1. Введение
В этой статье мы собираемся создать серверную часть службы блогов на основе службы базы данных Fauna с использованием Spring и Java 17.
2. Настройка проекта
У нас есть некоторые начальные шаги по настройке, которые нам нужно выполнить, прежде чем мы сможем начать создавать наш сервис, в частности, нам нужно создать базу данных Fauna и пустое приложение Spring.
2.1. Создание базы данных фауны
Прежде чем начать, нам понадобится база данных Fauna для работы. Если у нас ее еще нет, нам нужно создать новую учетную запись в Fauna .
Как только это будет сделано, мы можем создать новую базу данных. Дайте ему имя и регион и не включайте демо-данные, поскольку мы хотим создать собственную схему:
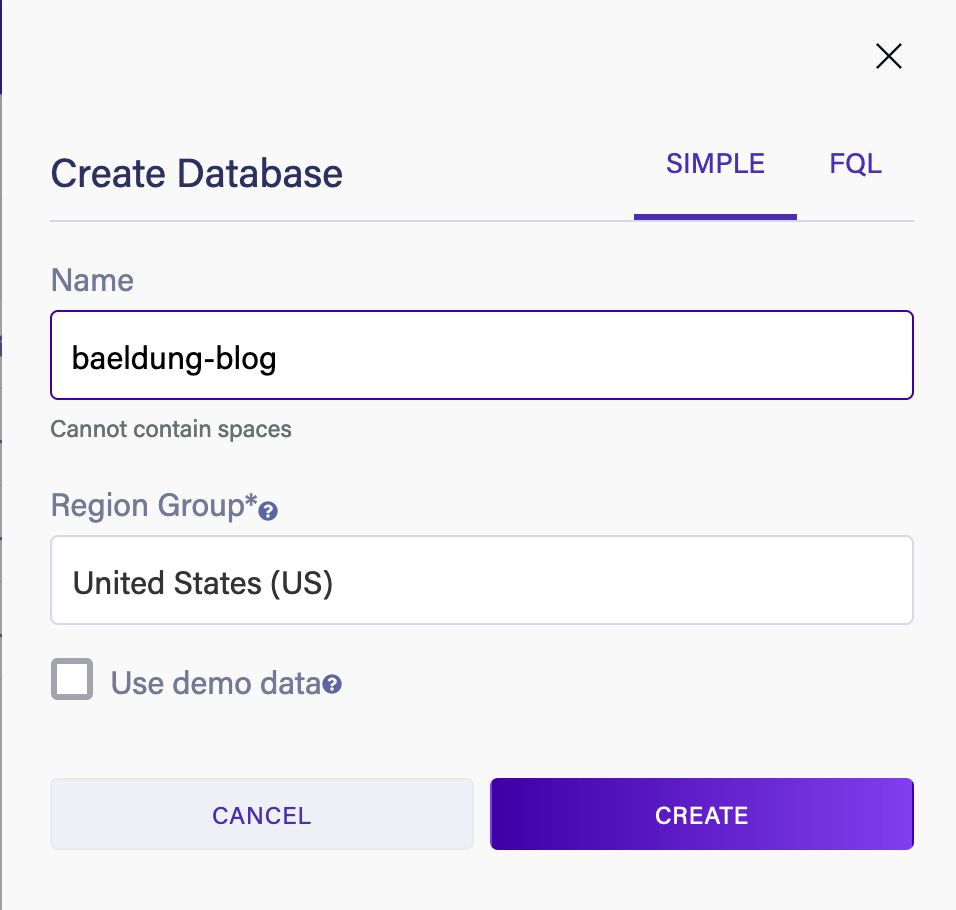
