1. Введение
В этом уроке мы обсудим наблюдаемость и почему она играет важную роль в распределенной системе. Мы рассмотрим типы данных, которые составляют наблюдаемость. Это поможет нам понять проблемы, связанные со сбором, хранением и анализом данных телеметрии из распределенной системы.
Наконец, мы рассмотрим некоторые отраслевые стандарты и популярные инструменты в области наблюдаемости.
2. Что такое наблюдаемость?
Давайте перейдем к делу и для начала дадим формальное определение! Наблюдаемость — это способность измерять внутреннее состояние системы только по ее внешним выходам .
Для распределенной системы , такой как микросервисы, эти внешние выходные данные в основном известны как данные телеметрии. Он включает в себя такую информацию, как потребление ресурсов машиной, журналы, созданные приложениями, работающими на машине, и некоторые другие.
2.1. Типы данных телеметрии
Мы можем разделить данные телеметрии на три категории, которые мы называем тремя столпами наблюдаемости: журналы, метрики и трассировки. Давайте разберемся в них подробнее.
Журналы — это строки текста, которые приложение генерирует в дискретных точках во время выполнения кода. Обычно они структурированы и часто генерируются с разным уровнем серьезности. Их довольно легко сгенерировать, но они часто влекут за собой затраты на производительность. Кроме того, нам могут потребоваться дополнительные инструменты, такие как Logstash, для эффективного сбора, хранения и анализа журналов.
Проще говоря, метрики — это значения, представленные в виде подсчетов или мер, которые мы рассчитываем или агрегируем за определенный период времени. Эти значения выражают некоторые данные о системе, такой как виртуальная машина, например потребление памяти виртуальной машиной каждую секунду. Они могут поступать из различных источников, таких как хост, приложение и облачная платформа.
Трассировки важны для распределенных систем, где один запрос может проходить через несколько приложений. Трассировка — это представление распределенных событий по мере того, как запрос проходит через распределенную систему . Это может быть очень полезно при обнаружении таких проблем, как узкие места, дефекты или другие проблемы в распределенной системе.
2.2. Преимущества наблюдаемости
Для начала нам нужно понять, зачем нам вообще нужна наблюдаемость в системе. Большинство из нас, вероятно, сталкивались с проблемами устранения неполадок, связанных с трудным для понимания поведением в производственной системе. Нетрудно понять, что наши возможности для разрушения производственной среды ограничены. Это в значительной степени оставляет нам возможность анализировать данные, которые генерирует система.
Наблюдаемость бесценна для исследования ситуаций, когда система начинает отклоняться от намеченного состояния . Также очень полезно полностью предотвратить эти ситуации! Тщательная настройка предупреждений на основе наблюдаемых данных, генерируемых системой, может помочь нам принять меры по исправлению положения до того, как система полностью выйдет из строя. Кроме того, такие данные дают нам важную аналитическую информацию для настройки системы для лучшего опыта.
Потребность в наблюдаемости важна для любой системы, но весьма важна для распределенной системы. Более того, наши системы могут охватывать общедоступные и частные облака, а также локальные среды. Кроме того, со временем он продолжает меняться в масштабе и сложности. Это может часто создавать проблемы, которые никогда не предполагались ранее. Хорошо наблюдаемая система может чрезвычайно помочь нам справиться с такими ситуациями.
3. Наблюдаемость против мониторинга
Мы часто слышим о мониторинге в отношении наблюдаемости в практике DevOps . Итак, в чем разница между этими терминами? Что ж, они оба имеют схожие функции и позволяют нам поддерживать надежность системы. Но у них есть тонкая разница и, по сути, связь между ними. Мы можем эффективно контролировать систему только в том случае, если она поддается наблюдению!
Мониторинг в основном относится к практике наблюдения за состоянием системы с помощью предопределенного набора показателей и журналов . Это по своей сути означает, что мы наблюдаем за известным набором отказов. Однако в распределенной системе постоянно происходит множество динамических изменений. Это приводит к проблемам, которые мы никогда не искали. Следовательно, наша система мониторинга может их просто пропустить.
С другой стороны, наблюдаемость помогает нам понять внутреннее состояние системы. Это может позволить нам задавать произвольные вопросы о поведении системы. Например, мы можем задавать сложные вопросы, например, как каждая служба обрабатывала запрос в случае возникновения проблем. Со временем это может помочь в накоплении знаний о динамическом поведении системы.
Чтобы понять, почему это так, нам нужно понять концепцию кардинальности. Кардинальность относится к количеству уникальных элементов в наборе . Например, набор номеров социального страхования пользователей будет иметь более высокую кардинальность, чем пол. Чтобы ответить на произвольные вопросы о поведении системы, нам нужны данные высокой кардинальности. Однако мониторинг обычно имеет дело только с данными с низким количеством элементов.
4. Наблюдаемость в распределенной системе
Как мы видели ранее, наблюдаемость особенно полезна для сложной распределенной системы. Но что именно делает распределенную систему сложной и каковы проблемы наблюдаемости в такой системе? Важно понять этот вопрос, чтобы оценить экосистему инструментов и платформ, выросших вокруг этой темы за последние несколько лет.
