1. Введение
В этом руководстве мы собираемся интегрировать BIRT (инструменты бизнес-аналитики и отчетности) с Spring Boot MVC для предоставления статических и динамических отчетов в формате HTML и PDF.
2. Что такое BIRT ?
BIRT — это механизм с открытым исходным кодом для создания визуализаций данных , которые можно интегрировать в веб-приложения Java.
Это программный проект высшего уровня в рамках Eclipse Foundation, в котором используются вклады IBM и Innovent Solutions. Он был запущен и спонсируется компанией Actuate в конце 2004 года.
Фреймворк позволяет создавать отчеты, интегрированные с широким спектром источников данных.
3. Зависимости Maven
BIRT состоит из двух основных компонентов: визуального конструктора отчетов для создания файлов макетов отчетов и компонента среды выполнения для интерпретации и визуализации этих макетов.
В нашем примере веб-приложения мы будем использовать оба поверх Spring Boot.
3.1. Зависимости платформы BIRT
Поскольку мы привыкли думать с точки зрения управления зависимостями, первым выбором будет поиск BIRT в Maven Central.
Тем не менее, последняя доступная официальная версия базовой библиотеки — 4.6 от 2016 года, а на странице загрузки Eclipse мы можем найти ссылки как минимум на две более новые версии ( текущая — 4.8 ).
Если мы выбираем официальную сборку, самый простой способ запустить код — это загрузить пакет BIRT Report Engine , который представляет собой полноценное веб-приложение, которое также полезно для обучения. Затем нам нужно скопировать его папку lib в наш проект (размером около 68 МБ) и указать IDE включить в нее все файлы jar.
Само собой разумеется, что при таком подходе мы сможем компилировать только через IDE , так как Maven не найдет эти jar-файлы, если мы не настроим и не установим их вручную (более 100 файлов!) в нашем локальном репозитории.
К счастью, Innovent Solutions решила взять дело в свои руки и опубликовала на Maven Central свои собственные сборки последних зависимостей BIRT, и это здорово, поскольку она управляет всеми необходимыми зависимостями за нас.
Читая комментарии на интернет-форумах, неясно, готовы ли эти артефакты к производству, но Innovent Solutions с самого начала работала над проектом вместе с командой Eclipse, поэтому наш проект опирается на них.
Включить BIRT теперь очень просто:
<dependency>
<groupId>com.innoventsolutions.birt.runtime</groupId>
<artifactId>org.eclipse.birt.runtime_4.8.0-20180626</artifactId>
<version>4.8.0</version>
</dependency>
3.2. Зависимости Spring Boot
Теперь, когда BIRT импортирован в наш проект, нам просто нужно добавить стандартные зависимости Spring Boot в наш файл pom.
Однако есть одна ловушка, потому что jar BIRT содержит собственную реализацию Slf4J , которая плохо работает с Logback и выдает конфликтное исключение во время запуска.
Поскольку мы не можем удалить его из банки, чтобы решить эту проблему, нам нужно исключить Logback :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
</exclusions>
</dependency>
Теперь мы, наконец, готовы начать!
4. Отчеты БИРТ
В среде BIRT отчет представляет собой длинный XML-файл конфигурации , идентифицируемый расширением rptdesign .
Он сообщает движку, что рисовать и где , от стиля заголовка до необходимых свойств для подключения к источнику данных.
Для базового динамического отчета нам нужно настроить три вещи:
- источник данных (в нашем примере мы используем локальный файл CSV, но это может быть таблица базы данных)
- элементы, которые мы хотим отобразить (диаграммы, таблицы и т. д.)
- дизайн страницы
Отчет структурирован как HTML-страница с верхним, основным и нижним колонтитулами, сценариями и стилями.
Платформа предоставляет обширный набор готовых компонентов на выбор , включая интеграцию с основными источниками данных, макетами, диаграммами и таблицами. И мы можем расширить его, добавив свои собственные!
Существует два способа создания файла отчета: визуальный или программный.
5. Дизайнер отчетов Eclipse
Чтобы упростить создание отчетов, команда Eclipse создала подключаемый модуль инструмента разработки отчетов для своей популярной среды IDE.
Этот инструмент имеет простой интерфейс перетаскивания из палитры слева, который автоматически открывает окно настройки для нового компонента, который мы добавляем на страницу. Мы также можем увидеть все настройки, доступные для каждого компонента, щелкнув его на странице, а затем нажав кнопку « Редактор свойств» (выделена на изображении ниже).
Чтобы визуализировать всю структуру страницы в виде дерева, нам просто нужно нажать кнопку Outline .