Далее нам нужно создать ключ безопасности для доступа к этому из нашего приложения. Мы можем сделать это на вкладке «Безопасность» в нашей базе данных:
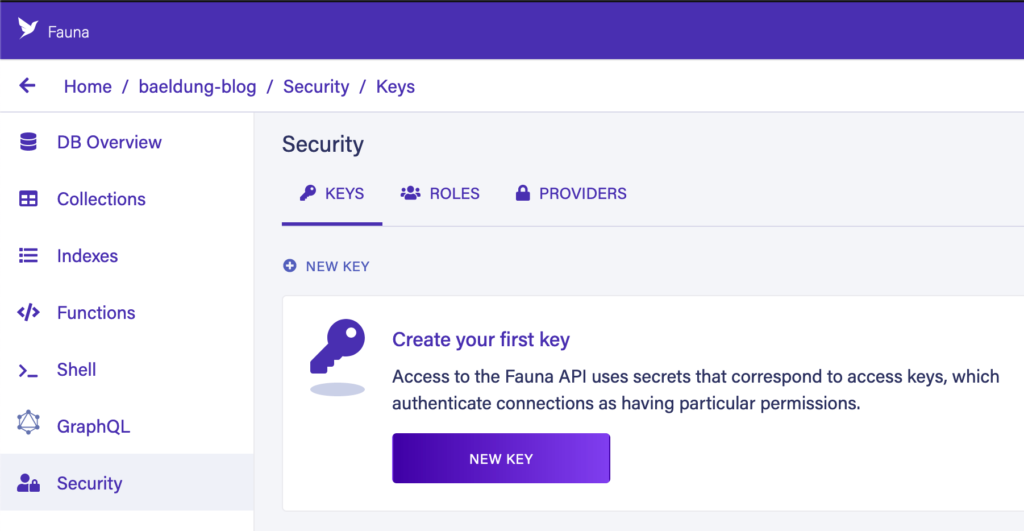
Здесь нам нужно выбрать «Роль» «Сервер» и, при желании, дать ключу имя. Это означает, что ключ может получить доступ к этой базе данных, но только к этой базе данных. Кроме того, у нас есть опция «Администратор», которую можно использовать для доступа к любой базе данных в нашей учетной записи:
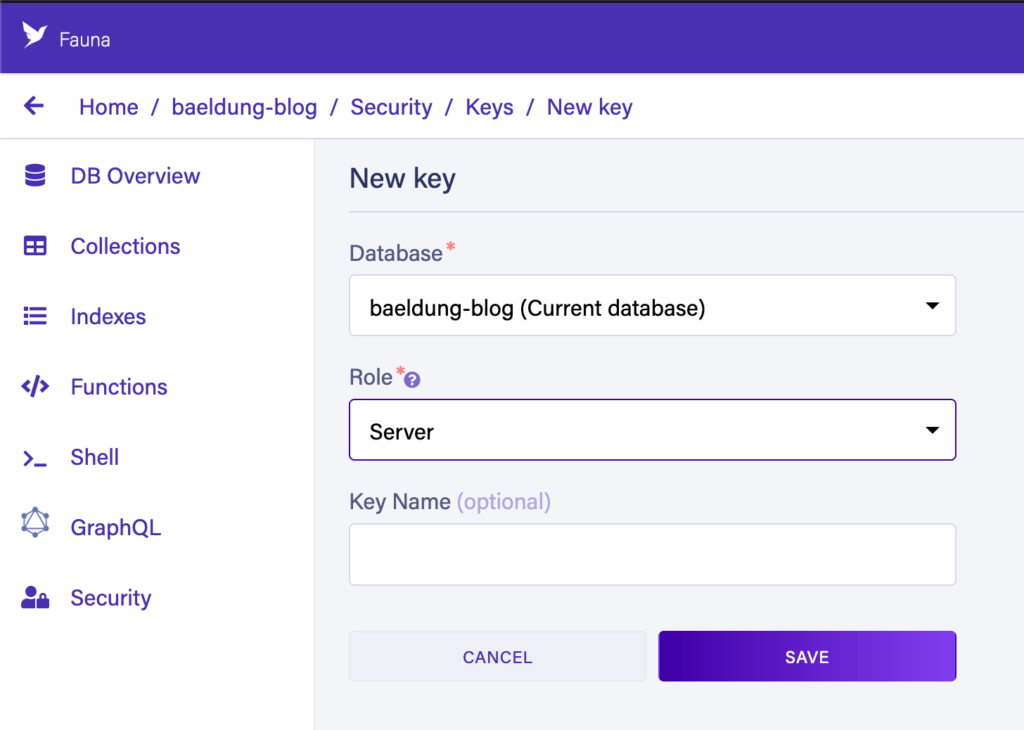
Когда это будет сделано, нам нужно записать наш секрет . Это необходимо для доступа к услуге, но его нельзя будет получить снова, как только мы покинем эту страницу, по соображениям безопасности .
