1. Обзор
В этом руководстве мы обсудим некоторые принципы и шаблоны проектирования, которые были установлены с течением времени для создания высококонкурентных приложений.
Однако стоит отметить, что разработка параллельного приложения — обширная и сложная тема, и, следовательно, ни одно руководство не может претендовать на исчерпывающую трактовку этой темы. Здесь мы расскажем о некоторых часто используемых популярных трюках!
2. Основы параллелизма
Прежде чем мы продолжим, давайте потратим некоторое время на понимание основ. Для начала мы должны прояснить наше понимание того, что мы называем параллельной программой. Мы называем программу параллельной , если одновременно выполняются несколько вычислений .
Теперь обратите внимание, что мы упомянули, что вычисления происходят в одно и то же время, то есть они выполняются в одно и то же время. Однако они могут выполняться или не выполняться одновременно. Важно понимать разницу, так как одновременно выполняемые вычисления называются параллельными .
2.1. Как создавать параллельные модули?
Важно понимать, как мы можем создавать параллельные модули. Существует множество вариантов, но мы сосредоточимся здесь на двух популярных вариантах:
- Процесс : процесс — это экземпляр работающей программы, изолированный от других процессов на том же компьютере. Каждый процесс на машине имеет свое собственное изолированное время и пространство. Следовательно, обычно невозможно разделить память между процессами, и они должны взаимодействовать, передавая сообщения.
- Поток . С другой стороны, поток — это просто сегмент процесса . В программе может быть несколько потоков, совместно использующих одно и то же пространство памяти. Однако каждый поток имеет уникальный стек и приоритет. Поток может быть собственным (запланированным операционной системой) или зеленым (запланированным библиотекой времени выполнения).
2.2. Как взаимодействуют параллельные модули?
Идеально, если параллельным модулям не нужно взаимодействовать, но это часто не так. Это приводит к двум моделям параллельного программирования:
- Общая память : в этой модели параллельные модули взаимодействуют, читая и записывая общие объекты в память . Это часто приводит к чередованию параллельных вычислений, вызывая состояние гонки. Следовательно, это может недетерминировано привести к неправильным состояниям.
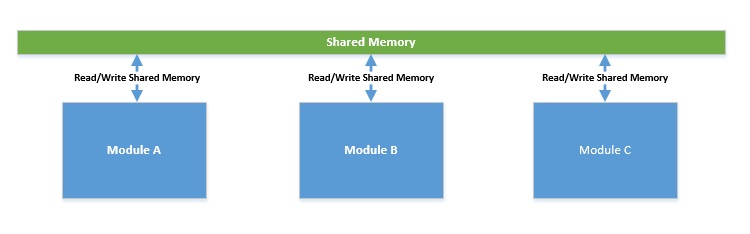
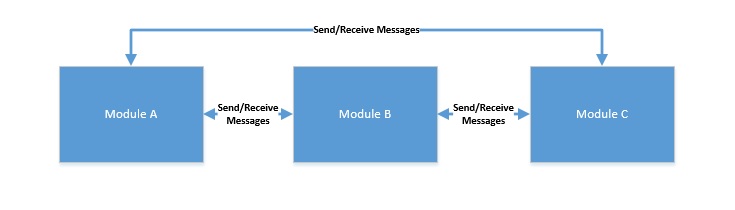
- Передача сообщений : в этой модели параллельные модули взаимодействуют, передавая сообщения друг другу через канал связи . Здесь каждый модуль последовательно обрабатывает входящие сообщения. Поскольку разделяемого состояния нет, его относительно проще программировать, но оно все еще не свободно от условий гонки!
2.3. Как выполняются параллельные модули?
Прошло некоторое время с тех пор, как закон Мура нарушил тактовую частоту процессора. Вместо этого, поскольку мы должны расти, мы начали упаковывать несколько процессоров в один и тот же чип, часто называемый многоядерными процессорами. Но все же нечасто можно услышать о процессорах, имеющих более 32 ядер.
Теперь мы знаем, что одно ядро может одновременно выполнять только один поток или набор инструкций. Однако количество процессов и потоков может исчисляться сотнями и тысячами соответственно. Итак, как это работает на самом деле? Здесь операционная система имитирует для нас параллелизм . Операционная система достигает этого за счет квантования времени, что фактически означает, что процессор часто, непредсказуемо и недетерминированно переключается между потоками.
3. Проблемы параллельного программирования
Поскольку мы приступаем к обсуждению принципов и шаблонов для разработки параллельного приложения, было бы разумно сначала понять, каковы типичные проблемы.