В распределенной системе есть много движущихся компонентов, которые динамически изменяют системный ландшафт . Более того, динамическая масштабируемость означает, что в любой момент времени для службы будет запущено неопределенное количество экземпляров. Это усложняет работу по сбору, обработке и хранению выходных данных системы, таких как журналы и метрики:
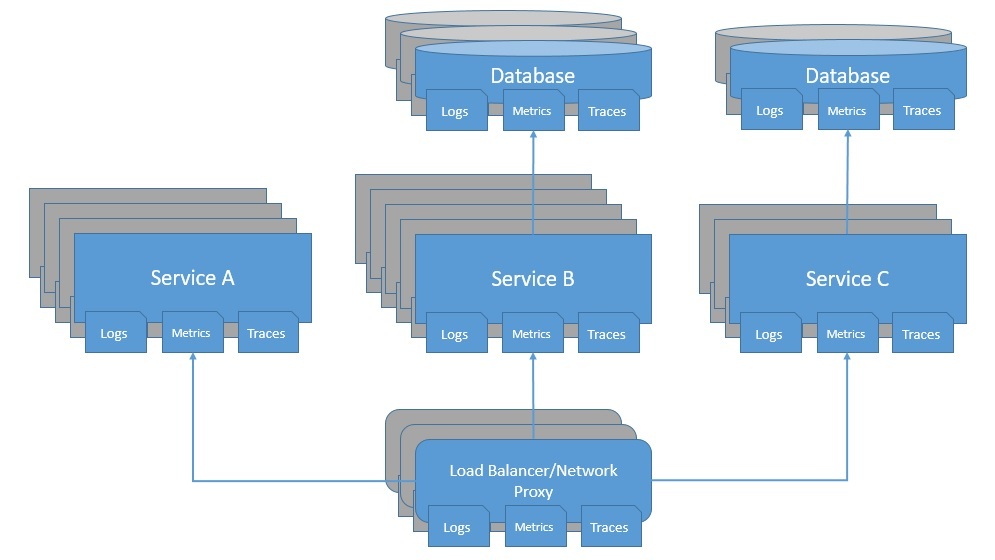
Кроме того, недостаточно просто понять, что происходит в приложениях системы. Например, проблема может быть на сетевом уровне или балансировщике нагрузки. Затем есть базы данных, платформы обмена сообщениями, и этот список можно продолжить. Важно, чтобы все эти компоненты были доступны для наблюдения в любое время. Мы должны иметь возможность собирать и централизовать значимые данные из всех частей системы.
Более того, поскольку несколько компонентов работают вместе, синхронно или асинхронно, определить источник аномалии непросто. Например, трудно сказать, какая служба в системе является причиной усугубления узких мест по мере снижения производительности. Трассировки, как мы видели ранее, весьма полезны при исследовании таких проблем.
5. Эволюция наблюдаемости
Наблюдаемость уходит своими корнями в теорию управления, раздел прикладной математики, который занимается использованием обратной связи для воздействия на поведение системы для достижения желаемой цели . Мы можем применить этот принцип в нескольких отраслях, от промышленных предприятий до эксплуатации самолетов. Для программных систем это стало популярным с тех пор, как некоторые сайты социальных сетей, такие как Twitter, начали работать в массовом масштабе .
До недавнего времени большинство программных систем были монолитными, что позволяло легко рассуждать о них во время инцидентов. Мониторинг оказался достаточно эффективным для выявления типичных сценариев отказа. Кроме того, было интуитивно понятно отлаживать код для выявления проблем. Но с появлением микросервисной архитектуры и облачных вычислений это быстро стало сложной задачей.
По мере того как эта эволюция продолжалась, программные системы больше не были статичными — в них было множество компонентов, которые динамически менялись. Это привело к проблемам, которых раньше никто не ожидал. Это привело к появлению множества инструментов под эгидой Application Performance Management (APM) , таких как AppDynamics и Dynatrace . Эти инструменты обещали лучший способ понять код приложения и поведение системы.
Хотя эти инструменты прошли долгий путь развития, в то время они в значительной степени основывались на метриках. Это помешало им предоставить требуемую нам точку зрения на состояние систем. Тем не менее, они были большим шагом вперед. Сегодня у нас есть набор инструментов для решения трех столпов наблюдаемости. Конечно, базовые компоненты также должны быть наблюдаемыми!
6. Практика с наблюдаемостью
Теперь, когда мы рассмотрели достаточно теории о наблюдаемости, давайте посмотрим, как мы можем применить это на практике. Мы будем использовать простую распределенную систему на основе микросервисов, в которой мы будем разрабатывать отдельные сервисы с помощью Spring Boot на Java . Эти службы будут синхронно взаимодействовать друг с другом с помощью REST API.