2.2. Создание приложения Spring
Когда у нас есть наша база данных, мы можем создать наше приложение. Поскольку это будет веб-приложение Spring, лучше всего загрузить его из Spring Initializr .
Мы хотим выбрать параметры для создания проекта Maven с использованием последней версии Spring и последней версии Java LTS — на момент написания это были Spring 2.6.2 и Java 17. Мы также хотим выбрать Spring Web и Spring. Безопасность как зависимости для нашего сервиса:
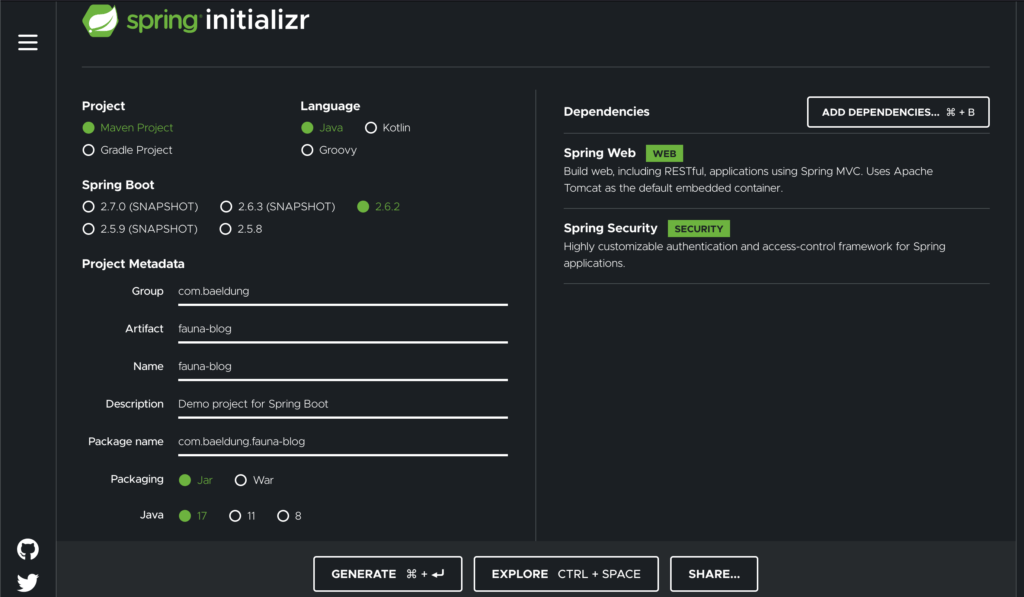
Как только мы закончим здесь, мы можем нажать кнопку «Создать», чтобы загрузить наш стартовый проект.
Далее нам нужно добавить драйверы Fauna в наш проект. Это делается путем добавления зависимости от них в сгенерированный файл pom.xml :
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>
На этом этапе мы должны выполнить mvn install , и сборка успешно загрузит все, что нам нужно.
2.3. Настройка клиента фауны
Когда у нас есть веб-приложение Spring для работы, нам понадобится клиент Fauna для использования базы данных.
