1. Введение
В этой статье мы собираемся изучить распределенную базу данных Fauna . Мы увидим, какие функции он привносит в наши приложения, что мы можем с ним делать и как с ним взаимодействовать.
2. Что такое фауна?
Fauna — это мультипротокольная, мультимодельная, многопользовательская, распределенная, транзакционная база данных как услуга (DBaaS). Звучит сложно, поэтому давайте немного разберемся.
2.1. База данных как услуга
«База данных как услуга» означает, что база данных размещается у облачного провайдера, который заботится обо всей инфраструктуре и обслуживании, так что нам остается иметь дело только с деталями, специфичными для нашего домена — коллекциями, индексами, запросами, и т. д. Это помогает значительно упростить управление такой системой, сохраняя при этом преимущества ее функций.
2.2. Распределенная транзакционная база данных
Распределенность означает, что база данных работает на нескольких серверах. Это помогает сделать его более эффективным и в то же время более отказоустойчивым. Если один сервер выйдет из строя, то вся база данных сможет продолжать работать корректно.
Транзакционная база данных означает, что база данных предлагает надежные гарантии достоверности данных. Обновления данных, выполняемые в рамках одной транзакции, либо завершаются успешно, либо завершаются неудачей в целом, без риска оставить данные в частичном состоянии.
В качестве дополнительной меры Fauna предлагает уровни изоляции, которые гарантируют, что результат воспроизведения нескольких транзакций на нескольких распределенных узлах всегда будет правильным. Это важное соображение для распределенных баз данных — в противном случае возможно, что разные транзакции будут воспроизводиться по-разному на разных узлах и в конечном итоге приведут к разным результатам.
Например, рассмотрим следующие транзакции, применяемые к одной и той же записи:
- Установите значение «15»
- Увеличьте значение на «3»
Если они воспроизведены в указанном порядке, конечный результат будет «18». Однако, если они воспроизведены в обратном порядке, конечный результат будет «15». Это еще больше сбивает с толку, если результат отличается на разных узлах в одной и той же системе, поскольку это означает, что наши данные будут несогласованными между узлами.
2.3. Мультимодельная база данных
База данных с несколькими моделями означает, что она позволяет нам моделировать различные типы данных по-разному , все в рамках одного и того же ядра базы данных и доступ к которым осуществляется через одни и те же соединения.
Внутри Fauna представляет собой базу данных документов. Это означает, что он хранит каждую запись как структурированный документ с произвольной формой, представленной в JSON. Это позволяет Fauna действовать как хранилище ключей и значений — в документе просто есть одно поле, значение — или как табличное хранилище — в документе столько полей, сколько необходимо, но все они плоские. Однако мы также можем хранить более сложные документы с вложенными полями, массивами и т. д.:
// Key-Value document
{
"value": "ForEach"
}
// Tabular document
{
"name": "ForEach",
"url": "https://www.foreach.com/"
}
// Structured document
{
"name": "ForEach",
"sites": [
{
"id": "cs",
"name": "Computer Science",
"url": "https://www.foreach.com/cs"
},
{
"id": "linux",
"name": "Linux",
"url": "https://www.foreach.com/linux"
},
{
"id": "scala",
"name": "Scala",
"url": "https://www.foreach.com/scala"
},
{
"id": "kotlin",
"name": "Kotlin",
"url": "https://www.foreach.com/kotlin"
},
]
}
Кроме того, у нас также есть доступ к некоторым функциям, характерным для реляционных баз данных. В частности, мы можем создавать индексы для наших документов, чтобы сделать запросы более эффективными, применять ограничения к нескольким коллекциям, чтобы гарантировать согласованность данных, и выполнять запросы, охватывающие несколько коллекций за один раз.
Механизм запросов Fauna также поддерживает графовые запросы, что позволяет нам создавать сложные структуры данных, охватывающие несколько коллекций, и получать к ним доступ, как если бы они были одним графом данных.
Наконец, в Fauna есть средства временного моделирования, которые позволяют нам взаимодействовать с нашей базой данных в любой момент ее существования. Это означает, что мы можем не только видеть все изменения, произошедшие с записями с течением времени, но и напрямую обращаться к данным, какими они были в данный момент времени.
