс, который можно использовать для маршрутизации запросов к различным процессам брокера, что обеспечивает изоляцию запросов для более важных данных.
- Исторические : это процессы, которые хранят запрашиваемые данные; они поддерживают постоянную связь с Zookeeper и следят за информацией о сегментах, которую они должны загружать и обслуживать.
- MiddleManager : это рабочие процессы, которые выполняют отправленные задачи; они пересылают задачи Peons, работающим на отдельных JVM, тем самым обеспечивая изоляцию ресурсов и журналов.
3.3. Внешние зависимости
Помимо основных процессов, Druid зависит от нескольких внешних зависимостей, чтобы его кластер функционировал должным образом .
Давайте посмотрим, как формируется кластер Druid вместе с основными процессами и внешними зависимостями:
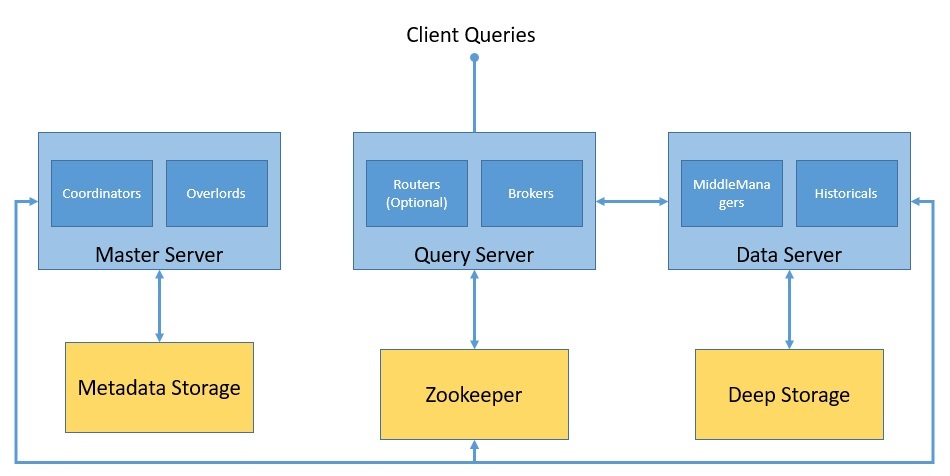
Druid использует глубокое хранилище для хранения любых данных, которые были загружены в систему. Они не используются для ответа на запросы, а используются в качестве резервной копии данных и для передачи данных между процессами. Это может быть что угодно, от локальной файловой системы до распределенного хранилища объектов, такого как S3 и HDFS.
Хранилище метаданных используется для хранения общих системных метаданных, таких как информация об использовании сегмента и информация о задачах. Однако он никогда не используется для хранения фактических данных. Это реляционная база данных, такая как Apache Derby, PostgreSQL или MySQL.
Друид использует Apache Zookeeper для управления текущим состоянием кластера . Он облегчает ряд операций в кластере Druid, таких как выборы координатора/повелителя-лидера, протокол публикации сегментов и протокол загрузки/удаления сегментов.
4. Настройка друида
Druid предназначен для развертывания в виде масштабируемого, отказоустойчивого кластера. Однако настроить кластер Druid производственного уровня не так уж и просто . Как мы видели ранее, существует множество процессов и внешних зависимостей, которые необходимо установить и настроить. Поскольку кластер можно создать гибким образом, мы должны обратить внимание на наши требования, чтобы соответствующим образом настроить отдельные процессы.
Кроме того, Druid поддерживается только в Unix-подобных средах, а не в Windows . Кроме того, для запуска процессов Druid требуется Java 8 или более поздняя версия. Существует несколько конфигураций с одним сервером для настройки Druid на одном компьютере для запуска руководств и примеров. Однако для запуска рабочей нагрузки рекомендуется настроить полноценный кластер Druid с несколькими машинами.
Для целей этого руководства мы настроим Druid на одном компьютере с помощью официального образа Docker , опубликованного на Docker Hub . Это позволяет нам запускать Druid и в Windows, которая, как мы обсуждали ранее, иначе не поддерживается. Доступен файл компоновки Docker , который создает контейнер для каждого процесса Druid и его внешних зависимостей.
Мы должны предоставить значения конфигурации для Druid в качестве переменных среды . Самый простой способ добиться этого — предоставить файл с именем «environment» в том же каталоге, что и файл компоновки Docker.