Во-первых, нам нужно выполнить некоторые настройки. Для этого мы добавим два свойства в наш файл application.properties , предоставив правильные значения для нашей базы данных:
fauna.region=us
fauna.secret=<Secret>
Затем нам понадобится новый класс конфигурации Spring для создания клиента Fauna:
@Configuration
class FaunaConfiguration {
@Value("https://db.${fauna.region}.fauna.com/")
private String faunaUrl;
@Value("${fauna.secret}")
private String faunaSecret;
@Bean
FaunaClient getFaunaClient() throws MalformedURLException {
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}
}
Это делает экземпляр FaunaClient доступным для контекста Spring для использования другими bean-компонентами.
3. Добавление поддержки для пользователей
Прежде чем добавлять поддержку сообщений в наш API, нам нужна поддержка пользователей, которые будут их создавать. Для этого мы воспользуемся Spring Security и подключим его к коллекции Fauna, представляющей записи пользователей.
3.1. Создание коллекции пользователей
Первое, что мы хотим сделать, это создать коллекцию. Это можно сделать, перейдя на экран «Коллекции» в нашей базе данных, нажав кнопку «Новая коллекция» и заполнив форму. В этом случае мы хотим создать коллекцию «users» с настройками по умолчанию:
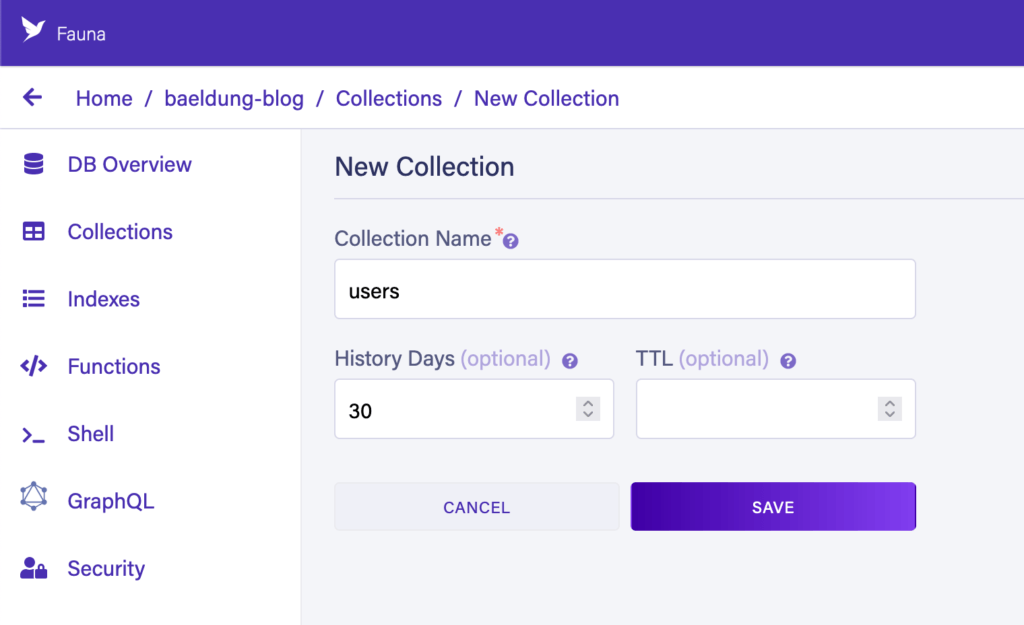
Далее мы добавим запись пользователя. Для этого мы нажимаем кнопку «Новый документ» в нашей коллекции и предоставляем следующий JSON:
{
"username": "foreach",
"password": "Pa55word",
"name": "ForEach"
}
Обратите внимание, что здесь мы храним пароли в виде открытого текста. Имейте в виду, что это ужасная практика, и она делается только для удобства этого урока.