Давайте посмотрим на наши системные службы:
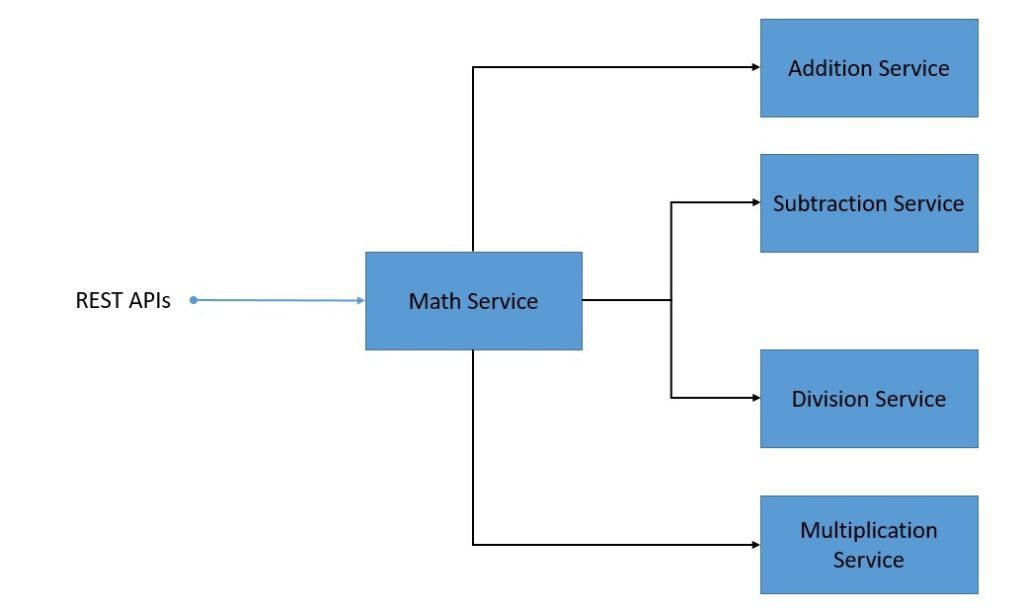
Это довольно простая распределенная система, где math-сервис использует API, предоставляемые сервисом сложения , сервисом умножения и другими. Кроме того, математический сервис предоставляет API для расчета различных формул. Мы пропустим детали создания этих микросервисов, так как это очень просто.
Основное внимание в этом упражнении уделяется признанию наиболее распространенных стандартов и популярных инструментов, доступных сегодня в контексте наблюдаемости. Наша целевая архитектура для этой системы с наблюдаемостью будет выглядеть примерно так, как показано на диаграмме ниже:
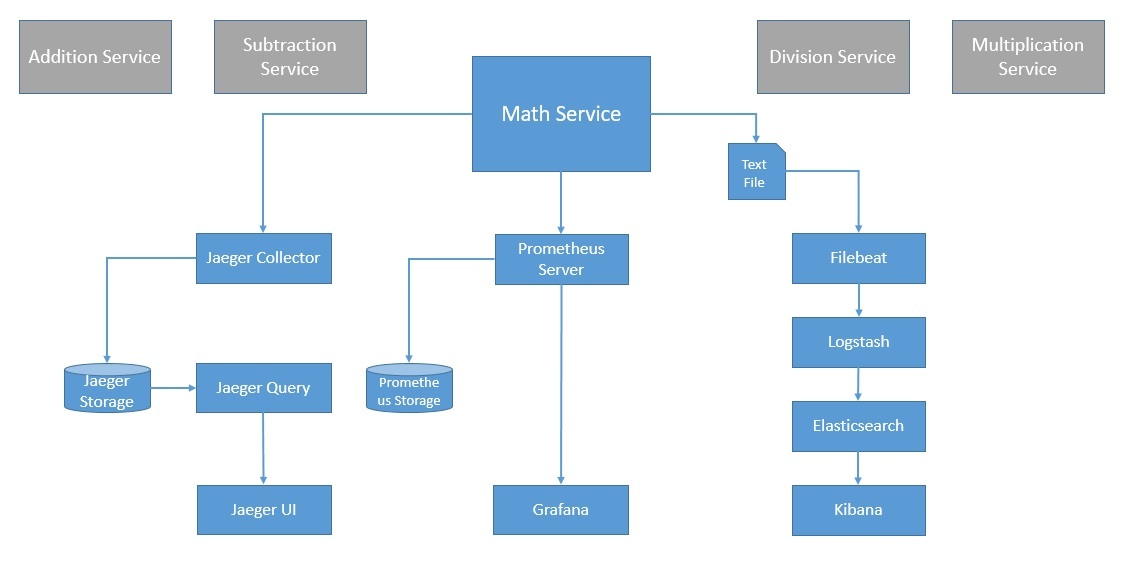
Многие из них также находятся на разных стадиях признания в Cloud Native Computing Foundation (CNCF) , организации, которая способствует развитию контейнерных технологий. Мы увидим, как использовать некоторые из них в нашей распределенной системе.
7. Трассировка с OpenTracing
Мы видели, как трассировка может предоставить бесценную информацию для понимания того, как один запрос распространяется через распределенную систему. OpenTracing — это инкубационный проект CNCF. Он предоставляет независимые от поставщика API и инструментарий для распределенной трассировки . Это помогает нам добавлять инструменты в наш код, которые не относятся к какому-либо поставщику.
Список доступных трассировщиков, соответствующих OpenTracing, быстро растет. Одним из самых популярных трейсеров является Jaeger , который также является градуированным проектом CNCF.
Давайте посмотрим, как мы можем использовать Jaeger с OpenTracing в нашем приложении:
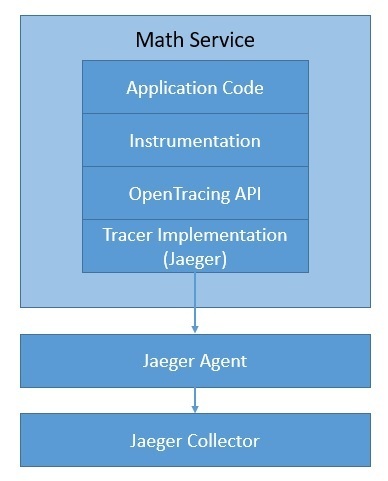
Подробности мы рассмотрим позже. Просто отметим, что есть несколько других вариантов, таких как LightStep , Instana , SkyWalking и Datadog . Мы можем легко переключаться между этими трассировщиками, не меняя способ добавления инструментария в наш код.