Вкладка Data Explorer также содержит источники данных, определенные для нашего отчета:
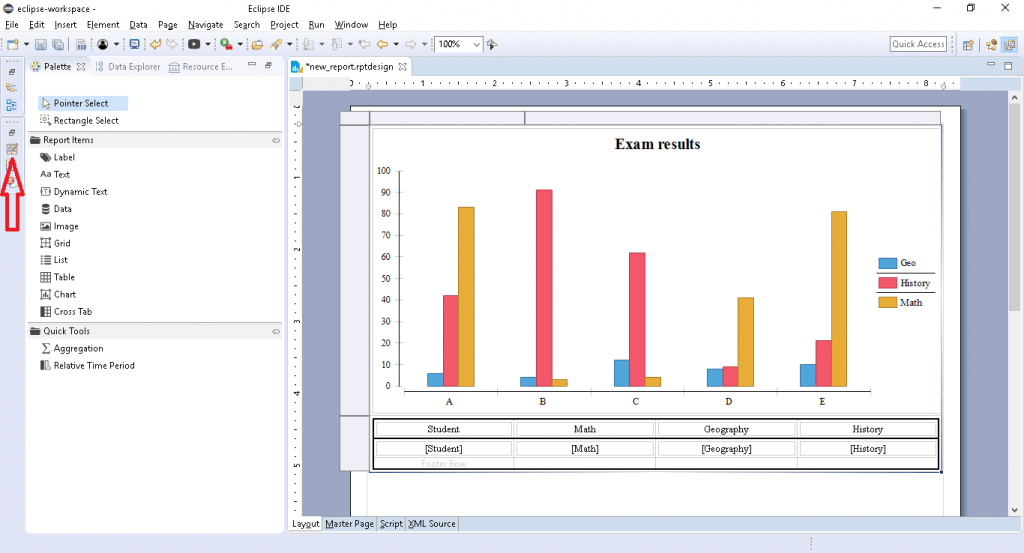
Образец отчета, показанный на изображении, можно найти по пути <project_root>/reports/csv_data_report.rptdesign.
Еще одним преимуществом использования визуального дизайнера является онлайн-документация, в которой больше внимания уделяется этому инструменту, а не программному подходу.
Если мы уже используем Eclipse, нам просто нужно установить подключаемый модуль BIRT Report Design , который включает предопределенную перспективу и визуальный редактор.
Для тех разработчиков, которые в настоящее время не используют Eclipse и не хотят переключаться, существует пакет Eclipse Report Designer , который состоит из переносимой установки Eclipse с предустановленным подключаемым модулем BIRT.
Как только файл отчета будет завершен, мы можем сохранить его в нашем проекте и вернуться к написанию кода в предпочитаемой нами среде.
6. Программный подход
Мы также можем разработать отчет, используя только код , но этот подход намного сложнее из-за скудной доступной документации, поэтому будьте готовы копаться в исходном коде и онлайн-форумах.
Также стоит учитывать, что со всеми утомительными деталями дизайна , такими как размер, длина и положение сетки , намного проще справиться с помощью конструктора .
Чтобы доказать это, вот пример того, как определить простую статическую страницу с изображением и текстом:
DesignElementHandle element = factory.newSimpleMasterPage("Page Master");
design.getMasterPages().add(element);
GridHandle grid = factory.newGridItem(null, 2, 1);
design.getBody().add(grid);
grid.setWidth("100%");
RowHandle row0 = (RowHandle) grid.getRows().get(0);
ImageHandle image = factory.newImage(null);
CellHandle cell = (CellHandle) row0.getCells().get(0);
cell.getContent().add(image);
image.setURL("\"https://www.foreach.com/wp-content/themes/foreach/favicon/favicon-96x96.png\"");
LabelHandle label = factory.newLabel(null);
cell = (CellHandle) row0.getCells().get(1);
cell.getContent().add(label);
label.setText("Hello, ForEach world!");
Этот код сгенерирует простой (и уродливый) отчет:

Образец отчета, показанный на изображении выше, можно найти по этому пути: <project_root>/reports/static_report.rptdesign.
После того как мы определили, как должен выглядеть отчет и какие данные он должен отображать, мы можем сгенерировать файл XML, запустив наш класс ReportDesignApplication .
7. Присоединение источника данных
Ранее мы упоминали, что BIRT поддерживает множество различных источников данных.
Для нашего примерного проекта мы использовали простой файл CSV с тремя записями. Его можно найти в папке отчетов, он состоит из трех простых строк данных и заголовков:
Student, Math, Geography, History
Bill, 10,3,8
Tom, 5,6,5
Anne, 7, 4,9
7.1. Настройка источника данных
Чтобы позволить BIRT использовать наш файл (или любой другой тип источника), мы должны настроить источник данных .