После того, как у нас есть Docker compose и файл окружения, запустить Druid так же просто, как запустить команду в том же каталоге:
docker-compose up
Это вызовет все контейнеры, необходимые для установки Druid на одной машине. Мы должны быть осторожны, чтобы предоставить машине Docker достаточно памяти, поскольку Druid потребляет значительное количество ресурсов.
5. Прием данных
Первым шагом к созданию конвейера данных с использованием Druid является загрузка данных в Druid. Этот процесс называется приемом или индексированием данных в архитектуре Druid . Нам нужно найти подходящий набор данных, чтобы продолжить этот урок.
Теперь, как мы уже собрали, нам нужно собрать данные, которые являются событиями и имеют некоторую временную природу , чтобы максимально использовать инфраструктуру Друида.
Официальный путеводитель по Друиду использует простые и элегантные данные, содержащие правки страницы Википедии за определенную дату . Мы продолжим использовать это для нашего урока здесь.
5.1. Модель данных
Давайте начнем с изучения структуры данных, которые у нас есть. Большая часть создаваемого нами конвейера данных очень чувствительна к аномалиям данных, и поэтому необходимо максимально очистить данные.
Хотя существуют сложные способы и инструменты для выполнения анализа данных, мы начнем с визуального осмотра. Быстрый анализ показывает, что во входных данных есть события, записанные в формате JSON, с одним событием, содержащим типичные атрибуты :
{
"time": "2015-09-12T02:10:26.679Z",
"channel": "#pt.wikipedia",
"cityName": null,
"comment": "Houveram problemas na última edição e tive de refazê-las, junto com as atualizações da página.",
"countryIsoCode": "BR",
"countryName": "Brazil",
"isAnonymous": true,
"isMinor": false,
"isNew": false,
"isRobot": false,
"isUnpatrolled": true,
"metroCode": null,
"namespace": "Main",
"page": "Catarina Muniz",
"regionIsoCode": null,
"regionName": null,
"user": "181.213.37.148",
"delta": 197,
"added": 197,
"deleted": 0
}
Хотя существует довольно много атрибутов, определяющих это событие, некоторые из них представляют для нас особый интерес при работе с Друидом:
- Отметка времени
- Габаритные размеры
- Метрики
Друиду требуется определенный атрибут для идентификации столбца временных меток . В большинстве случаев анализатор данных Druid способен автоматически определить лучшего кандидата. Но у нас всегда есть выбор, особенно если в наших данных нет подходящего атрибута.
Измерения — это атрибуты, которые Druid хранит как есть . Мы можем использовать их для любых целей, таких как группировка, фильтрация или применение агрегаторов. У нас есть возможность выбрать измерения в спецификации приема, которые мы обсудим далее в руководстве.
** Метрики — это атрибуты, которые, в отличие от измерений, по умолчанию хранятся в агрегированном виде . ** Мы можем выбрать функцию агрегации, которую Друид будет применять к этим атрибутам во время приема. Вместе с включенным сведением это может привести к компактному представлению данных.
5.2. Методы приема
Теперь мы обсудим различные способы приема данных в Druid. Как правило, данные, управляемые событиями, являются потоковыми по своей природе, что означает, что они продолжают генерироваться с разной скоростью с течением времени, как правки Википедии.
Тем не менее, у нас могут быть пакеты данных за определенный период времени, когда данные более статичны по своей природе, как все правки Википедии, которые произошли в прошлом году.
У нас также могут быть различные варианты использования данных для решения, и у Druid есть фантастическая поддержка для большинства из них. Давайте рассмотрим два наиболее распространенных способа использования Druid в конвейере данных:
- Потоковое прослушивание
- Пакетный прием
Наиболее распространенный способ приема данных в Druid — через службу потоковой передачи Apache , где Druid может считывать данные непосредственно из Kafka. Druid также поддерживает другие платформы, такие как Kinesis. Мы должны запустить супервизоров в процессе перегрузки, который создает и управляет задачами индексирования Kafka. Мы можем запустить супервизор, отправив спецификацию супервизора в виде файла JSON через команду HTTP POST процесса перегрузки.
В качестве альтернативы мы можем принимать данные пакетно — например, из локального или удаленного файла . Он предлагает выбор для пакетного приема на основе Hadoop для приема данных из файловой системы Hadoop в формате файла Hadoop. Чаще всего мы можем выбрать собственный пакетный прием последовательно или параллельно. Это более удобный и простой подход, так как он не имеет внешних зависимостей.
