1. Обзор
В этом руководстве мы углубимся в область моделирования данных для управляемой событиями архитектуры с использованием Apache Kafka .
2. Настройка
Кластер Kafka состоит из нескольких брокеров Kafka, зарегистрированных в кластере Zookeeper. Для простоты мы будем использовать готовые образы Docker и конфигурации для составления докеров, опубликованные Confluent .
Во-первых, давайте загрузим docker-compose.yml для кластера Kafka с 3 узлами:
$ BASE_URL="https://raw.githubusercontent.com/confluentinc/cp-docker-images/5.3.3-post/examples/kafka-cluster"
$ curl -Os "$BASE_URL"/docker-compose.yml
Далее давайте раскрутим узлы брокера Zookeeper и Kafka:
$ docker-compose up -d
Наконец, мы можем убедиться, что все брокеры Kafka работают:
$ docker-compose logs kafka-1 kafka-2 kafka-3 | grep started
kafka-1_1 | [2020-12-27 10:15:03,783] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
kafka-2_1 | [2020-12-27 10:15:04,134] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
kafka-3_1 | [2020-12-27 10:15:03,853] INFO [KafkaServer id=3] started (kafka.server.KafkaServer)
3. Основы мероприятия
Прежде чем мы приступим к моделированию данных для систем, управляемых событиями, нам нужно понять несколько понятий, таких как события, поток событий, производитель-потребитель и тема.
3.1. Мероприятие
Событие в мире Кафки — это журнал информации о том, что произошло в доменном мире. Он делает это, записывая информацию в виде сообщения пары ключ-значение вместе с несколькими другими атрибутами, такими как метка времени, метаинформация и заголовки.
Предположим, что мы моделируем игру в шахматы; тогда событие может быть ходом:
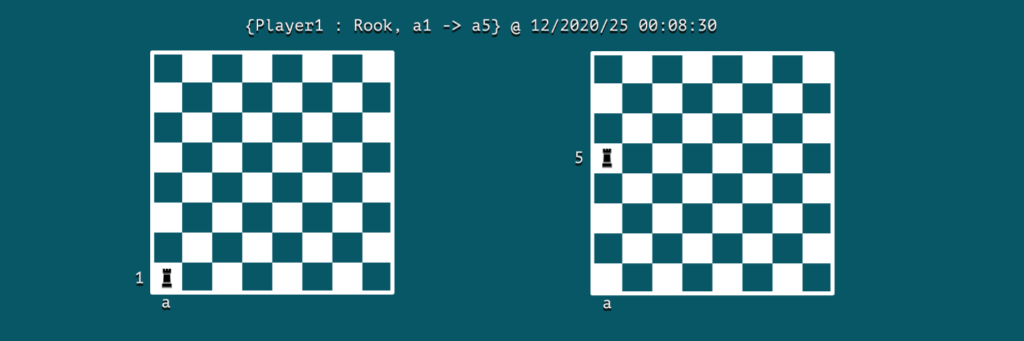
Мы можем заметить, что событие содержит ключевую информацию об актере, действии и времени его возникновения . В данном случае игрок Player1 является действующим лицом, а действие заключается в перемещении ладьи из клетки a1 в a5 в 2020/25 00:08:30 .
3.2. Поток сообщений
Apache Kafka — это система обработки потоков, которая фиксирует события в виде потока сообщений. В нашей игре в шахматы мы можем думать о потоке событий как о журнале ходов, сыгранных игроками.
При возникновении каждого события моментальный снимок платы будет отображать ее состояние. Обычно для хранения последнего статического состояния объекта используется традиционная схема таблицы.
С другой стороны, поток событий может помочь нам зафиксировать динамическое изменение между двумя последовательными состояниями в виде событий. Если мы воспроизведем серию этих неизменяемых событий, мы сможем перейти из одного состояния в другое. Такова связь между потоком событий и традиционной таблицей, часто известная как двойственность таблицы потоков .
Давайте визуализируем поток событий на шахматной доске всего с двумя последовательными событиями:
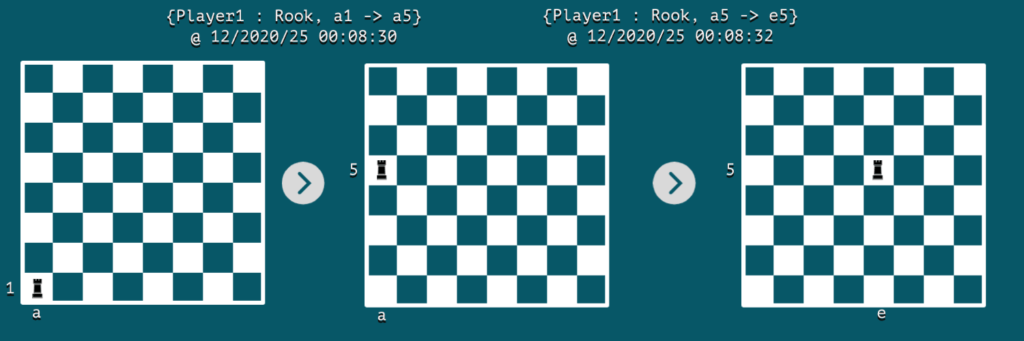
4. Темы
В этом разделе мы узнаем, как классифицировать сообщения, направляемые через Apache Kafka.