Для нашего файла мы создали источник данных Flat File с помощью дизайнера отчетов всего за несколько шагов:
- Откройте перспективу дизайнера и посмотрите на
схемусправа. - Щелкните правой кнопкой мыши значок «
Источники данных» . - Выберите желаемый тип источника (в нашем случае источник плоского файла).
- Теперь мы можем выбрать загрузку всей папки или только одного файла. Мы использовали второй вариант (если наш файл данных в формате CSV, мы хотим использовать первую строку в качестве индикатора имени столбца).
- Проверьте соединение, чтобы убедиться, что путь указан правильно.
Мы приложили несколько фотографий, чтобы показать каждый шаг:




7.2. Набор данных
Источник данных готов, но нам все еще нужно определить наш набор данных , который представляет собой фактические данные, отображаемые в нашем отчете:
- Откройте перспективу дизайнера и посмотрите на
схемусправа. - Щелкните правой кнопкой мыши значок «
Наборы данных» . - Выберите нужный
источник данныхи тип (в нашем случае только один тип). - Следующий экран зависит от типа источника данных и выбранного набора данных: в нашем случае мы видим страницу, на которой мы можем выбрать столбцы для включения.
- После завершения настройки мы можем открыть конфигурацию в любое время, дважды щелкнув наш набор данных.
- В
Output Columnsмы можем установить правильный тип отображаемых данных. - Затем мы можем просмотреть предварительный просмотр, щелкнув
результаты предварительного просмотра.
Опять же, несколько фотографий, чтобы прояснить эти шаги:




7.3. Другие типы источников данных
Как упоминалось в шаге 4 настройки набора данных , доступные параметры могут меняться в зависимости от источника данных .
Для нашего CSV-файла BIRT предоставляет параметры, связанные с тем, какие столбцы отображать, тип данных и необходимость загрузки всего файла. С другой стороны, если бы у нас был источник данных JDBC, нам, возможно, пришлось бы написать SQL-запрос или хранимую процедуру.
В меню « Наборы данных » мы также можем объединить два или более набора данных в новый набор данных .
8. Визуализация отчета
Как только файл отчета будет готов, мы должны передать его движку для рендеринга. Для этого нужно реализовать несколько вещей.
8.1. Инициализация двигателя
Класс ReportEngine , который интерпретирует файлы проекта и создает окончательный результат, является частью библиотеки времени выполнения BIRT.
Он использует кучу помощников и задач для выполнения работы, что делает его довольно ресурсоемким:
![]()
Источник изображения: документация Eclipse BIRT.
Создание экземпляра движка сопряжено со значительными затратами , главным образом из-за стоимости загрузки расширений. Поэтому мы должны создать только один экземпляр ReportEngine и использовать его для запуска нескольких отчетов .
Механизм отчетов создается с помощью фабрики, предоставляемой платформой . Перед созданием движка мы должны запустить Платформу , которая загрузит соответствующие плагины:
@PostConstruct
protected void initialize() throws BirtException {
EngineConfig config = new EngineConfig();
config.getAppContext().put("spring", this.context);
Platform.startup(config);
IReportEngineFactory factory = (IReportEngineFactory) Platform
.createFactoryObject(IReportEngineFactory.EXTENSION_REPORT_ENGINE_FACTORY);
birtEngine = factory.createReportEngine(config);
imageFolder = System.getProperty("user.dir") + File.separatorChar + reportsPath + imagesPath;
loadReports();
}
Когда он нам больше не нужен, мы можем его уничтожить:
@Override
public void destroy() {
birtEngine.destroy();
Platform.shutdown();
}
8.2. Реализация выходного формата
BIRT уже поддерживает несколько выходных форматов: HTML, PDF, PPT и ODT , и это лишь некоторые из них.
Для примера проекта мы реализовали два из них с помощью методов generatePDFReport и generateHTMLReport .
Они немного различаются в зависимости от конкретных необходимых свойств, таких как выходной формат и обработчики изображений.
Фактически, PDF-файлы встраивают изображения вместе с текстом, в то время как HTML-отчеты должны их генерировать и/или связывать.