5.3. Определение спецификации задачи
В этом руководстве мы настроим собственную задачу пакетного приема для имеющихся у нас входных данных. У нас есть возможность настроить задачу из консоли Druid, что дает нам интуитивно понятный графический интерфейс. В качестве альтернативы мы можем определить спецификацию задачи в виде файла JSON и отправить его процессу повелителя с помощью сценария или командной строки.
Давайте сначала определим простую спецификацию задачи для приема наших данных в файл с именем wikipedia-index.json :
{
"type" : "index_parallel",
"spec" : {
"dataSchema" : {
"dataSource" : "wikipedia",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"timestampSpec": {
"column": "time",
"format": "iso"
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2015-09-12/2015-09-13"],
"rollup" : false
}
},
"ioConfig" : {
"type" : "index_parallel",
"inputSource" : {
"type" : "local",
"baseDir" : "quickstart/tutorial/",
"filter" : "wikiticker-2015-09-12-sampled.json.gz"
},
"inputFormat" : {
"type": "json"
},
"appendToExisting" : false
},
"tuningConfig" : {
"type" : "index_parallel",
"maxRowsPerSegment" : 5000000,
"maxRowsInMemory" : 25000
}
}
}
Давайте разберемся в этой спецификации задачи с точки зрения основ, которые мы рассмотрели в предыдущих подразделах:
- Мы выбрали задачу
index_parallel, которая обеспечивает параллельную обработку собственных пакетов. - Источник данных, который мы будем использовать в этой задаче, называется «
википедия». - Временная метка для наших данных исходит из атрибута «время».
- Есть ряд атрибутов данных, которые мы добавляем в качестве измерений.
- Мы не используем никаких показателей для наших данных в текущей задаче
- Сведение, включенное по умолчанию, для этой задачи следует отключить.
- Источником входных данных для задачи является локальный файл с именем
wikiticker-2015-09-12-sampled.json.gz. - Мы не используем какой-либо вторичный раздел, который мы можем определить в
файле tuningConfig.
Эта спецификация задачи предполагает, что мы загрузили файл данных wikiticker-2015-09-12-sampled.json.gz и сохранили его на локальном компьютере, где работает Druid. Это может быть сложнее, когда мы запускаем Druid в качестве контейнера Docker. К счастью, Druid поставляется с этими демонстрационными данными, представленными по умолчанию в папке quickstart/tutorial .
5.4. Отправка спецификации задачи
Наконец, мы можем отправить эту спецификацию задачи процессу overlord через командную строку, используя такой инструмент, как curl :
curl -X 'POST' -H 'Content-Type:application/json' -d @wikipedia-index.json http://localhost:8081/druid/indexer/v1/task
Обычно приведенная выше команда возвращает идентификатор задачи , если отправка прошла успешно. Мы можем проверить состояние нашей задачи приема через консоль Druid или путем выполнения запросов, которые мы рассмотрим в следующем разделе.
5.5. Расширенные концепции приема
Друид лучше всего подходит, когда у нас есть огромные объемы данных, с которыми нужно работать — определенно не те данные, которые мы видели в этом руководстве! Теперь, чтобы включить функции в масштабе, архитектура Druid должна предоставлять подходящие инструменты и приемы.
Хотя мы не будем использовать их в этом руководстве, давайте быстро обсудим свертывание и разбиение на разделы.
Данные о событиях вскоре могут вырасти до огромных объемов, что может повлиять на производительность запросов, которую мы можем достичь. Во многих сценариях мы можем суммировать данные с течением времени . Это то, что мы знаем как свертывание в Друиде. Когда сведение включено, Druid пытается свернуть строки с одинаковыми размерами и временными метками во время загрузки . Хотя это может сэкономить место, свертывание приводит к потере точности запроса, поэтому мы должны использовать его рационально.
Еще один потенциальный способ повысить производительность в условиях растущего объема данных — это распределение данных и, следовательно, рабочей нагрузки. По умолчанию Druid разделяет данные на основе меток времени на фрагменты времени , содержащие один или несколько сегментов. Кроме того, мы можем решить сделать вторичное разбиение, используя естественные размеры, чтобы улучшить локальность данных. Кроме того, Druid сортирует данные внутри каждого сегмента сначала по метке времени, а затем по другим параметрам, которые мы настраиваем.