По большей части наш опыт параллельного программирования связан с использованием нативных потоков с разделяемой памятью . Следовательно, мы сосредоточимся на некоторых общих проблемах, которые возникают из-за этого:
- Взаимное исключение (примитивы синхронизации) . Чередующиеся потоки должны иметь эксклюзивный доступ к общему состоянию или памяти, чтобы гарантировать правильность программ . Синхронизация общих ресурсов — популярный метод взаимного исключения. Существует несколько доступных для использования примитивов синхронизации, например блокировка, монитор, семафор или мьютекс. Однако программирование для взаимного исключения подвержено ошибкам и часто может привести к снижению производительности. Есть несколько хорошо обсуждаемых проблем, связанных с этим, таких как deadlock и livelock .
- Переключение контекста (тяжелые потоки) : каждая операционная система имеет встроенную, хотя и различную, поддержку параллельных модулей, таких как процесс и поток. Как уже говорилось, одна из фундаментальных служб, предоставляемых операционной системой, — это планирование потоков для выполнения на ограниченном числе процессоров посредством квантования времени. Теперь это фактически означает, что потоки часто переключаются между разными состояниями . В процессе их текущее состояние необходимо сохранить и возобновить. Это трудоемкая операция, напрямую влияющая на общую пропускную способность.
4. Шаблоны проектирования для высокой степени параллелизма
Теперь, когда мы познакомились с основами параллельного программирования и его общими проблемами, пришло время понять некоторые общие шаблоны для избежания этих проблем. Мы должны повторить, что параллельное программирование — сложная задача, требующая большого опыта. Следовательно, следование некоторым из установленных шаблонов может облегчить задачу.
4.1. Параллелизм на основе акторов
Первый дизайн, который мы обсудим в отношении параллельного программирования, называется акторной моделью. Это математическая модель параллельных вычислений, в которой все рассматривается как действующее лицо . Актеры могут передавать сообщения друг другу и, в ответ на сообщение, могут принимать локальные решения. Это было впервые предложено Карлом Хьюиттом и вдохновило на создание ряда языков программирования.
Основной конструкцией Scala для параллельного программирования являются акторы. Актеры — это обычные объекты в Scala, которые мы можем создать, создав экземпляр класса Actor . Кроме того, библиотека Scala Actors предоставляет множество полезных операций с акторами:
class myActor extends Actor {
def act() {
while(true) {
receive {
// Perform some action
}
}
}
}
В приведенном выше примере вызов метода получения внутри бесконечного цикла приостанавливает действующее лицо до тех пор, пока не придет сообщение. По прибытии сообщение удаляется из почтового ящика актора, и выполняются необходимые действия.
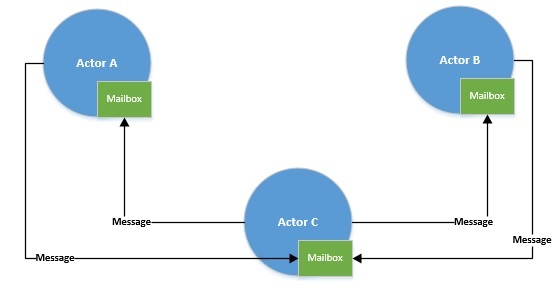
Модель акторов устраняет одну из фундаментальных проблем параллельного программирования — разделяемую память . Субъекты взаимодействуют посредством сообщений, и каждый субъект последовательно обрабатывает сообщения из своих эксклюзивных почтовых ящиков. Однако мы выполняем акторы через пул потоков. И мы видели, что нативные потоки могут быть тяжеловесными и, следовательно, ограниченными по количеству.
Есть, конечно, и другие шаблоны, которые могут нам здесь помочь — мы рассмотрим их позже!
4.2. Параллелизм на основе событий
Проекты, основанные на событиях, явным образом решают проблему, заключающуюся в том, что создание и эксплуатация нативных потоков требует больших затрат. Одним из основанных на событиях проектов является цикл событий. Цикл событий работает с поставщиком событий и набором обработчиков событий. В этой настройке цикл событий блокирует поставщика событий и отправляет событие обработчику событий по прибытии .
По сути, цикл событий — это не что иное, как диспетчер событий! Сам цикл событий может выполняться только в одном собственном потоке. Итак, что на самом деле происходит в цикле событий? Давайте посмотрим на псевдокод действительно простого цикла обработки событий для примера:
while(true) {
events = getEvents();
for(e in events)
processEvent(e);
}
По сути, все, что делает наш цикл событий, — это непрерывный поиск событий и, когда события найдены, их обработка. Подход действительно прост, но он использует преимущества событийно-ориентированного дизайна.
