1. Обзор
В этом руководстве мы обсудим, как использовать вторичные индексы в Apache Cassandra .
Мы увидим, как данные распределяются в базе данных, и изучим все типы индексов. Наконец, мы обсудим некоторые передовые практики и рекомендации по использованию вторичных индексов.
2. Архитектура Кассандры
Cassandra — это распределенная база данных NoSQL с полностью децентрализованной моделью связи.
Он состоит из нескольких узлов с одинаковыми обязанностями, что обеспечивает высокую доступность. Он может работать на любом облачном провайдере и локально, что делает его независимым от облака.
Мы также можем развернуть один кластер Cassandra одновременно на нескольких облачных платформах. Он больше всего подходит для запросов OLTP (онлайн-обработка транзакций), где скорость ответа имеет решающее значение, с простыми запросами, которые редко меняются.
2.1. Первичный ключ
Первичный ключ является наиболее важным элементом моделирования данных, который однозначно идентифицирует запись данных . Он состоит как минимум из одного ключа раздела и нуля или более столбцов кластеризации.
Ключ раздела определяет, как мы разделяем данные по кластеру. Столбец кластеризации упорядочивает данные на диске, чтобы обеспечить быстрое чтение.
Давайте посмотрим на пример:
CREATE TABLE company (
company_name text,
employee_name text,
employee_email text,
employee_age int,
PRIMARY KEY ((company_name), employee_email)
);
Здесь мы определили company_name как ключ раздела, используемый для равномерного распределения данных таблицы по узлам. Далее, поскольку мы указали employee_email в качестве столбца кластеризации, Cassandra использует его для хранения данных в порядке возрастания на каждом узле для эффективного извлечения строк.
2.2. Топология кластера
Cassandra предлагает линейную масштабируемость и производительность, прямо пропорциональную количеству доступных узлов .
Узлы размещаются в кольцо, образуя центр обработки данных, и, соединяя несколько территориально распределенных центров обработки данных, мы создаем кластер.
Cassandra автоматически разделяет данные без ручного вмешательства, что делает их готовыми к работе с большими данными.
Далее давайте посмотрим, как Cassandra разбивает нашу таблицу по company_name :
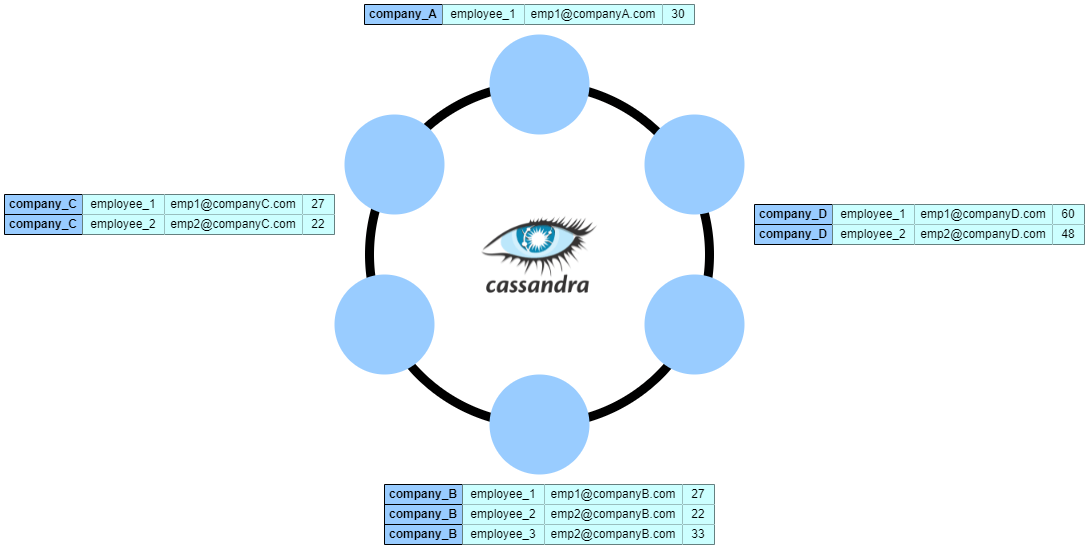
Как мы видим, таблица company разбита на секции с помощью ключа секции company_name и распределена по узлам. Мы можем заметить, что Cassandra группирует строки с одинаковым значением company_name и сохраняет их в одном и том же физическом разделе на диске. В результате мы можем считывать все данные для данной компании с минимальными затратами на ввод-вывод.