7.1. Понятия и терминология
Трассировка в OpenTracing состоит из интервалов. Промежуток — это отдельная единица работы, выполняемая в распределенной системе . По сути, трассу можно рассматривать как ориентированный ациклический граф (DAG) отрезков. Мы называем ребра между пролетами ссылками. Каждый компонент в распределенной системе добавляет диапазон к трассировке. Промежутки содержат ссылки на другие промежутки, и это помогает трассировке воссоздать жизнь запроса.
Мы можем визуализировать причинно-следственную связь между интервалами в трассе с помощью временной оси или графика:
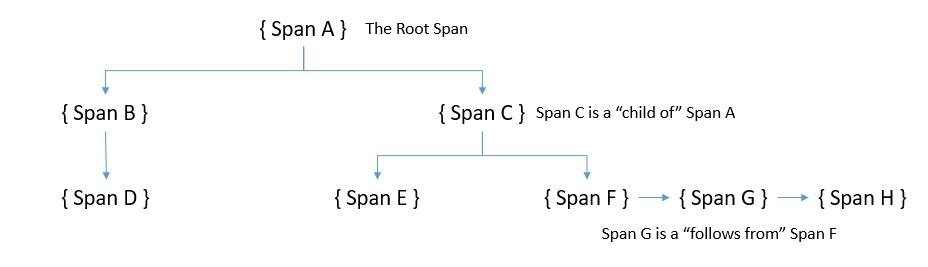
Здесь мы видим два типа ссылок, которые определяет OpenTracing : «ChildOf» и «FollowsFrom». Они устанавливают отношения между дочерними и родительскими пролетами.
Спецификация OpenTracing определяет состояние, которое захватывает диапазон:
- Имя операции
- Отметка времени начала и отметка времени окончания
- Набор тегов диапазона "ключ-значение"
- Набор журналов диапазона ключ-значение
- SpanContext
Теги позволяют определяемым пользователем аннотациям быть частью диапазона , который мы используем для запроса и фильтрации данных трассировки. Теги Span применяются ко всему диапазону. Точно так же журналы позволяют диапазону записывать сообщения журнала и другие отладочные или информационные выходные данные из приложения. Журналы диапазона могут применяться к определенному моменту или событию в диапазоне.
Наконец, SpanContext связывает спаны вместе . Он переносит данные через границы процесса. Давайте быстро взглянем на типичный SpanContext:

Как мы видим, в основном он состоит из:
- Состояние, зависящее от реализации, такое как
spanIdиtraceId. - Любые предметы багажа, представляющие собой пары ключ-значение, пересекающие границу процесса.
7.2. Установка и инструменты
Мы начнем с установки Jaeger , трассировщика, совместимого с OpenTracing, который мы будем использовать. Хотя у него есть несколько компонентов, мы можем установить их все с помощью простой команды Docker:
docker run -d -p 5775:5775/udp -p 16686:16686 jaegertracing/all-in-one:latest
Далее нам нужно импортировать необходимые зависимости в наше приложение. Для приложения на основе Maven это так же просто, как добавить зависимость :
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-spring-jaeger-web-starter</artifactId>
<version>3.3.1</version>
</dependency>
Для приложения на основе Spring Boot мы можем использовать эту библиотеку, предоставленную третьими сторонами. Это включает в себя все необходимые зависимости и предоставляет необходимые конфигурации по умолчанию для обработки веб-запросов/ответов и отправки трассировок в Jaeger.
На стороне приложения нам нужно создать Tracer :
@Bean
public Tracer getTracer() {
Configuration.SamplerConfiguration samplerConfig = Configuration
.SamplerConfiguration.fromEnv()
.withType("const").withParam(1);
Configuration.ReporterConfiguration reporterConfig = Configuration
.ReporterConfiguration.fromEnv()
.withLogSpans(true);
Configuration config = new Configuration("math-service")
.withSampler(samplerConfig)
.withReporter(reporterConfig);
return config.getTracer();
}
Этого достаточно для создания диапазонов для сервисов, через которые проходит запрос. Мы также можем генерировать дочерние промежутки в нашем сервисе, если это необходимо:
Span span = tracer.buildSpan("my-span").start();
// Some code for which which the span needs to be reported
span.finish();
Это довольно просто и интуитивно понятно, но чрезвычайно эффективно, когда мы анализируем их для сложной распределенной системы.
7.3. Анализ трассировки
Jaeger поставляется с пользовательским интерфейсом, доступным по умолчанию через порт 16686. Он предоставляет простой способ запроса, фильтрации и анализа данных трассировки с визуализацией. Давайте посмотрим пример трассировки для нашей распределенной системы:
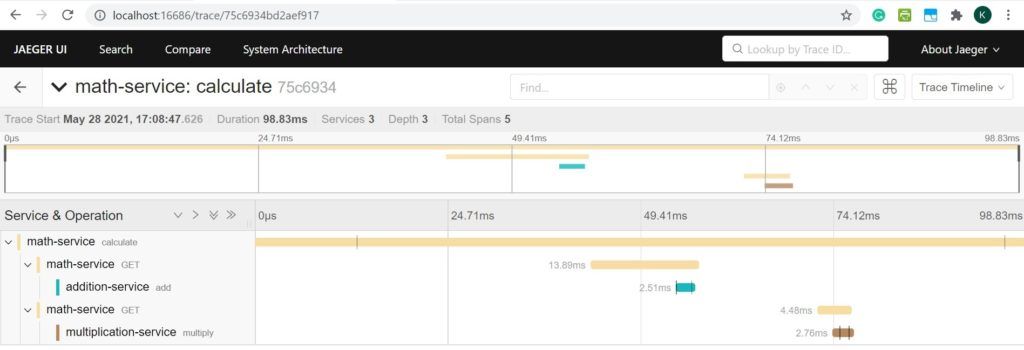
Как мы видим, это визуализация одной конкретной трассы, идентифицируемой по ее traceId. Он четко показывает все промежутки в этой трассе с такими подробностями, как служба, к которой она принадлежит, и время, которое потребовалось для ее завершения. Это может помочь нам понять, где может быть проблема в случае нетипичного поведения.