2.4. Многопользовательская база данных
Мультитенантный сервер базы данных означает, что он поддерживает несколько разных баз данных, используемых разными пользователями. Это очень распространено в механизмах баз данных, используемых для облачного хостинга, поскольку это означает, что один сервер может поддерживать множество разных клиентов.
Фауна берет это немного в другом направлении. Вместо того, чтобы разные арендаторы представляли разных клиентов в одном установленном ядре базы данных, Fauna использует арендаторов для представления разных подмножеств данных для одного клиента.
Можно создавать базы данных, которые сами являются потомками других баз данных. Затем мы можем создать учетные данные для доступа к этим дочерним базам данных. Однако отличие Fauna заключается в том, что мы можем выполнять запросы только для чтения к данным из дочерних баз данных той, к которой мы подключены. Однако получить доступ к данным в родительских или одноуровневых базах данных невозможно.
Это позволяет нам создавать дочерние базы данных для разных служб в одной и той же родительской базе данных, а затем пользователи-администраторы могут запрашивать все данные за один раз — это может быть удобно для целей аналитики.
2.5. Многопротокольная база данных
Это означает, что у нас есть несколько разных способов доступа к одним и тем же данным.
Стандартный способ доступа к нашим данным — использование языка запросов Fauna (FQL) через один из предоставленных драйверов. Это дает нам доступ ко всем возможностям ядра базы данных, позволяя нам получать доступ ко всем данным любым способом, который нам нужен.