Кроме того, мы можем реплицировать данные в центре обработки данных, определив коэффициент репликации. При коэффициенте репликации N каждая строка данных будет храниться на N разных узлах кластера.
Мы можем указать количество реплик на уровне центра обработки данных, а не на уровне кластера. В результате у нас может быть кластер из нескольких центров обработки данных, каждый из которых имеет свой коэффициент репликации.
3. Запрос по непервичному ключу
Давайте возьмем таблицу компаний , которую мы определили ранее, и попробуем выполнить поиск по employee_age :
SELECT * FROM company WHERE employee_age = 30;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"
Мы получаем это сообщение об ошибке, потому что мы не можем запросить столбец, который не является частью первичного ключа, если мы не используем предложение ALLOW FILTERING .
Однако, даже если мы технически можем, мы не должны использовать его в продакшене, потому что ALLOW FILTERING требует больших затрат времени и денег . Это связано с тем, что в фоновом режиме он запускает сканирование всей таблицы на всех узлах в кластере для получения результатов, что отрицательно сказывается на производительности.
Тем не менее, один из приемлемых вариантов использования, в котором мы могли бы его использовать, — это когда нам нужно выполнить большую фильтрацию в одном разделе. В этом случае Cassandra по-прежнему выполняет сканирование таблицы, но мы можем ограничить его одним узлом:
SELECT * FROM company WHERE company_name = 'company_a' AND employee_age = 30 ALLOW FILTERING;
Поскольку мы добавили столбец кластеризации company_name в качестве условия, Cassandra использует его для идентификации узла, содержащего все данные компании. Следовательно, он выполняет сканирование таблицы только для данных таблицы на этом конкретном узле.
4. Вторичные индексы
Вторичные индексы в Cassandra устраняют необходимость запрашивать столбцы, которые не являются частью первичного ключа.
Когда мы вставляем данные, Cassandra использует файл только для добавления, называемый commitlog, для хранения изменений, поэтому записи выполняются быстро. В то же время данные записываются в кеш-память значений ключей/столбцов, который называется Memtable . Периодически Cassandra сбрасывает Memtable на диск в виде неизменного SSTable .
Далее давайте рассмотрим три различных метода индексации в Cassandra и обсудим их преимущества и недостатки.
4.1. Обычный вторичный индекс (2i)
Обычный вторичный индекс — это самый простой индекс, который мы можем определить для выполнения запросов к столбцам, не являющимся первичными ключами.
Давайте определим вторичный индекс для столбца employee_age :
CREATE INDEX IF NOT EXISTS ON company (employee_age);
Теперь мы можем выполнить запрос по employee_age без каких-либо ошибок:
SELECT * FROM company WHERE employee_age = 30;
company_name | employee_email | employee_age | employee_name
--------------+-------------------+--------------+---------------
company_A | emp1@companyA.com | 30 | employee_1
Когда мы настраиваем индекс, Cassandra создает скрытую таблицу для хранения данных индекса в фоновом режиме:
CREATE TABLE company_by_employee_age_idx (
employee_age int,
company_name text,
employee_email text,
PRIMARY KEY ((employee_age), company_name, employee_email)
);
В отличие от обычных таблиц, Cassandra не распространяет таблицу скрытых индексов с помощью разделителя на уровне кластера. Данные индекса размещаются вместе с исходными данными на тех же узлах.
Поэтому при выполнении поискового запроса с использованием вторичного индекса Cassandra считывает проиндексированные данные с каждого узла и собирает все результаты. Если в нашем кластере много узлов, это может привести к увеличению передачи данных и высокой задержке.
Мы могли бы спросить себя, почему Cassandra не разделяет индексную таблицу между узлами на основе первичного ключа. Ответ заключается в том, что хранение данных индекса вместе с исходными данными снижает задержку. Кроме того, поскольку обновление индекса выполняется локально, а не по сети, отсутствует риск потери операции обновления из-за проблем с подключением. Кроме того, Cassandra избегает создания широких разделов, если данные столбца индекса распределены неравномерно.
Когда мы вставляем данные в таблицу с прикрепленным вторичным индексом, Cassandra записывает данные как в индекс, так и в базовую Memtable . Кроме того, оба сбрасываются в SSTable одновременно. Следовательно, данные индекса будут иметь отдельный жизненный цикл, чем исходные данные.
Когда мы читаем данные на основе вторичного индекса, Cassandra сначала извлекает первичные ключи для всех совпадающих строк в индексе, а затем использует их для извлечения всех данных из исходной таблицы.