Создание параллельных приложений с использованием этого дизайна дает больше контроля над приложением. Также он устраняет некоторые типичные проблемы многопоточных приложений — например, взаимоблокировку.
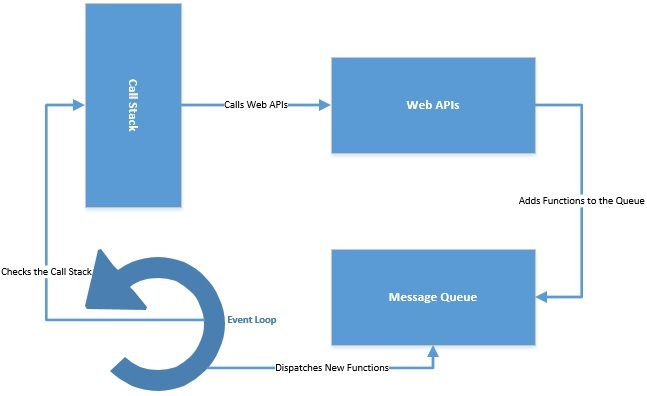
JavaScript реализует цикл обработки событий, предлагая асинхронное программирование . Он поддерживает стек вызовов для отслеживания всех выполняемых функций . Он также поддерживает очередь событий для отправки новых функций на обработку. Цикл событий постоянно проверяет стек вызовов и добавляет новые функции из очереди событий. Все асинхронные вызовы отправляются в веб-API, обычно предоставляемые браузером.
Сам цикл обработки событий может выполняться в одном потоке, но веб-API предоставляют отдельные потоки.
4.3. Неблокирующие алгоритмы
В неблокирующих алгоритмах приостановка одного потока не приводит к приостановке других потоков. Мы видели, что в нашем приложении может быть только ограниченное количество собственных потоков. Теперь алгоритм, который блокирует поток, очевидно, значительно снижает пропускную способность и не позволяет нам создавать приложения с высокой степенью параллельности.
Неблокирующие алгоритмы неизменно используют элементарный примитив сравнения и замены, предоставляемый базовым оборудованием . Это означает, что аппаратное обеспечение будет сравнивать содержимое ячейки памяти с заданным значением, и только если они совпадают, оно обновит значение до нового заданного значения. Это может показаться простым, но фактически предоставляет нам атомарную операцию, которая в противном случае потребовала бы синхронизации.
Это означает, что мы должны написать новые структуры данных и библиотеки, использующие эту атомарную операцию. Это дало нам огромный набор реализаций без ожидания и блокировки на нескольких языках. В Java есть несколько неблокирующих структур данных, таких как AtomicBoolean , AtomicInteger , AtomicLong и AtomicReference .
Рассмотрим приложение, в котором несколько потоков пытаются получить доступ к одному и тому же коду:
boolean open = false;
if(!open) {
// Do Something
open=false;
}
Очевидно, что приведенный выше код не является потокобезопасным, и его поведение в многопоточной среде может быть непредсказуемым. Наши варианты здесь — либо синхронизировать этот фрагмент кода с замком, либо использовать атомарную операцию:
AtomicBoolean open = new AtomicBoolean(false);
if(open.compareAndSet(false, true) {
// Do Something
}
Как мы видим, использование неблокирующей структуры данных, такой как AtomicBoolean , помогает нам писать потокобезопасный код, не допуская недостатков блокировок!
5. Поддержка языков программирования
Мы видели, что существует несколько способов создания параллельного модуля. Хотя язык программирования имеет значение, в основном это то, как базовая операционная система поддерживает концепцию. Однако, поскольку параллелизм на основе потоков, поддерживаемый собственными потоками, сталкивается с новыми трудностями в отношении масштабируемости, нам всегда нужны новые возможности.
Внедрение некоторых методов проектирования, которые мы обсуждали в предыдущем разделе, действительно доказало свою эффективность. Однако мы должны иметь в виду, что это усложняет программирование как таковое. Что нам действительно нужно, так это что-то, что обеспечивает мощность параллелизма на основе потоков без нежелательных эффектов, которые он приносит.
Одно из доступных нам решений — зеленые нити. Зеленые потоки — это потоки, запланированные библиотекой времени выполнения, а не изначально запланированные базовой операционной системой. Хотя это не избавляет от всех проблем параллелизма на основе потоков, в некоторых случаях это, безусловно, может повысить производительность.