Кроме того, Fauna также предоставляет конечную точку GraphQL, которую мы можем использовать. Преимущество этого в том, что мы можем использовать его из любого приложения, независимо от языка программирования, а не в зависимости от специальных драйверов для нашего языка. Однако не все функции доступны через этот интерфейс. В частности, нам необходимо заранее создать схему GraphQL, описывающую форму наших данных, а это означает, что мы не можем иметь в одной коллекции разные записи с разными формами.
3. Создание базы данных фауны
Теперь, когда мы знаем, что Fauna может сделать для нас, давайте на самом деле создадим базу данных для использования.
Если у нас еще нет учетной записи, нам нужно ее создать .
После того, как мы вошли в систему, на панели инструментов мы просто нажимаем ссылку «Создать базу данных»:
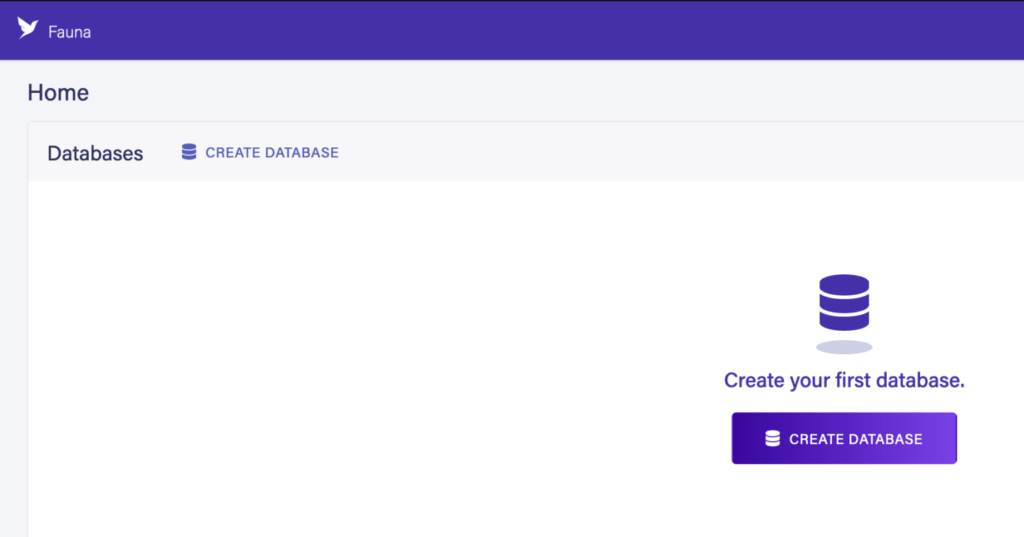
Затем открывается панель для имени и региона базы данных. У нас также есть возможность предварительно заполнить базу данных некоторыми примерами данных, чтобы увидеть, как она может работать, чтобы помочь нам привыкнуть к системе:
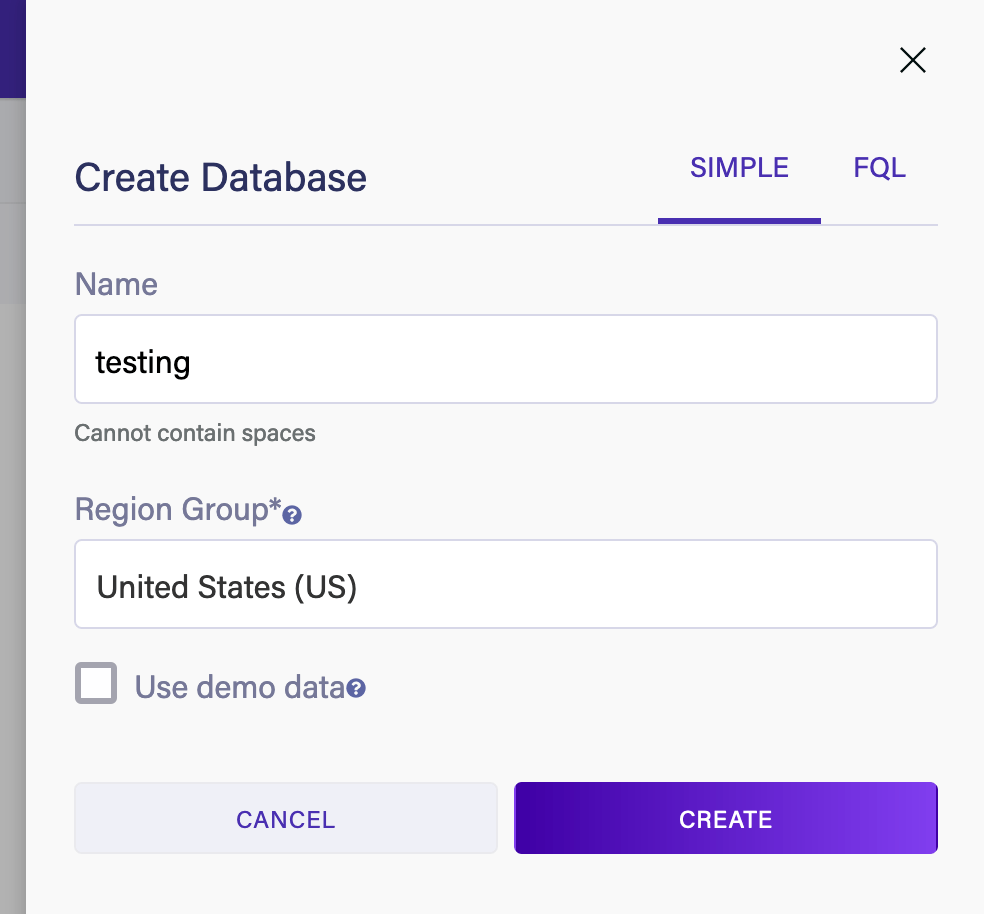
На этом экране выбор «Группы регионов» важен как для суммы, которую нам придется заплатить за все, что превышает бесплатные лимиты, так и для конечных точек, которые нам нужно использовать для подключения к базе данных извне.