8. Метрики с OpenCensus
OpenCensus предоставляет библиотеки для различных языков, которые позволяют нам собирать метрики и распределенные трассировки из нашего приложения. Он возник в Google, но с тех пор разрабатывался растущим сообществом как проект с открытым исходным кодом. Преимущество OpenCensus заключается в том, что он может отправлять данные на любой сервер для анализа. Это позволяет нам абстрагировать наш инструментальный код, а не привязывать его к конкретным бэкендам.
Хотя OpenCensus может поддерживать как трассировку, так и метрики, мы будем использовать его только для метрик в нашем примере приложения. Есть несколько бэкэндов, которые мы можем использовать . Одним из самых популярных инструментов метрик является Prometheus , решение для мониторинга с открытым исходным кодом, которое также является градуированным проектом в рамках CNCF. Давайте посмотрим, как Jaeger с OpenCensus интегрируется с нашим приложением:
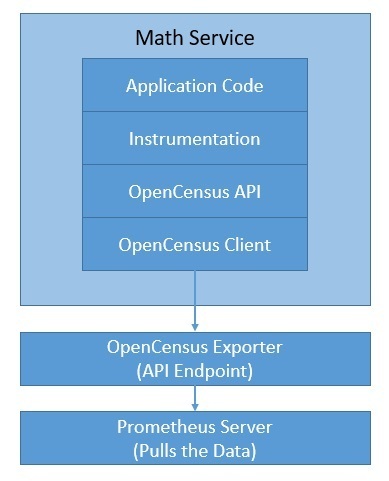
Хотя Prometheus поставляется с пользовательским интерфейсом, мы можем использовать инструмент визуализации, такой как Grafana , который хорошо интегрируется с Prometheus.
8.1. Понятия и терминология
В OpenCensus мера представляет собой регистрируемый тип метрики . Например, размер полезной нагрузки запроса может быть одной мерой для сбора. Измерение – это точка данных, полученная после записи количества по мере . Например, 80 КБ может быть мерой размера полезной нагрузки запроса. Все показатели идентифицируются по имени, описанию и единице измерения.
Чтобы проанализировать статистику, нам нужно агрегировать данные с просмотрами. Представления — это, по сути, совокупность агрегации, применяемой к показателю и, при необходимости, к тегам. OpenCensus поддерживает такие методы агрегирования, как подсчет, распределение, сумма и последнее значение. Представление состоит из имени, описания, меры, ключей тегов и агрегации. Несколько представлений могут использовать одну и ту же меру с разными агрегатами.
Теги — это пары данных «ключ-значение», связанные с записанными измерениями , для предоставления контекстной информации, а также для различения и группировки метрик во время анализа. Когда мы объединяем измерения для создания метрик, мы можем использовать теги в качестве меток для разбивки метрик. Теги также могут распространяться как заголовки запросов в распределенной системе.
Наконец, экспортер может отправить метрики на любой сервер , который может их использовать. Экспортер может меняться в зависимости от серверной части без какого-либо влияния на клиентский код. Это делает OpenCensus независимым от поставщиков с точки зрения сбора метрик. Существует довольно много экспортеров, доступных на нескольких языках для большинства популярных бэкендов, таких как Prometheus.
8.2. Установка и инструменты
Поскольку мы будем использовать Prometheus в качестве нашего бэкенда, мы должны начать с его установки. Это быстро и просто с использованием официального образа Docker. Prometheus собирает метрики с отслеживаемых целей, очищая конечные точки метрик на этих целях. Итак, нам нужно предоставить детали в YAML-файле конфигурации Prometheus, prometheus.yml :
scrape_configs:
- job_name: 'spring_opencensus'
scrape_interval: 10s
static_configs:
- targets: ['localhost:8887', 'localhost:8888', 'localhost:8889']
Это фундаментальная конфигурация, которая сообщает Prometheus, из каких целей следует собирать метрики. Теперь мы можем запустить Prometheus с помощью простой команды:
docker run -d -p 9090:9090 -v \
./prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Для определения пользовательских метрик мы начнем с определения меры :
MeasureDouble M_LATENCY_MS = MeasureDouble
.create("math-service/latency", "The latency in milliseconds", "ms");
Далее нам нужно записать измерение для меры , которую мы только что определили:
StatsRecorder STATS_RECORDER = Stats.getStatsRecorder();
STATS_RECORDER.newMeasureMap()
.put(M_LATENCY_MS, 17.0)
.record();
Затем нам нужно определить агрегацию и представление для нашей меры, которые позволят нам экспортировать ее как метрику :
Aggregation latencyDistribution = Distribution.create(BucketBoundaries.create(
Arrays.asList(0.0, 25.0, 100.0, 200.0, 400.0, 800.0, 10000.0)));
View view = View.create(
Name.create("math-service/latency"),
"The distribution of the latencies",
M_LATENCY_MS,
latencyDistribution,
Collections.singletonList(KEY_METHOD)),
};
ViewManager manager = Stats.getViewManager();
manager.registerView(view);
Наконец, для экспорта представлений в Prometheus нам нужно создать и зарегистрировать сборщик и запустить HTTP-сервер в качестве демона:
PrometheusStatsCollector.createAndRegister();
HTTPServer server = new HTTPServer("localhost", 8887, true);
Это простой пример, который иллюстрирует, как мы можем записывать задержку как меру из нашего приложения и экспортировать ее как представление в Prometheus для хранения и анализа.