Теперь использование зеленых потоков не является тривиальным, если выбранный нами язык программирования не поддерживает его. Не каждый язык программирования имеет такую встроенную поддержку. Кроме того, то, что мы условно называем зелеными потоками, может быть реализовано очень уникальными способами на разных языках программирования. Давайте посмотрим на некоторые из этих вариантов, доступных для нас.
5.1. Горутины в Go
Горутины в языке программирования Go — это легковесные потоки. Они предлагают функции или методы, которые могут выполняться одновременно с другими функциями или методами. Горутины чрезвычайно дешевы, так как они занимают всего несколько килобайт в размере стека, для начала .
Что наиболее важно, горутины мультиплексируются с меньшим количеством собственных потоков. Более того, горутины общаются друг с другом по каналам, тем самым избегая доступа к общей памяти. Мы получаем почти все, что нам нужно, и угадайте, что — ничего не делая!
5.2. Процессы в Эрланге
В Erlang каждый поток выполнения называется процессом. Но это не совсем похоже на процесс, который мы обсуждали до сих пор! Процессы Erlang легкие, занимают мало памяти, быстро создаются и удаляются с минимальными затратами на планирование.
Под капотом процессы Erlang представляют собой не что иное, как функции, планирование которых выполняет среда выполнения. Более того, процессы Erlang не обмениваются никакими данными и взаимодействуют друг с другом посредством передачи сообщений. Вот почему мы называем эти процессы «процессами» в первую очередь!
5.3. Волокна в Java (предложение)
История параллелизма с Java была непрерывной эволюцией. В Java изначально была поддержка зеленых потоков, по крайней мере, для операционных систем Solaris. Однако это было прекращено из-за препятствий, выходящих за рамки этого руководства.
С тех пор параллелизм в Java связан с нативными потоками и умной работой с ними! Но по понятным причинам вскоре у нас может появиться новая абстракция параллелизма в Java, называемая волокном. Project Loom предлагает ввести продолжения вместе с волокнами, которые могут изменить то, как мы пишем параллельные приложения на Java!
Это всего лишь краткий обзор того, что доступно на разных языках программирования. Есть гораздо более интересные способы, которыми другие языки программирования пытались справиться с параллелизмом.
Кроме того, стоит отметить, что комбинация шаблонов проектирования, обсуждавшихся в предыдущем разделе, вместе с поддержкой языка программирования для абстракции, подобной зеленому потоку, может быть чрезвычайно эффективной при разработке приложений с высокой степенью параллельности.
6. Приложения с высокой степенью параллелизма
Реальное приложение часто имеет несколько компонентов, взаимодействующих друг с другом по сети. Обычно мы получаем к нему доступ через Интернет, и он состоит из нескольких служб, таких как прокси-служба, шлюз, веб-служба, база данных, служба каталогов и файловые системы.
Как обеспечить высокий уровень параллелизма в таких ситуациях? Давайте рассмотрим некоторые из этих уровней и варианты, которые у нас есть для создания высокопараллельного приложения.
Как мы видели в предыдущем разделе, ключом к созданию приложений с высокой степенью параллелизма является использование некоторых обсуждаемых здесь концепций проектирования. Нам нужно выбрать правильное программное обеспечение для работы — то, которое уже включает в себя некоторые из этих практик.
6.1. Веб-слой
Интернет обычно является первым уровнем, куда поступают пользовательские запросы, и здесь неизбежна подготовка для обеспечения высокого параллелизма. Давайте посмотрим, какие есть варианты:
- Node (также называемый NodeJS или Node.js) — это кроссплатформенная среда выполнения JavaScript с открытым исходным кодом, построенная на движке Chrome V8 JavaScript. Node довольно хорошо справляется с асинхронными операциями ввода-вывода. Причина, по которой Node делает это так хорошо, заключается в том, что он реализует цикл обработки событий в одном потоке. Цикл событий с помощью обратных вызовов обрабатывает все блокирующие операции, такие как ввод-вывод, асинхронно.
- nginx — это веб-сервер с открытым исходным кодом, который мы обычно используем в качестве обратного прокси-сервера среди других его применений. Причина, по которой nginx обеспечивает высокий параллелизм, заключается в том, что он использует асинхронный, управляемый событиями подход. nginx работает с мастер-процессом в одном потоке. Главный процесс поддерживает рабочие процессы, которые выполняют фактическую обработку. Следовательно, рабочие процессы обрабатывают каждый запрос одновременно.