Как только мы это сделали, у нас есть полная база данных, которую мы можем использовать по мере необходимости. Если мы выбрали демонстрационные данные, то они поставляются с некоторыми заполненными коллекциями, индексами, пользовательскими функциями и схемой GraphQL. Если нет, то база данных полностью пуста и готова для создания нужной нам структуры:
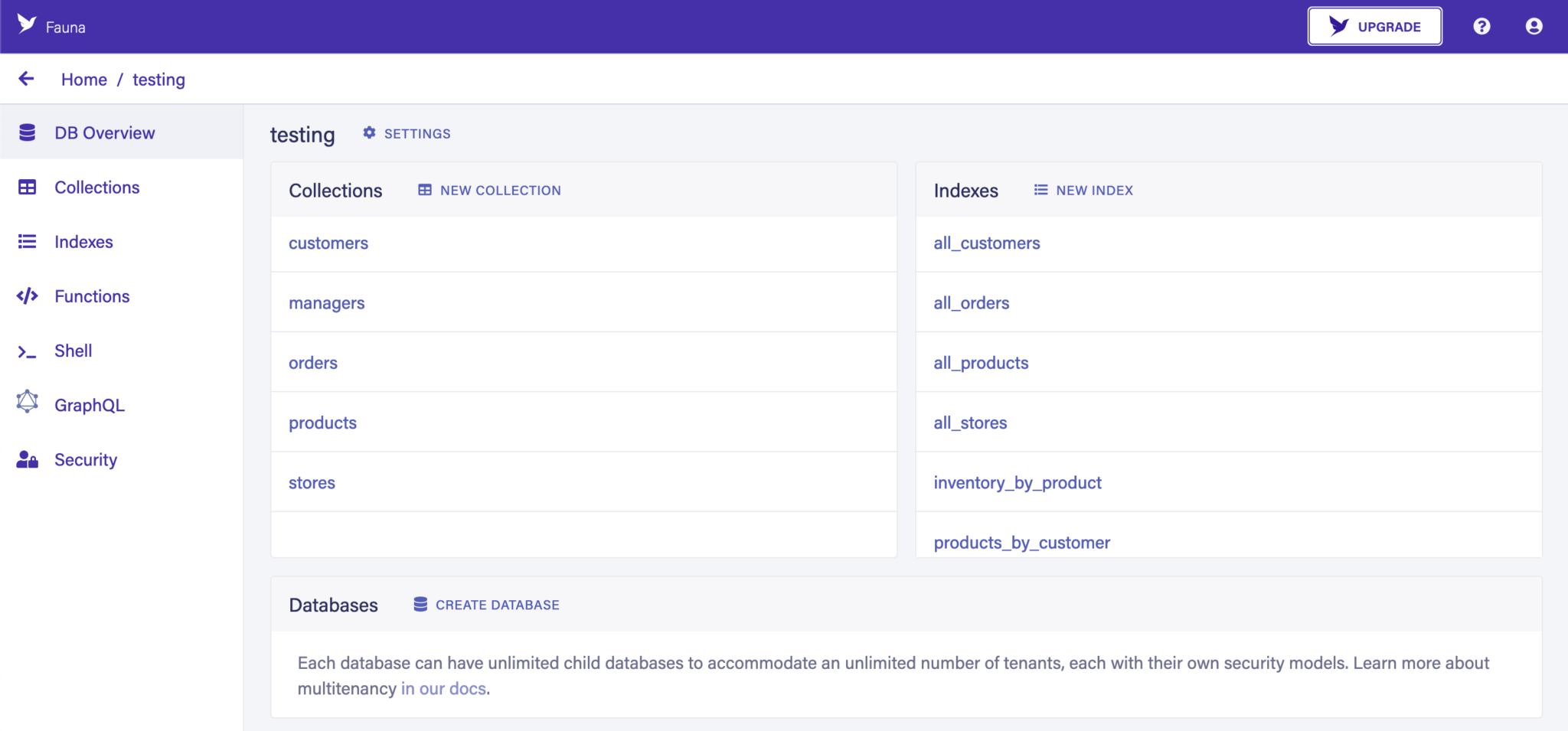
Наконец, чтобы подключиться к базе данных извне, нам нужен ключ аутентификации. Мы можем создать его на вкладке «Безопасность» на боковой панели:
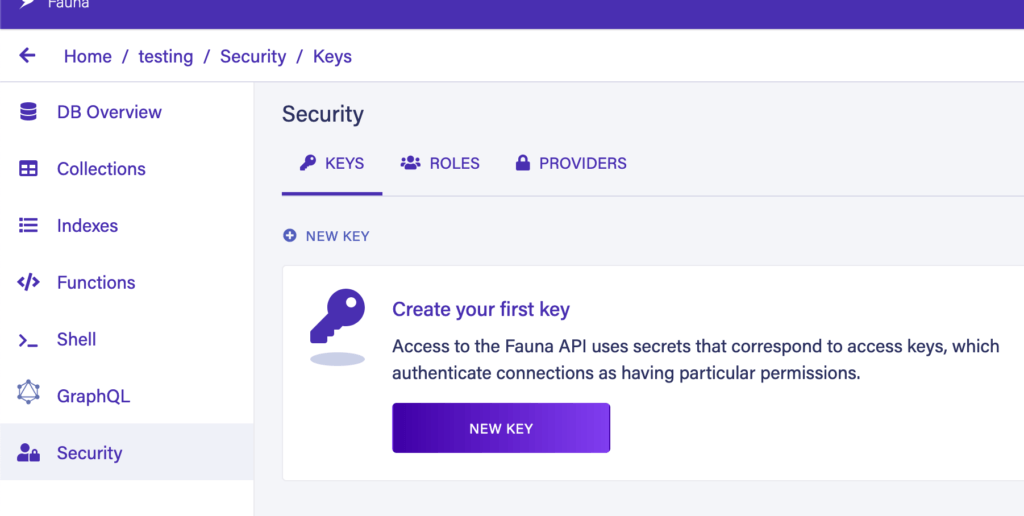
При создании нового ключа обязательно скопируйте его, потому что из соображений безопасности невозможно получить его обратно после закрытия экрана.
