1. Введение
В этом уроке мы подробно рассмотрим архитектуру Cassandra. Мы узнаем о хранении данных в распределенной архитектуре и обсудим основные компоненты архитектуры.
2. Обзор Кассандры
Apache Cassandra — это распределенная система управления базами данных NoSQL. Основное преимущество Cassandra заключается в том, что она может обрабатывать большие объемы структурированных данных на обычных серверах. Кроме того, он обеспечивает высокую доступность и отсутствие единой точки отказа. Cassandra достигает этого, используя архитектуру кольцевого типа, где наименьшая логическая единица — это узел. Он использует секционирование данных для оптимизации запросов.
Каждый фрагмент данных имеет ключ раздела. Ключ раздела для каждой строки хэшируется. В результате мы получим уникальный токен для каждого фрагмента данных. Для каждого узла существует назначенный диапазон токенов. Следовательно, данные с одним и тем же токеном хранятся на одном узле. Кольцевая архитектура узлов показана ниже:
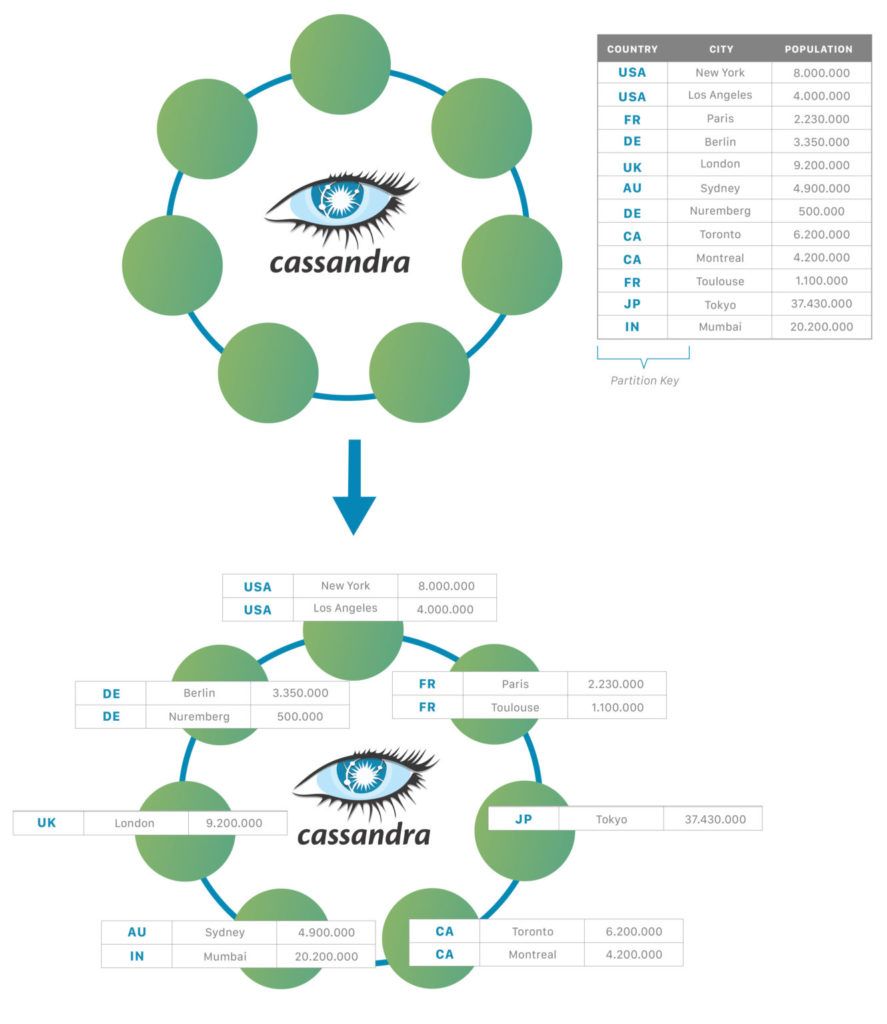
3. Компоненты Кассандры
3.1. Узел
Узел — это базовый компонент инфраструктуры Cassandra. Это полнофункциональная машина, которая соединяется с другими узлами в кластере через внутреннюю сеть высокого уровня.
Название этой сети — Gossip Protocol . Чтобы уточнить, машина может быть физическим сервером, экземпляром EC2 или виртуальной машиной. Все узлы организованы по топологии кольцевой сети. Важно отметить, что каждый узел независим и играет одну и ту же роль в кольце. Cassandra упорядочивает узлы в одноранговой структуре. Узел содержит фактические данные.
Каждый узел в кластере может принимать запросы на чтение и запись. Поэтому не имеет значения, где на самом деле находятся данные в кластере. Мы всегда будем получать самую новую версию данных.
3.2. Виртуальный узел
Более новые версии Cassandra используют виртуальные узлы или сокращенно vnodes . Виртуальный узел — это уровень хранения данных на сервере.
По умолчанию на сервер приходится 256 виртуальных узлов. Как мы обсуждали в предыдущем абзаце, каждому узлу назначается диапазон токенов. Каждый виртуальный узел использует поддиапазон токенов от узла, которому они принадлежат.
