1. Обзор
В этой статье мы узнаем, как Apache Cassandra разбивает и распределяет данные между узлами в кластере. Кроме того, мы увидим, как Cassandra хранит реплицированные данные на нескольких узлах для достижения высокой доступности.
2. Узел
В Cassandra один узел работает на сервере или виртуальной машине (ВМ) . Cassandra написана на языке Java, что означает, что запущенный экземпляр Cassandra является процессом виртуальной машины Java (JVM). Узел Cassandra может находиться в облаке, в локальном центре обработки данных или на любом диске. Для хранения данных, согласно рекомендации, мы должны использовать локальное хранилище или хранилище с прямым подключением, но не SAN.
Узел Cassandra отвечает за все данные, которые он хранит в виде распределенной хеш-таблицы. Cassandra предоставляет инструмент под названием nodetool для управления и проверки состояния узла или кластера.
3. Кольцо с жетонами
Cassandra сопоставляет каждый узел в кластере с одним или несколькими маркерами в форме непрерывного кольца . По умолчанию токен представляет собой 64-битное целое число. Поэтому возможный диапазон токенов от -2 ^63 до 2 ^63 -1. Он использует согласованный метод хеширования для сопоставления узлов с одним или несколькими токенами.
3.1. Один токен на узел
В случае с одним токеном на узел каждый узел отвечает за диапазон значений токенов, меньших или равных назначенному токену и больших, чем назначенный токен предыдущего узла. Для завершения кольца первый узел с наименьшим значением токена отвечает за диапазон значений, меньших или равных назначенному токену и больших, чем назначенный токен последнего узла с наивысшим значением токена.
При записи данных Cassandra использует хэш-функцию для вычисления значения токена из ключа раздела . Это значение токена сравнивается с диапазоном токенов для каждого узла, чтобы идентифицировать узел, которому принадлежат данные.
Давайте посмотрим на пример. На следующей диаграмме показан кластер из восьми узлов с коэффициентом репликации ( RF ), равным 3, и одним токеном, назначенным каждому узлу:
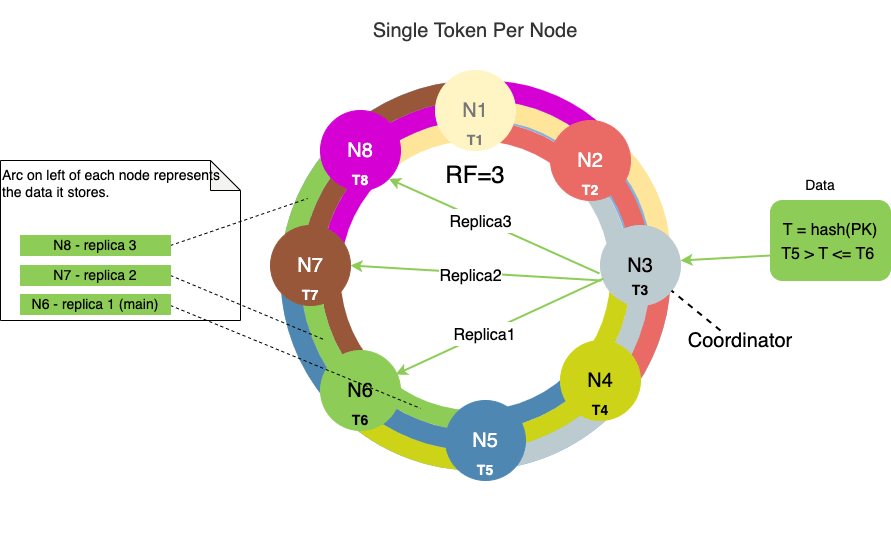
Кластер с RF=3 означает, что каждый узел имеет три реплики.
Самое внутреннее кольцо на приведенной выше диаграмме представляет основной диапазон токенов данных.
Недостатком использования одного токена на узел является несбалансированность токенов, создаваемых при добавлении узлов в кластер или удалении из него.