4. Взаимодействие с фауной
Теперь, когда у нас есть база данных, мы можем начать с ней работать.
Fauna предлагает два различных способа чтения и записи данных в нашу базу данных извне: драйверы FQL и API GraphQL. У нас также есть доступ к Fauna Shell, которая позволяет нам выполнять произвольные команды из веб-интерфейса.
4.1. Раковина фауны
Оболочка Fauna позволяет нам выполнять любые команды из веб-интерфейса. Мы можем сделать это, используя любой из наших настроенных ключей — действуя точно так же, как если бы мы подключились извне с помощью этого ключа — или же как определенные специальные подключения администратора:
Это позволяет нам исследовать наши данные и тестировать запросы, которые мы хотим использовать из нашего приложения, с минимальными усилиями.
4.2. Соединение с FQL
Если мы хотим вместо этого подключить наше приложение к Fauna и использовать FQL, нам нужно использовать один из предоставленных драйверов , в том числе для Java и Scala.
Драйверы Java требуют, чтобы мы работали на Java 11 или выше.
Первое, что нам нужно сделать, это добавить зависимость. Если мы используем Maven, мы просто добавим его в наш файл pom.xml :
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>
Затем нам нужно создать клиентское соединение, которое мы можем использовать для связи с базой данных:
FaunaClient client = FaunaClient.builder()
.withEndpoint("https://db.us.fauna.com/")
.withSecret("put-your-authorization-key-here")
.build();
Обратите внимание, что нам нужно указать правильные значения для конечной точки базы данных, которые зависят от группы регионов, выбранной при создании базы данных, и секретного ключа, который мы создали ранее.
Этот клиент будет действовать как пул соединений, открывая новые соединения с базой данных по мере необходимости для различных запросов. Это означает, что мы можем создать его один раз в начале нашего приложения и повторно использовать столько раз, сколько нам нужно.
Если нам нужно подключиться к разным секретам, это должны быть разные клиенты. Например, если мы хотим взаимодействовать с несколькими разными дочерними базами данных в одной и той же родительской базе данных.
Теперь, когда у нас есть клиент, мы можем использовать его для отправки запросов в базу данных:
client.query(
language.Get(language.Ref(language.Collection("customers"), 101))
).get();
4.3. Соединение с GraphQL
Fauna предлагает полный API GraphQL для взаимодействия с нашей базой данных. Это может позволить нам использовать базу данных без каких-либо специальных драйверов, не требуя ничего, кроме HTTP-клиента.
Чтобы использовать поддержку GraphQL, нам нужно сначала создать схему GraphQL. Это определит саму схему и то, как она сопоставляется с нашими уже существующими конструкциями базы данных Fauna, такими как коллекции, индексы и функции. После этого любой клиент, поддерживающий GraphQL, или даже просто HTTP-клиент, такой как RestTemplate , можно использовать для вызова нашей базы данных.
Обратите внимание, что это позволит нам взаимодействовать только с данными в нашей базе данных. Если мы хотим использовать какие-либо административные команды, такие как создание новых коллекций или индексов, то для этого требуется либо команда FQL, либо пользовательский интерфейс веб-администратора.