4.1. Категоризация
В системе обмена сообщениями, такой как Apache Kafka, все, что создает событие, обычно называется производителем. В то время как те, кто читает и потребляет эти сообщения, называются потребителями.
В реальном сценарии каждый производитель может генерировать события разных типов, поэтому потребители будут напрасно тратить усилия, если мы ожидаем, что они будут фильтровать сообщения, относящиеся к ним, и игнорировать остальные.
Чтобы решить эту основную проблему, Apache Kafka использует топики, которые по сути представляют собой группы сообщений, которые принадлежат друг другу . В результате потребители могут быть более продуктивными при использовании сообщений о событиях.
В нашем примере с шахматной доской тема может использоваться для группировки всех ходов в теме шахматных ходов :
$ docker run \
--net=host --rm confluentinc/cp-kafka:5.0.0 \
kafka-topics --create --topic chess-moves \
--if-not-exists \
--partitions 1 --replication-factor 1 \
--zookeeper localhost:32181
Created topic "chess-moves".
4.2. Производитель-Потребитель
Теперь давайте посмотрим, как производители и потребители используют темы Kafka для обработки сообщений. Мы будем использовать утилиты kafka-console-producer и kafka-console-consumer, поставляемые с дистрибутивом Kafka, чтобы продемонстрировать это.
Давайте запустим контейнер с именем kafka-producer , в котором мы вызовем утилиту производителя:
$ docker run \
--net=host \
--name=kafka-producer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
Одновременно мы можем запустить контейнер с именем kafka-consumer , в котором мы будем вызывать потребительскую утилиту:
$ docker run \
--net=host \
--name=kafka-consumer \
-it --rm \
confluentinc/cp-kafka:5.0.0 /bin/bash
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true --property key.separator=:
Теперь давайте запишем некоторые ходы игры через продюсера:
>{Player1 : Rook, a1->a5}
Поскольку потребитель активен, он получит это сообщение с ключом Player1 :
{Player1 : Rook, a1->a5}
5. Перегородки
Далее давайте посмотрим, как мы можем создать дополнительную категоризацию сообщений с помощью разделов и повысить производительность всей системы.
5.1. параллелизм
Мы можем разделить тему на несколько разделов и вызвать несколько потребителей для получения сообщений из разных разделов . Включив такое поведение параллелизма, общая производительность системы может быть улучшена.
По умолчанию версии Kafka, которые поддерживают параметр –bootstrap-server во время создания темы, создают один раздел темы, если это явно не указано во время создания темы. Однако для уже существующей темы мы можем увеличить количество разделов. Давайте установим номер раздела равным 3 для темы шахматных ходов :
$ docker run \
--net=host \
--rm confluentinc/cp-kafka:5.0.0 \
bash -c "kafka-topics --alter --zookeeper localhost:32181 --topic chess-moves --partitions 3"
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
5.2. Ключ раздела
В теме Kafka обрабатывает сообщения в нескольких разделах, используя ключ раздела. С одной стороны, производители неявно используют его для маршрутизации сообщения в один из разделов. С другой стороны, каждый потребитель может читать сообщения из определенного раздела.
По умолчанию производитель генерирует хеш-значение ключа, за которым следует модуль с количеством разделов . Затем он отправлял сообщение в раздел, идентифицированный вычисленным идентификатором.
Давайте создадим новые сообщения о событиях с помощью утилиты kafka-console-producer , но на этот раз мы будем записывать ходы обоих игроков:
# kafka-console-producer --broker-list localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves \
--property parse.key=true --property key.separator=:
>{Player1: Rook, a1 -> a5}
>{Player2: Bishop, g3 -> h4}
>{Player1: Rook, a5 -> e5}
>{Player2: Bishop, h4 -> g3}
Теперь у нас может быть два потребителя, один читающий из раздела-1, а другой читающий из раздела-2:
# kafka-console-consumer --bootstrap-server localhost:19092,localhost:29092,localhost:39092 \
--topic chess-moves --from-beginning \
--property print.key=true --property print.value=true \
--property key.separator=: \
--partition 1
{Player2: Bishop, g3 -> h4}
{Player2: Bishop, h4 -> g3}
Мы видим, что все ходы Игрока2 записываются в раздел-1. Таким же образом мы можем проверить, что ходы Игрока 1 записываются в раздел-0.
6. Масштабирование
То, как мы концептуализируем темы и разделы, имеет решающее значение для горизонтального масштабирования. С одной стороны, тема — это скорее предопределенная категоризация данных . С другой стороны, раздел — это динамическая категоризация данных, которая происходит «на лету».
Кроме того, существуют практические ограничения на количество разделов, которые мы можем настроить в теме. Это связано с тем, что каждый раздел сопоставляется с каталогом в файловой системе узла брокера. Когда мы увеличиваем количество разделов, мы также увеличиваем количество дескрипторов открытых файлов в нашей операционной системе.
Как правило, эксперты Confluent рекомендуют ограничивать количество разделов на брокера до 100 x b x r , где b — количество брокеров в кластере Kafka, а r — коэффициент репликации.
7. Заключение
В этой статье мы использовали среду Docker, чтобы осветить основы моделирования данных для системы, использующей Apache Kafka для обработки сообщений. Имея базовое представление о событиях, темах и разделах, мы теперь готовы концептуализировать потоковую передачу событий и далее использовать эту архитектурную парадигму.