Предположим, что в хэш-кольце из N узлов каждый узел владеет равным количеством токенов, скажем, 100. Далее предположим, что существует существующий узел X, которому принадлежат диапазоны токенов от 100 до 200. Теперь, если мы добавим новый узел Y в слева от узла X, то этот новый узел Y теперь владеет половиной токенов узла X.
То есть теперь узел X будет владеть диапазоном токенов от 100 до 150, а узел Y будет владеть диапазоном токенов от 151 до 200. Часть данных с узла X необходимо переместить на узел Y. Это приводит к перемещению данных из одного узел X к другому узлу Y.
3.2. Несколько токенов на узел (vnodes)
Начиная с Cassandra 2.0, виртуальные узлы (vnodes) включены по умолчанию. В этом случае Cassandra разбивает диапазон токенов на более мелкие диапазоны и назначает несколько таких более мелких диапазонов каждому узлу в кластере. По умолчанию количество токенов для узла равно 256 — это задается в свойстве num_tokens в файле cassandra.yaml — это означает, что внутри узла имеется 256 vnodes.
Эта конфигурация упрощает обслуживание кластера Cassandra с машинами с различными вычислительными ресурсами. Это означает, что мы можем назначить больше виртуальных узлов машинам с большей вычислительной мощностью, установив для свойства num_tokens большее значение. С другой стороны, для машин с меньшей вычислительной мощностью мы можем установить num_tokens на меньшее число.
При использовании vnodes мы должны предварительно вычислить значения токенов. В противном случае мы должны предварительно вычислить значение токена для каждого узла и установить его равным значению свойства num_tokens .
Ниже приведена диаграмма, показывающая кластер из четырех узлов с двумя токенами, назначенными каждому узлу:
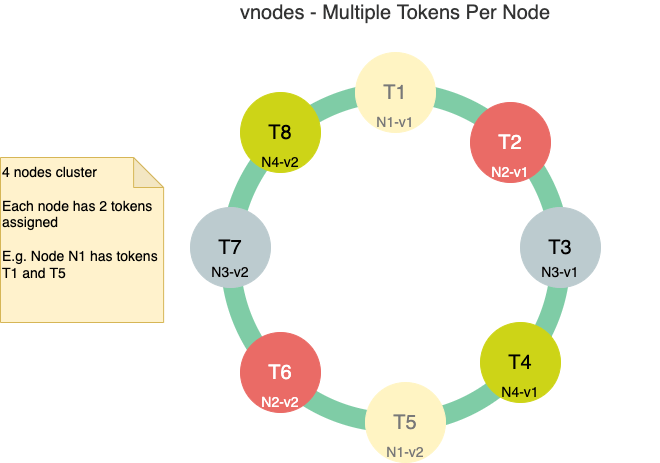
Преимущество этой настройки заключается в том, что при добавлении нового узла или удалении существующего узла происходит перераспределение данных между несколькими узлами .
Когда мы добавляем новый узел в хеш-кольцо, этот узел теперь будет владеть несколькими токенами. Эти диапазоны токенов ранее принадлежали нескольким узлам, поэтому перемещение данных после добавления происходит с нескольких узлов.
4. Разделители
Разделитель определяет, как данные распределяются по узлам в кластере Cassandra. По сути, разделитель — это хеш-функция для определения значения токена путем хэширования ключа раздела данных строки. Затем этот токен ключа секции используется для определения и распределения данных строки в кольце.
Cassandra предоставляет разные разделители, которые используют разные алгоритмы для вычисления хеш-значения ключа раздела. Мы можем предоставить и настроить собственный разделитель, реализуя интерфейс IPartitioner .
Murmur3Partitioner является разделителем по умолчанию, начиная с Cassandra версии 1.2. Он использует функцию MurmurHash , которая создает 64-битный хэш ключа раздела.