4.2. SSTable-Attached Secondary Index (SASI)
SASI представляет новую идею привязки жизненного цикла SSTable к индексу. Выполнение индексации в памяти с последующим сбросом индекса с помощью SSTable на диск снижает использование диска и экономит циклы ЦП.
Давайте посмотрим, как мы определяем индекс SASI:
CREATE CUSTOM INDEX IF NOT EXISTS company_by_employee_age ON company (employee_age) USING 'org.apache.cassandra.index.sasi.SASIIndex';
Преимущества SASI заключаются в токенизированном текстовом поиске, быстром сканировании диапазонов и индексировании в памяти. С другой стороны, недостатком является то, что он создает большие индексные файлы, особенно при включении токенизации текста.
Наконец, следует отметить, что индексы SASI в DataStax Enterprise (DSE) являются экспериментальными. DataStax не поддерживает индексы SASI для производства.
4.3. Индексирование с подключением к хранилищу (SAI)
Storage-Attached Indexing — это высокомасштабируемый механизм индексации данных, доступный для баз данных DataStax Astra и DataStax Enterprise. Мы можем определить один или несколько индексов SAI для любого столбца, а затем использовать запросы диапазона (только числовые), семантику CONTAIN и фильтровать запросы.
SAI хранит отдельные индексные файлы для каждого столбца и содержит указатель на смещение исходных данных в SSTable . Как только мы вставим данные в индексированный столбец, они сначала будут записаны в память. Всякий раз, когда Cassandra сбрасывает данные из памяти на диск, она записывает индекс вместе с таблицей данных.
Этот подход повышает пропускную способность на 43 % и задержку на 230 % по сравнению с 2i за счет снижения накладных расходов на запись . По сравнению с SASI и 2i он использует значительно меньше места на диске для индексации, имеет меньше точек сбоя и имеет более упрощенную архитектуру.
Давайте определим наш индекс с помощью SAI:
CREATE CUSTOM INDEX ON company (employee_age) USING 'StorageAttachedIndex' WITH OPTIONS = {'case_sensitive': false, 'normalize': false};
Опция нормализации преобразует специальные символы в их базовые символы. Например, мы можем нормализовать немецкий символ ö до обычного o, что позволит выполнять сопоставление запросов без ввода специальных символов. Таким образом, мы можем, например, искать термин «schön», просто используя «schon» в качестве условия.
4.4. Лучшие практики
Во-первых, когда мы используем вторичные индексы в наших запросах, рекомендуется добавить ключ секции в качестве условия. В результате мы можем сократить операцию чтения до одного узла (плюс реплики в зависимости от уровня согласованности):
SELECT * FROM company WHERE employee_age = 30 AND company_name = "company_A";
Во-вторых, мы можем ограничить запрос списком ключей разделов и ограничить количество узлов, участвующих в получении результатов:
SELECT * FROM company WHERE employee_age = 30 AND company_name IN ("company_A", "company_B", "company_C");
В-третьих, если нам нужно только подмножество результатов, мы можем добавить ограничение на запрос . Это также уменьшает количество узлов, участвующих в пути чтения:
SELECT * FROM company WHERE employee_age = 30 LIMIT 10;
Кроме того, мы должны избегать определения вторичных индексов для столбцов с очень низкой кардинальностью (пол, столбцы true/false и т. д.), поскольку они создают очень широкие разделы, влияющие на производительность.
Точно так же столбцы с высокой кардинальностью (номер социального страхования, электронная почта и т. д.) приведут к созданию индексов с очень гранулированными секциями , что в худшем случае заставит координатора кластера обращаться ко всем первичным репликам.
Наконец, мы должны избегать использования вторичных индексов для часто обновляемых столбцов. Причина этого в том, что Cassandra использует неизменяемые структуры данных, а частые обновления увеличивают количество операций записи на диск.
5. Вывод
В этой статье мы рассмотрели, как Cassandra разделяет данные в центре обработки данных, и рассмотрели три типа вторичных индексов.
Прежде чем рассматривать вторичный индекс, мы должны рассмотреть возможность денормализации наших данных во второй таблице и поддерживать их в актуальном состоянии с основной таблицей, если мы планируем часто обращаться к ней.
С другой стороны, если доступ к данным носит спорадический характер, добавление отдельной таблицы создает неоправданную сложность. Поэтому введение вторичного индекса является лучшим вариантом. Несомненно, индексирование с подключением к хранилищу — лучший выбор из трех имеющихся у нас вариантов индексирования, предлагающий наилучшую производительность и упрощенную архитектуру.