8.3. Анализ показателей
OpenCensus предоставляет внутрипроцессные веб-страницы, называемые zPages , которые отображают собранные данные процесса, к которому они подключены. Кроме того, Prometheus предлагает браузер выражений, который позволяет нам вводить любое выражение и видеть его результат. Однако такие инструменты, как Grafana , обеспечивают более элегантную и эффективную визуализацию.
Установить Grafana с помощью официального образа Docker довольно просто:
docker run -d --name=grafana -p 3000:3000 grafana/grafana
Grafana поддерживает запросы к Prometheus — нам просто нужно добавить Prometheus в качестве источника данных в Grafana . Затем мы можем создать график с обычным выражением запроса Prometheus для метрик:
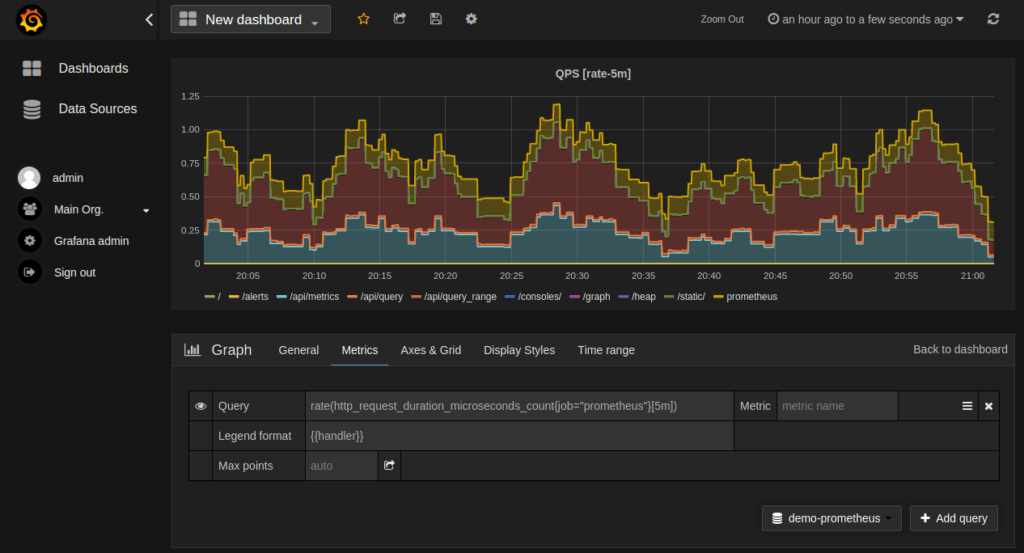
Есть несколько настроек графика, которые мы можем использовать для настройки нашего графика. Кроме того, для Prometheus доступно несколько готовых панелей инструментов Grafana, которые могут оказаться полезными.
9. Бревна с эластичным стеком
Журналы могут предоставить бесценную информацию о том, как приложение отреагировало на событие. К сожалению, в распределенной системе это разделено на несколько компонентов. Следовательно, становится важным собирать журналы со всех компонентов и хранить их в одном месте для эффективного анализа. Кроме того, нам требуется интуитивно понятный пользовательский интерфейс для эффективного запроса, фильтрации и ссылки на журналы.
Elastic Stack — это, по сути, платформа управления журналами, которая до недавнего времени представляла собой набор из трех продуктов — Elasticsearch, Logstash и Kibana (ELK).
Однако с тех пор в этот стек были добавлены Beats для эффективного сбора данных .
Давайте посмотрим, как мы можем использовать эти продукты в нашем приложении:
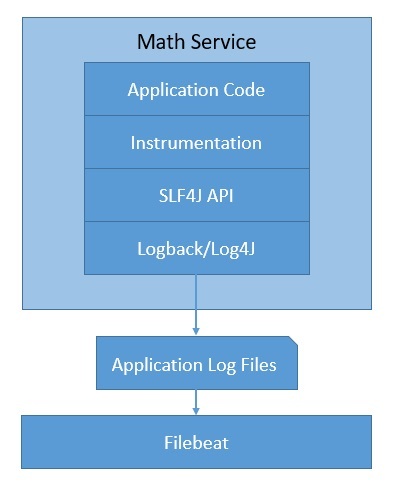
Как мы видим, в Java мы можем генерировать журналы с помощью простой абстракции, такой как SLF4J , и регистратора, такого как Logback . Мы пропустим эти детали здесь.
Продукты Elastic Stack имеют открытый исходный код и поддерживаются Elastic . Вместе они обеспечивают убедительную платформу для анализа журналов в распределенной системе.