До Murmur3Partitioner у Cassandra по умолчанию был RandomPartitioner . Он использует алгоритм MD5 для хэширования ключей разделов.
И Murmur3Partitioner, и RandomPartitioner используют токены для равномерного распределения данных по кольцу. Однако основное различие между двумя разделителями заключается в том, что RandomPartitioner использует криптографическую хеш-функцию, а Murmur3Partitioner использует некриптографические хеш-функции. Как правило, криптографическая хеш-функция неэффективна и занимает больше времени.
5. Стратегии репликации
Cassandra обеспечивает высокую доступность и отказоустойчивость за счет репликации данных между узлами в кластере. Стратегия репликации определяет, где в кластере хранятся реплики.
Каждый узел в кластере владеет не только данными в пределах назначенного диапазона токенов, но и репликой для другого диапазона данных. Если основной узел выходит из строя, то этот узел-реплика может отвечать на запросы для этого диапазона данных.
Cassandra асинхронно реплицирует данные в фоновом режиме. А коэффициент репликации ( RF ) — это число, определяющее, сколько узлов получают копию одних и тех же данных в кластере. Например, три узла в кольце будут иметь копии одних и тех же данных с RF=3. Мы уже видели репликацию данных, показанную на схеме в разделе Token Ring.
Cassandra предоставляет подключаемые стратегии репликации, позволяя использовать различные реализации класса AbstractReplicationStrategy . Из коробки Cassandra предоставляет пару реализаций, SimpleStrategy и NetworkTopologyStrategy .
Как только разделитель вычисляет токен и помещает данные в основной узел, SimpleStrategy размещает реплики в последовательных узлах по кольцу.
С другой стороны, NetworkTopologyStrategy позволяет указать разные коэффициенты репликации для каждого центра обработки данных. В центре обработки данных он распределяет реплики по узлам в разных стойках, чтобы максимизировать доступность.
NetworkTopologyStrategy — это рекомендуемая стратегия для пространств ключей в производственных развертываниях , независимо от того, развертывается ли это один центр обработки данных или несколько центров обработки данных.
Стратегия репликации определяется независимо для каждого пространства ключей и является обязательной опцией при создании пространства ключей.
6. Уровень согласованности
Согласованность означает, что мы читаем те же самые данные, которые только что записали в распределенной системе. Cassandra обеспечивает настраиваемые уровни согласованности как для запросов на чтение, так и для запросов на запись . Другими словами, это дает нам тонкий компромисс между доступностью и согласованностью.
Более высокий уровень согласованности означает, что больше узлов должны отвечать на запросы чтения или записи. Таким образом, чаще всего Cassandra считывает те же данные, которые были записаны минуту назад.
Для запросов на чтение уровень согласованности указывает, сколько реплик должно ответить, прежде чем данные будут возвращены клиенту. Для запросов на запись уровень согласованности указывает, сколько реплик должно подтвердить запись перед отправкой успешного сообщения клиенту.
Поскольку Cassandra является в конечном счете непротиворечивой системой, RF гарантирует, что операция записи на остальные узлы будет выполняться асинхронно в фоновом режиме.
7. Снитч
Снитч предоставляет информацию о топологии сети, чтобы Cassandra могла эффективно маршрутизировать запрос на чтение/запись . Снитч определяет, какой узел к какому ЦОД и какой стойке относится. Он также определяет относительную близость хостов узлов в кластере.
Стратегии репликации используют эту информацию для размещения реплик на соответствующих узлах в кластерах в одном или нескольких центрах обработки данных.
8. Заключение
В этой статье мы узнали об общих понятиях, таких как узлы, кольца и токены в Cassandra. Кроме того, мы узнали, как Cassandra разделяет и реплицирует данные между узлами в кластере. Эти концепции описывают, как Cassandra использует различные стратегии для эффективной записи и чтения данных.
Это несколько компонентов архитектуры, которые делают Cassandra масштабируемой, доступной, надежной и управляемой.