6. Запрос данных
Как только мы успешно выполнили прием данных, они должны быть готовы для запроса. В Druid есть несколько способов запроса данных. Самый простой способ выполнить запрос в Druid — через консоль Druid . Однако мы также можем выполнять запросы, отправляя команды HTTP или используя инструмент командной строки.
Двумя известными способами создания запросов в Druid являются собственные запросы и запросы, подобные SQL. Мы собираемся создать несколько базовых запросов обоими этими способами и отправить их по HTTP с помощью curl . Давайте выясним, как мы можем создать несколько простых запросов к данным, которые мы получили ранее в Druid.
6.1. Собственные запросы
Нативные запросы в Druid используют объекты JSON, которые мы можем отправить брокеру или маршрутизатору для обработки . Мы можем отправлять запросы с помощью команды HTTP POST, среди прочего, чтобы сделать то же самое.
Давайте создадим файл JSON с именем simple_query_native.json :
{
"queryType" : "topN",
"dataSource" : "wikipedia",
"intervals" : ["2015-09-12/2015-09-13"],
"granularity" : "all",
"dimension" : "page",
"metric" : "count",
"threshold" : 10,
"aggregations" : [
{
"type" : "count",
"name" : "count"
}
]
}
Это простой запрос, который извлекает первые десять страниц, которые получили наибольшее количество правок в период с 12 по 13 сентября 2019 года.
Давайте опубликуем это через HTTP, используя curl :
curl -X 'POST' -H 'Content-Type:application/json' -d @simple_query_native.json http://localhost:8888/druid/v2?pretty
Этот ответ содержит сведения о первых десяти страницах в формате JSON:
[ {
"timestamp" : "2015-09-12T00:46:58.771Z",
"result" : [ {
"count" : 33,
"page" : "Wikipedia:Vandalismusmeldung"
}, {
"count" : 28,
"page" : "User:Cyde/List of candidates for speedy deletion/Subpage"
}, {
"count" : 27,
"page" : "Jeremy Corbyn"
}, {
"count" : 21,
"page" : "Wikipedia:Administrators' noticeboard/Incidents"
}, {
"count" : 20,
"page" : "Flavia Pennetta"
}, {
"count" : 18,
"page" : "Total Drama Presents: The Ridonculous Race"
}, {
"count" : 18,
"page" : "User talk:Dudeperson176123"
}, {
"count" : 18,
"page" : "Wikipédia:Le Bistro/12 septembre 2015"
}, {
"count" : 17,
"page" : "Wikipedia:In the news/Candidates"
}, {
"count" : 17,
"page" : "Wikipedia:Requests for page protection"
} ]
} ]
6.2. Друид SQL
В Druid есть встроенный слой SQL, который дает нам свободу создавать запросы в привычных SQL-подобных конструкциях . Он использует Apache Calcite для анализа и планирования запросов. Однако Druid SQL преобразует SQL-запросы в собственные запросы брокера запросов перед отправкой их в процессы обработки данных.
Давайте посмотрим, как мы можем создать тот же запрос, что и раньше, но с помощью Druid SQL. Как и прежде, мы создадим файл JSON с именем simple_query_sql.json :
{
"query":"SELECT page, COUNT(*) AS counts /
FROM wikipedia WHERE \"__time\" /
BETWEEN TIMESTAMP '2015-09-12 00:00:00' AND TIMESTAMP '2015-09-13 00:00:00' /
GROUP BY page ORDER BY Edits DESC LIMIT 10"
}
Обратите внимание, что запрос был разбит на несколько строк для удобства чтения, но он должен отображаться в одной строке. Опять же, как и раньше, мы отправим этот запрос по HTTP, но в другую конечную точку:
curl -X 'POST' -H 'Content-Type:application/json' -d @simple_query_sql.json http://localhost:8888/druid/v2/sql
Вывод должен быть очень похож на то, что мы получили ранее с собственным запросом.
6.3. Типы запросов
В предыдущем разделе мы видели тип запроса, в котором мы извлекали первые десять результатов для метрики «количество» на основе интервала . Это всего лишь один тип запросов, который поддерживает Druid, и он известен как запрос TopN . Конечно, мы можем сделать этот простой запрос TopN намного интереснее, используя фильтры и агрегации. Но это не входит в задачи данного урока. Однако в Druid есть несколько других запросов, которые могут нас заинтересовать.
Некоторые из популярных включают Timeseries и GroupBy.