9.1. Понятия и терминология
Как мы видели, Elastic Stack представляет собой набор из нескольких продуктов. Самым ранним из этих продуктов был Elasticseach — распределенная поисковая система RESTful на основе JSON . Он довольно популярен благодаря своей гибкости и масштабируемости. Это продукт, который привел к созданию Elastic. Он основан на поисковой системе Apache Lucene.
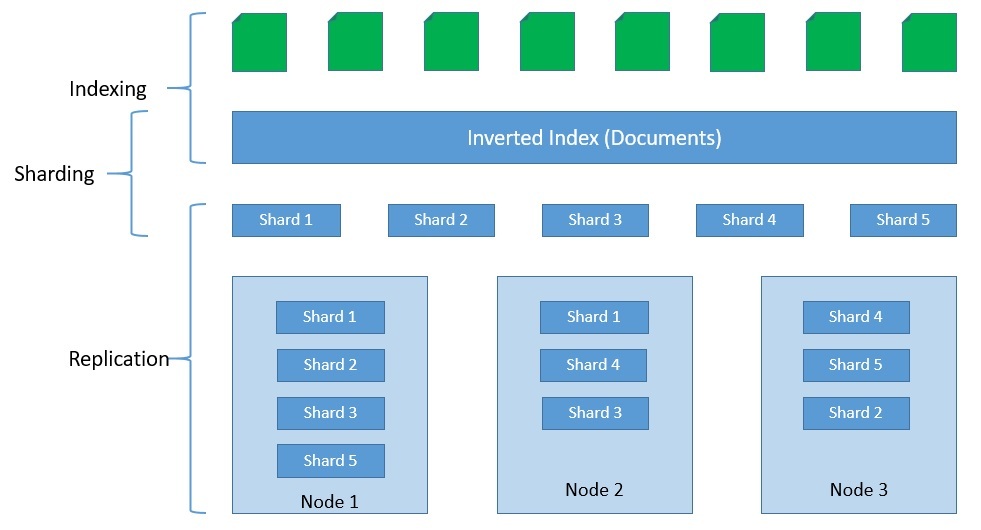
Elasticsearch хранит индексы в виде документов, которые являются базовой единицей хранения . Это простые объекты JSON. Мы можем использовать типы для разделения похожих типов данных внутри документа. Индексы — это логические разделы документов. Как правило, мы можем разделить индексы горизонтально на осколки для масштабируемости. Кроме того, мы также можем реплицировать осколки для отказоустойчивости:
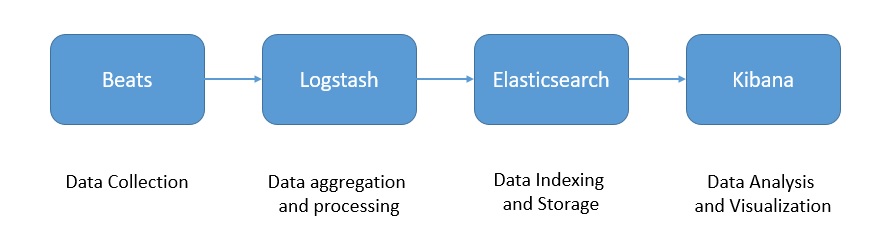
Logstash — это агрегатор журналов, который собирает данные из различных источников ввода . Он также выполняет различные преобразования и улучшения и отправляет их в пункт назначения вывода. Поскольку Logstash занимает больше места, у нас есть Beats , которые являются легкими поставщиками данных, которые мы можем установить в качестве агентов на наших серверах. Наконец, Kibana — это слой визуализации, работающий поверх Elasticsearch .
Вместе эти продукты предлагают полный набор для сбора, обработки, хранения и анализа данных журналов:
С помощью этих продуктов мы можем создать конвейер данных производственного уровня для наших данных журналов. Однако вполне возможно, а в некоторых случаях и необходимо расширить эту архитектуру для обработки больших объемов данных журналов. Мы можем разместить буфер, такой как Kafka , перед Logstash, чтобы предотвратить его перегрузку нижестоящими компонентами. Elastic Stack достаточно гибок в этом отношении.
9.2. Установка и инструменты
Эластичный стек, как мы видели ранее, состоит из нескольких продуктов. Мы можем, конечно, установить их самостоятельно. Однако это отнимает много времени. К счастью, Elastic предоставляет официальные образы Docker, чтобы упростить эту задачу.
Запустить кластер Elasticsearch с одним узлом так же просто, как запустить команду Docker:
docker run -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:7.13.0
Точно так же установить Kibana и подключить его к кластеру Elasticsearch довольно просто:
docker run -p 5601:5601 \
-e "ELASTICSEARCH_HOSTS=http://localhost:9200" \
docker.elastic.co/kibana/kibana:7.13.0
Установка и настройка Logstash немного сложнее, так как мы должны предоставить необходимые настройки и конвейер для обработки данных. Один из самых простых способов добиться этого — создать собственное изображение поверх официального изображения:
FROM docker.elastic.co/logstash/logstash:7.13.0
RUN rm -f /usr/share/logstash/pipeline/logstash.conf
ADD pipeline/ /usr/share/logstash/pipeline/
ADD config/ /usr/share/logstash/config/
Давайте посмотрим на пример файла конфигурации для Logstash, который интегрируется с Elasticsearch и Beats:
input {
tcp {
port => 4560
codec => json_lines
}
beats {
host => "127.0.0.1"
port => "5044"
}
}
output{
elasticsearch {
hosts => ["localhost:9200"]
index => "app-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
stdout { codec => rubydebug }
}
В зависимости от источника данных доступно несколько типов битов. В нашем примере мы будем использовать файл Filebeat. Установку и настройку Beats лучше всего выполнять с помощью пользовательского образа:
FROM docker.elastic.co/beats/filebeat:7.13.0
COPY filebeat.yml /usr/share/filebeat/filebeat.yml
USER root
RUN chown root:filebeat /usr/share/filebeat/filebeat.yml
USER filebeat
Давайте посмотрим на образец filebeat.yml для приложения Spring Boot:
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/math-service.log
output.logstash:
hosts: ["localhost:5044"]
Это очень беглое, но полное объяснение установки и настройки Elastic Stack. Это выходит за рамки этого урока, чтобы вдаваться во все детали.