Эти виртуальные узлы обеспечивают большую гибкость системы. Следовательно, Cassandra проще добавлять новые узлы в кластер, когда они нам нужны. Когда наши данные имеют неравномерно распределенные токены между узлами, мы можем легко увеличить емкость хранилища, расширив виртуальные узлы до более загруженного узла.
3.4. Сервер
Когда мы используем термин сервер , мы имеем в виду машину с установленным программным обеспечением Cassandra. Каждый узел имеет один экземпляр Cassandra, который технически является сервером. Как мы уже говорили ранее, каждый экземпляр Cassandra содержит 256 виртуальных узлов. Сервер Cassandra запускает основные процессы. Например, такие процессы, как распространение реплик по узлам или маршрутизация запросов.
3.5. Стойка
Стойка Cassandra представляет собой логическую группу узлов внутри кольца . Другими словами, стойка — это набор серверов. База данных использует стойки, чтобы обеспечить распределение реплик по различным логическим группам. В результате он может отправлять операции не только одному узлу. Несколько узлов, каждый в отдельной стойке, могут обеспечить большую отказоустойчивость и доступность.
3.6. Центры обработки данных
Дата-центр — это логический набор стоек. Центр обработки данных должен содержать как минимум одну стойку. Можно сказать, что Cassandra Datacenter — это группа узлов, связанных и настроенных внутри кластера для целей репликации. Таким образом, это помогает уменьшить задержку, предотвратить влияние на транзакции других рабочих нагрузок и связанных с ними эффектов. Более того, коэффициент репликации также можно настроить для записи в несколько центров обработки данных. В результате Cassandra может обеспечить дополнительную гибкость в архитектурном проектировании и организации.
3.7. Кластер
Кластер — это компонент, который содержит один или несколько центров обработки данных. Это самый внешний контейнер хранения в базе данных. Одна база данных содержит один или несколько кластеров. Иерархия элементов в кластере Cassandra:
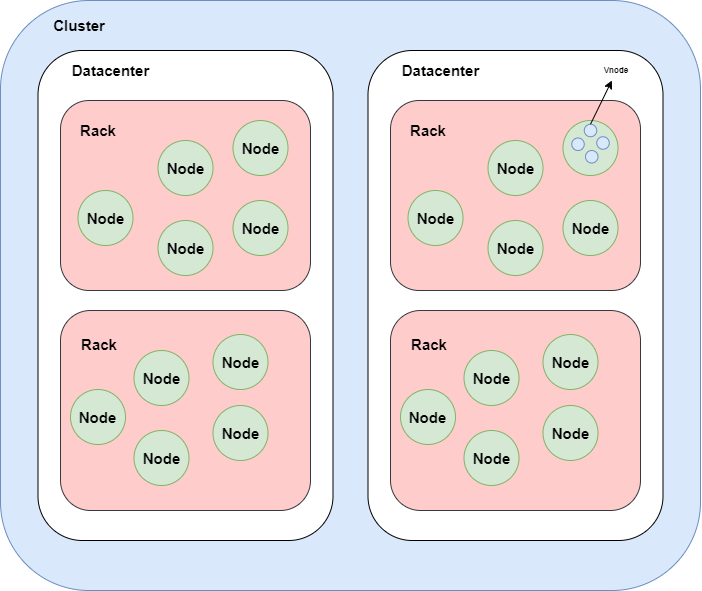
Во-первых, у нас есть кластеры, состоящие из центров обработки данных. Внутри центров обработки данных у нас есть узлы, которые по умолчанию содержат 256 виртуальных узлов.
4. Репликация данных
Теперь, когда мы знаем основные компоненты Cassandra. Давайте поговорим о том, как Cassandra управляет данными в своей структуре. Некоторые системы не могут допустить потери данных или прерывания доставки данных. Решение состоит в том, чтобы предоставить резервную копию, когда проблема возникла. Например, это могут быть аппаратные проблемы, или в любой момент в процессе обработки данных могут отсутствовать ссылки. Cassandra хранит реплики данных на нескольких узлах для обеспечения надежности и отказоустойчивости.
5.1. Фактор репликации
Мы можем определить количество реплик и их расположение по фактору репликации и стратегии репликации. Коэффициент репликации — это общее количество реплик в кластере . Когда мы устанавливаем этот коэффициент равным единице, это означает, что в кластере существует только одна копия каждой строки и так далее . Мы можем установить этот коэффициент на уровне центра обработки данных и на уровне стойки.
5.1. Стратегия репликации
Стратегия репликации определяет, как выбираются реплики . Важность реплик одинакова. У Cassandra есть две стратегии для определения того, какие узлы содержат реплицированные данные. Первый называется S impleStrategy, и он не знает логического разделения узлов на центры обработки данных и стойки. Второй вариант — NetworkTopologyStrategy — более сложный и учитывает как стойки, так и центры обработки данных. Мы можем определить, сколько реплик будет размещено в разных центрах обработки данных, используя NetworkTopologyStrategy . Кроме того, он пытается избежать ситуаций, когда две реплики размещаются в одной стойке.
5. Вывод
В этом руководстве представлены основные компоненты архитектуры Cassandra. Мы рассмотрели ключевые концепции этой базы данных, которые обеспечивают ее высокую доступность и устойчивость к секционированию. Мы также говорили о разделении данных и репликации данных.