Для подключения к Fauna через GraphQL требуется, чтобы мы использовали правильный URL-адрес — https://graphql.us.fauna.com/graphql для региона США — и предоставили наш ключ аутентификации в качестве токена носителя в заголовке авторизации . На этом этапе мы можем использовать его как любую обычную конечную точку GraphQL, отправив запросы POST к URL-адресу и предоставив запрос или мутацию в теле, необязательно с любыми переменными для использования с ними.
5. Использование фауны из весны
Теперь, когда мы понимаем, что такое Fauna и как ее использовать, мы можем увидеть, как интегрировать ее в наши приложения Spring.
У Fauna нет родных драйверов Spring. Вместо этого мы будем настраивать обычные драйверы Java как компоненты Spring для использования в нашем приложении.
5.1. Конфигурация фауны
Прежде чем мы сможем использовать фауну, нам нужна некоторая конфигурация. В частности, нам нужно знать регион, в котором находится наша база данных фауны, из которого мы можем затем получить соответствующие URL-адреса, и нам нужно знать секрет, который мы можем использовать для подключения к базе данных.
Для этого мы добавим свойства для фауны.регион и фауна.секрет в наш файл application.properties — или любой другой поддерживаемый метод конфигурации Spring :
fauna.region=us
fauna.secret=FaunaSecretHere
Обратите внимание, что здесь мы определяем регион фауны вместо URL-адресов. Это позволяет нам правильно получить URL-адрес для FQL и GraphQL из одной и той же настройки. Это позволяет избежать риска того, что мы можем настроить два URL-адреса по-разному.
5.2. FQL-клиент
Если мы планируем использовать FQL из нашего приложения, мы можем добавить bean-компонент FaunaClient в контекст Spring. Это потребует создания объекта конфигурации Spring для использования соответствующих свойств и создания объекта FaunaClient :
@Configuration
class FaunaClientConfiguration {
@Value("https://db.${fauna.region}.fauna.com/")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
@Bean
FaunaClient getFaunaClient() throws MalformedURLException {
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}
}
Это позволяет нам использовать FaunaClient напрямую из любого места нашего приложения, точно так же, как мы использовали бы JdbcTemplate для доступа к базе данных JDBC. У нас также есть возможность обернуть это в объект более высокого уровня, чтобы работать в терминах, специфичных для предметной области, если мы того пожелаем.
5.3. GraphQL-клиент
Если мы планируем использовать GraphQL для доступа к фауне, потребуется немного больше работы. Стандартного клиента для вызова API GraphQL не существует. Вместо этого мы будем использовать Spring RestTemplate для выполнения стандартных HTTP-запросов к конечной точке GraphQL. Более новый WebClient будет работать так же хорошо, если мы создадим приложение на основе WebFlux.
Для этого мы напишем класс, который обертывает RestTemplate и может выполнять соответствующие HTTP-вызовы для Fauna:
@Component
public class GraphqlClient {
@Value("https://graphql.${fauna.region}.fauna.com/graphql")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
private RestTemplate restTemplate = new RestTemplate();
public <T> T query(String query, Class<T> cls) {
return query(query, Collections.emptyMap(), cls);
}
public <T, V> T query(String query, V variables, Class<T> cls) {
var body = Map.of("query", query, "variables", variables);
var request = RequestEntity.post(faunaUrl)
.header("Authorization", "Bearer " + faunaSecret)
.body(body);
var response = restTemplate.exchange(request, cls);
return response.getBody();
}
}
Этот клиент позволяет нам совершать GraphQL-вызовы Fauna из других компонентов нашего приложения. У нас есть два метода: один просто берет строку запроса GraphQL, а другой дополнительно берет некоторые переменные для использования с ней.
Они также оба принимают тип для десериализации результата запроса. Это позволит обрабатывать все детали общения с фауной, позволяя вместо этого сосредоточиться на потребностях нашего приложения.
6. Резюме
В этой статье мы кратко познакомились с базой данных Fauna, увидели некоторые из ее функций, которые могут сделать ее очень убедительным выбором для нашего следующего проекта , а также увидели, как мы можем взаимодействовать с ней из нашего приложения.
Почему бы не изучить некоторые функции, которые мы здесь упомянули, в вашем следующем проекте?