Таким образом, функция рендеринга PDF довольно проста :
private void generatePDFReport(IReportRunnable report, HttpServletResponse response,
HttpServletRequest request) {
IRunAndRenderTask runAndRenderTask = birtEngine.createRunAndRenderTask(report);
response.setContentType(birtEngine.getMIMEType("pdf"));
IRenderOption options = new RenderOption();
PDFRenderOption pdfRenderOption = new PDFRenderOption(options);
pdfRenderOption.setOutputFormat("pdf");
runAndRenderTask.setRenderOption(pdfRenderOption);
runAndRenderTask.getAppContext().put(EngineConstants.APPCONTEXT_PDF_RENDER_CONTEXT, request);
try {
pdfRenderOption.setOutputStream(response.getOutputStream());
runAndRenderTask.run();
} catch (Exception e) {
throw new RuntimeException(e.getMessage(), e);
} finally {
runAndRenderTask.close();
}
}
В то время как функция рендеринга HTML требует дополнительных настроек:
private void generateHTMLReport(IReportRunnable report, HttpServletResponse response,
HttpServletRequest request) {
IRunAndRenderTask runAndRenderTask = birtEngine.createRunAndRenderTask(report);
response.setContentType(birtEngine.getMIMEType("html"));
IRenderOption options = new RenderOption();
HTMLRenderOption htmlOptions = new HTMLRenderOption(options);
htmlOptions.setOutputFormat("html");
htmlOptions.setBaseImageURL("/" + reportsPath + imagesPath);
htmlOptions.setImageDirectory(imageFolder);
htmlOptions.setImageHandler(htmlImageHandler);
runAndRenderTask.setRenderOption(htmlOptions);
runAndRenderTask.getAppContext().put(
EngineConstants.APPCONTEXT_BIRT_VIEWER_HTTPSERVET_REQUEST, request);
try {
htmlOptions.setOutputStream(response.getOutputStream());
runAndRenderTask.run();
} catch (Exception e) {
throw new RuntimeException(e.getMessage(), e);
} finally {
runAndRenderTask.close();
}
}
Самое примечательное, что мы установили HTMLServerImageHandler вместо того, чтобы оставить обработчик по умолчанию. Эта небольшая разница сильно влияет на сгенерированный тег img :
- обработчик по умолчанию связывает тег
imgс путем к файловой системе , заблокированным в целях безопасности многими браузерами. - HTMLServerImageHandler
ссылаетсяна URL-адрес сервера
С помощью метода setImageDirectory мы указываем, куда движок будет сохранять сгенерированный файл изображения.
По умолчанию обработчик генерирует новый файл при каждом запросе, поэтому мы можем добавить слой кэширования или политику удаления .
8.3. Публикация изображений
В случае отчета HTML файлы изображений являются внешними, поэтому они должны быть доступны на пути к серверу.
В приведенном выше коде с помощью метода setBaseImageURL мы сообщаем движку, какой относительный путь следует использовать в ссылке тега img , поэтому нам нужно убедиться, что путь действительно доступен!
По этой причине в нашем ReportEngineApplication мы настроили Spring для публикации папки с изображениями :
@SpringBootApplication
@EnableWebMvc
public class ReportEngineApplication implements WebMvcConfigurer {
@Value("${reports.relative.path}")
private String reportsPath;
@Value("${images.relative.path}")
private String imagesPath;
...
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry
.addResourceHandler(reportsPath + imagesPath + "/**")
.addResourceLocations("file:///" + System.getProperty("user.dir") + "/"
+ reportsPath + imagesPath);
}
}
Какой бы путь мы ни выбрали, мы должны убедиться, что здесь и в htmlOptions предыдущего фрагмента используется один и тот же путь, иначе наш отчет не сможет отображать изображения.
9. Отображение отчета
Последний компонент, необходимый для подготовки нашего приложения, — это контроллер , возвращающий отрендеренный результат:
@RequestMapping(method = RequestMethod.GET, value = "/report/{name}")
@ResponseBody
public void generateFullReport(HttpServletResponse response, HttpServletRequest request,
@PathVariable("name") String name, @RequestParam("output") String output)
throws EngineException, IOException {
OutputType format = OutputType.from(output);
reportService.generateMainReport(name, format, response, request);
}
С выходным параметром мы можем позволить пользователю выбрать желаемый формат — HTML или PDF.
10. Тестирование отчета
Мы можем запустить приложение, запустив класс ReportEngineApplication .
Во время запуска класс BirtReportService загрузит все отчеты, найденные в папке <project_root>/reports .
Чтобы увидеть наши отчеты в действии, нам просто нужно указать в нашем браузере:
- /отчет/csv_data_report?output=pdf
- /отчет/csv_data_report?output=html
- /отчет/статический_отчет?выход=pdf
- /отчет/статический_отчет?output=html
Вот как выглядит отчет csv_data_report :

Чтобы перезагрузить отчет после изменения файла дизайна, мы просто указываем в нашем браузере /report/reload.
11. Заключение
В этой статье мы интегрировали BIRT со Spring Boot, исследуя подводные камни и проблемы, а также его мощность и гибкость.
Исходный код статьи доступен на GitHub .