Запросы временных рядов возвращают массив объектов JSON, где каждый объект представляет значение, как описано в запросе временных рядов, — например, среднесуточное значение параметра за последний месяц.
Запросы GroupBy возвращают массив объектов JSON, где каждый объект представляет группу, как описано в запросе groupby. Например, мы можем запросить среднесуточное значение параметра за последний месяц, сгруппированного по другому параметру.
Существует несколько других типов запросов, включая Scan , Search , TimeBoundary , SegmentMetadata и DatasourceMetadata .
6.4. Расширенные концепции запросов
Druid предлагает несколько сложных методов для создания сложных запросов для создания интересных приложений данных . К ним относятся различные способы нарезки и нарезки данных, при этом обеспечивая невероятную производительность запросов.
Хотя их подробное обсуждение выходит за рамки этого руководства, давайте обсудим некоторые важные из них, такие как соединения и поиск, мультиарендность и кэширование запросов .
Druid поддерживает два способа объединения данных. Первый — это операторы соединения, а второй — поиск во время запроса. Однако для повышения производительности запросов рекомендуется избегать соединений во время запроса.
Мультиарендность относится к функции поддержки нескольких арендаторов в одной и той же инфраструктуре Druid, при этом предлагая им логическую изоляцию. Этого можно добиться в Druid с помощью отдельных источников данных для каждого арендатора или разделения данных арендатором.
И, наконец, кэширование запросов является ключом к производительности в приложениях, интенсивно использующих данные. Druid поддерживает кэширование результатов запросов на уровне сегментов и результатов запросов. Кроме того, данные кэша могут находиться в памяти или во внешнем постоянном хранилище.
7. Языковые привязки
Хотя Druid отлично поддерживает создание спецификаций приема и определение запросов в JSON, иногда определение этих запросов в JSON может быть утомительным , особенно когда запросы становятся сложными. К сожалению, Druid не предлагает клиентскую библиотеку на каком-либо конкретном языке, чтобы помочь нам в этом отношении. Но существует довольно много языковых привязок, разработанных сообществом . Одна такая клиентская библиотека также доступна для Java.
Мы быстро увидим, как мы можем построить запрос TopN , который мы использовали ранее, используя эту клиентскую библиотеку на Java.
Начнем с определения необходимой зависимости в Maven :
<dependency>
<groupId>in.zapr.druid</groupId>
<artifactId>druidry</artifactId>
<version>2.14</version>
</dependency>
После этого мы сможем использовать клиентскую библиотеку и создать наш запрос TopN :
DateTime startTime = new DateTime(2015, 9, 12, 0, 0, 0, DateTimeZone.UTC);
DateTime endTime = new DateTime(2015, 9, 13, 0, 0, 0, DateTimeZone.UTC);
Interval interval = new Interval(startTime, endTime);
Granularity granularity = new SimpleGranularity(PredefinedGranularity.ALL);
DruidDimension dimension = new SimpleDimension("page");
TopNMetric metric = new SimpleMetric("count");
DruidTopNQuery query = DruidTopNQuery.builder()
.dataSource("wikipedia")
.dimension(dimension)
.threshold(10)
.topNMetric(metric)
.granularity(granularity)
.filter(filter)
.aggregators(Arrays.asList(new LongSumAggregator("count", "count")))
.intervals(Collections.singletonList(interval)).build();
После этого мы можем просто сгенерировать необходимую структуру JSON, которую мы можем использовать в вызове HTTP POST:
ObjectMapper mapper = new ObjectMapper();
String requiredJson = mapper.writeValueAsString(query);
8. Заключение
В этом руководстве мы рассмотрели основы данных событий и архитектуры Apache Druid.
Далее мы настраиваем первичный кластер Druid, используя контейнеры Docker на нашей локальной машине. Затем мы также прошли процесс загрузки образца набора данных в Druid с помощью собственной пакетной задачи. После этого мы увидели различные способы запроса наших данных в Druid. Наконец, мы просмотрели клиентскую библиотеку на Java для построения запросов Druid.
Мы только что коснулись возможностей, которые может предложить Друид. Есть несколько возможностей, в которых Druid может помочь нам построить наш конвейер данных и создать приложения данных. Расширенные функции приема и запроса — очевидные следующие шаги для эффективного использования возможностей Druid.
Кроме того, создание подходящего кластера Druid, который масштабирует отдельные процессы в соответствии с потребностями, должно быть целью для максимизации преимуществ.