9.3. Анализ журнала
Kibana предоставляет очень интуитивно понятный и мощный инструмент визуализации наших журналов. Мы можем получить доступ к интерфейсу Kibana по его URL-адресу по умолчанию, http://localhost:5601. Мы можем выбрать визуализацию и создать панель управления для нашего приложения.
Давайте посмотрим пример панели инструментов:
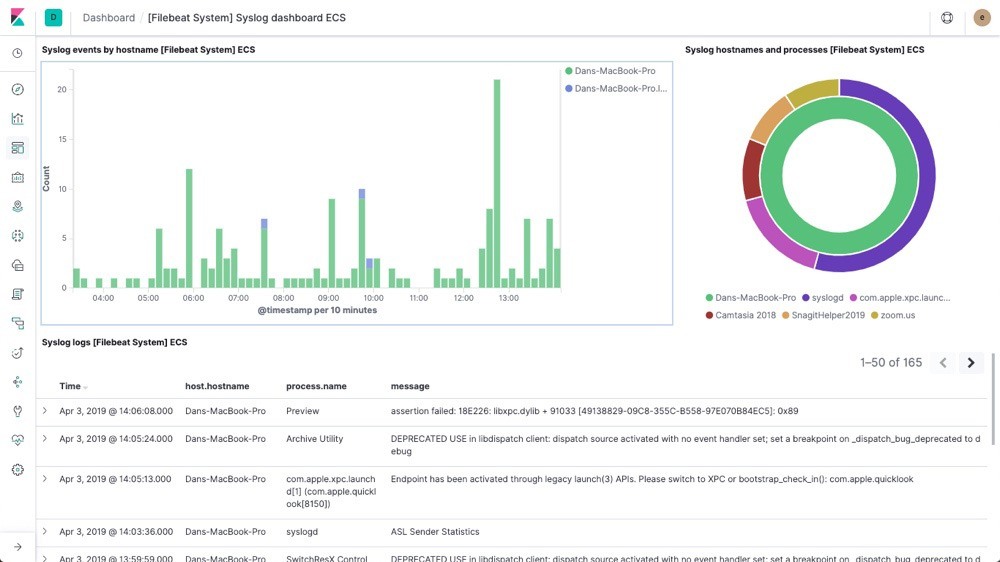
Kibana предлагает довольно широкие возможности для запроса и фильтрации данных журнала. Это выходит за рамки данного руководства.
10. Будущее наблюдаемости
Теперь мы поняли, почему наблюдаемость является ключевой проблемой для распределенных систем. Мы также рассмотрели некоторые популярные варианты обработки различных типов данных телеметрии, которые позволяют добиться наблюдаемости. Однако факт остается фактом: собрать все части по-прежнему довольно сложно и требует много времени . Нам приходится обрабатывать много разных продуктов.
Одним из ключевых достижений в этой области является OpenTelemetry , проект-песочница в CNCF. По сути, OpenTelemetry была сформирована путем тщательного слияния проектов OpenTracing и OpenCensus . Очевидно, это имеет смысл, поскольку нам придется иметь дело только с одной абстракцией и для трасс, и для метрик.
Более того, у OpenTelemetry есть план по поддержке журналов и превращению их в полноценную основу для наблюдения за распределенными системами. Кроме того, OpenTelemetry поддерживает несколько языков и хорошо интегрируется с популярными платформами и библиотеками. Кроме того, OpenTelemetry обратно совместим с OpenTracing и OpenCensus через программные мосты.
OpenTelemetry все еще находится в разработке, и мы можем ожидать, что в ближайшие дни она станет более зрелой. Между тем, чтобы облегчить нашу боль, несколько платформ наблюдения объединяют многие из продуктов, обсуждавшихся ранее, чтобы обеспечить бесперебойную работу . Например, Logz.io сочетает в себе мощь ELK, Prometheus и Jaeger, предлагая масштабируемую платформу как услугу.
Сфера наблюдаемости быстро развивается , и на рынок выходят новые продукты с инновационными решениями . Например, Micrometer обеспечивает независимый от поставщика фасад поверх клиентов контрольно-измерительных приборов для нескольких систем мониторинга. Недавно OpenMetrics выпустила свою спецификацию для создания стандарта де-факто для передачи облачных метрик в масштабе.
11. Заключение
В этом уроке мы рассмотрели основы наблюдаемости и ее значение в распределенной системе. Мы также реализовали несколько популярных сегодня опций для достижения наблюдаемости в простой распределенной системе.
Это позволило нам понять, как OpenTracing, OpenCensus и ELK могут помочь нам создать наблюдаемую программную систему. Наконец, мы обсудили некоторые новые разработки в этой области и то, как мы можем ожидать роста и развития наблюдаемости в будущем.