6.2. Прикладной уровень
При разработке приложения есть несколько инструментов, которые помогут нам обеспечить высокую степень параллелизма. Давайте рассмотрим несколько из этих библиотек и фреймворков, которые нам доступны:
- Akka — это набор инструментов, написанный на Scala для создания высокопараллельных и распределенных приложений на JVM. Подход Akka к обработке параллелизма основан на модели акторов, которую мы обсуждали ранее. Akka создает слой между акторами и базовыми системами. Фреймворк справляется со сложностями создания и планирования потоков, получения и отправки сообщений.
- Project Reactor — это реактивная библиотека для создания неблокирующих приложений на JVM. Он основан на спецификации Reactive Streams и ориентирован на эффективную передачу сообщений и управление спросом (обратное давление). Операторы Reactor и планировщики могут поддерживать высокую пропускную способность для сообщений. Несколько популярных фреймворков предоставляют реализации реактора, включая Spring WebFlux и RSocket.
- Netty — это асинхронная среда сетевых приложений, управляемая событиями. Мы можем использовать Netty для разработки высококонкурентных протокольных серверов и клиентов . Netty использует NIO , набор API-интерфейсов Java, который предлагает асинхронную передачу данных через буферы и каналы. Он предлагает нам несколько преимуществ, таких как лучшая пропускная способность, меньшая задержка, меньшее потребление ресурсов и минимизация ненужного копирования памяти.
6.3. Уровень данных
Наконец, ни одно приложение не будет полным без его данных, а данные поступают из постоянного хранилища. Когда мы обсуждаем высокий параллелизм в отношении баз данных, основное внимание уделяется семейству NoSQL. В первую очередь это связано с линейной масштабируемостью, которую могут предложить базы данных NoSQL, но которую трудно достичь в реляционных вариантах. Давайте рассмотрим два популярных инструмента для слоя данных:
- Cassandra — это бесплатная распределенная база данных NoSQL с открытым исходным кодом , которая обеспечивает высокую доступность, высокую масштабируемость и отказоустойчивость на обычном оборудовании. Однако Cassandra не поддерживает транзакции ACID, охватывающие несколько таблиц. Поэтому, если наше приложение не требует строгой согласованности и транзакций, мы можем извлечь выгоду из операций Cassandra с малой задержкой .
- Kafka — это распределенная платформа потокового вещания . Kafka хранит поток записей в категориях, называемых темами. Он может обеспечить линейную горизонтальную масштабируемость как для производителей, так и для потребителей записей, в то же время обеспечивая высокую надежность и долговечность. Разделы, реплики и брокеры — это некоторые из фундаментальных концепций, на которых он обеспечивает массово-распределенный параллелизм .
6.4. Кэш-слой
Что ж, ни одно веб-приложение в современном мире, нацеленное на высокий параллелизм, не может позволить себе каждый раз обращаться к базе данных. Это оставляет нам возможность выбрать кеш — предпочтительно кеш в памяти, который может поддерживать наши высококонкурентные приложения:
- Hazelcast — это распределенное, дружественное к облаку хранилище объектов в памяти и вычислительный механизм, который поддерживает широкий спектр структур данных, таких как
Map,Set,List,MultiMap,RingBufferиHyperLogLog. Он имеет встроенную репликацию и предлагает высокую доступность и автоматическое разделение. - Redis — это хранилище структур данных в памяти, которое мы в основном используем в качестве кеша . Он предоставляет хранящуюся в памяти базу данных «ключ-значение» с дополнительной надежностью. Поддерживаемые структуры данных включают строки, хэши, списки и наборы. Redis имеет встроенную репликацию и предлагает высокую доступность и автоматическое разделение. Если нам не нужна сохраняемость, Redis может предложить многофункциональный сетевой кэш в памяти с выдающейся производительностью.
Конечно, мы едва коснулись того, что нам доступно в нашем стремлении создать приложение с высокой степенью параллельности. Важно отметить, что наше требование должно направлять нас не только к доступному программному обеспечению, но и к созданию соответствующего дизайна. Некоторые из этих вариантов могут быть подходящими, а другие могут не подходить.
И давайте не будем забывать, что есть много других доступных опций, которые могут лучше соответствовать нашим требованиям.
7. Заключение
В этой статье мы обсудили основы параллельного программирования. Мы поняли некоторые фундаментальные аспекты параллелизма и проблемы, к которым он может привести. Кроме того, мы рассмотрели некоторые шаблоны проектирования, которые могут помочь нам избежать типичных проблем при параллельном программировании.
Наконец, мы рассмотрели некоторые фреймворки, библиотеки и программное обеспечение, доступные нам для создания высокопараллельного сквозного приложения.