Наконец, нам нужен индекс. Каждый раз, когда мы хотим получить доступ к записям по любому полю, кроме ссылки, нам нужно создать индекс, который позволит нам это сделать. Здесь мы хотим получить доступ к записям по имени пользователя. Это делается нажатием кнопки «Новый индекс» и заполнением формы:
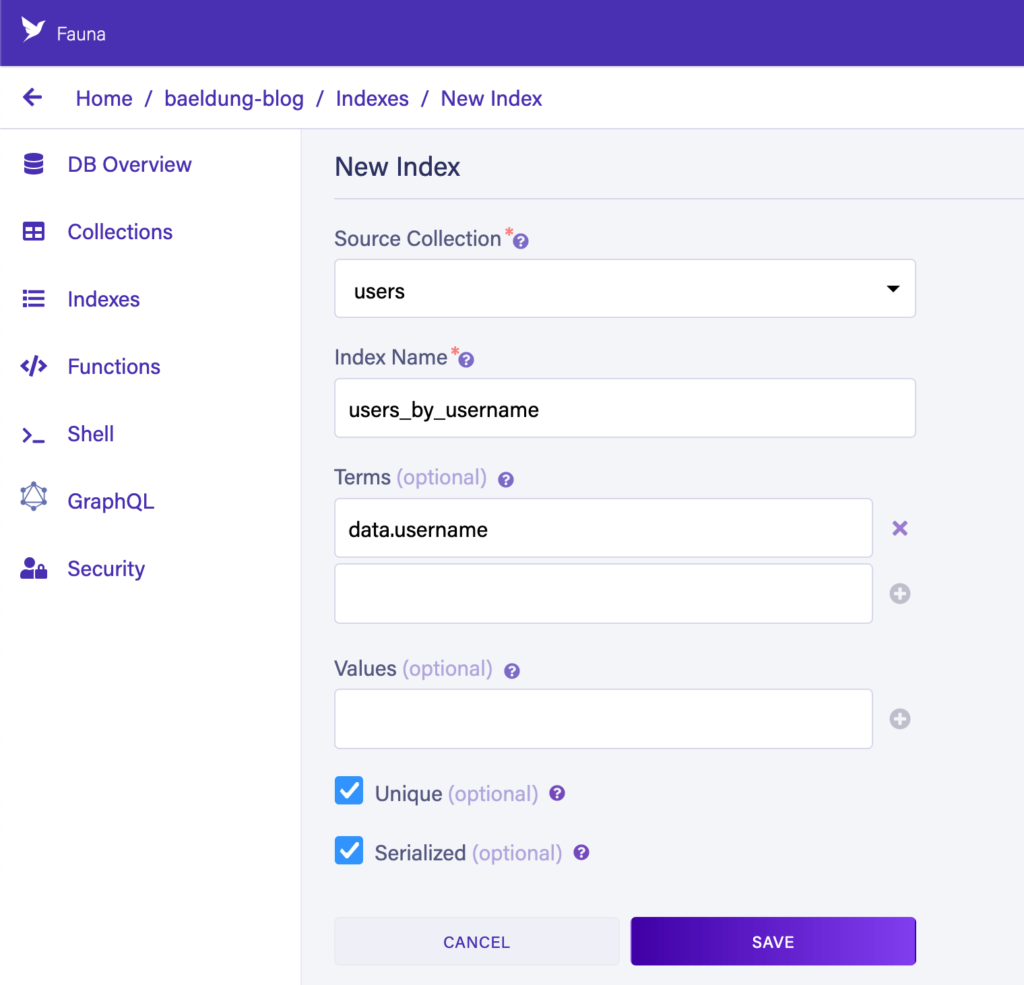
Теперь мы сможем писать FQL-запросы, используя индекс «users_by_username» для поиска наших пользователей. Например:
Map(
Paginate(Match(Index("users_by_username"), "foreach")),
Lambda("user", Get(Var("user")))
)
Приведенное выше вернет запись, которую мы создали ранее.
3.2. Аутентификация против фауны
Теперь, когда у нас есть коллекция пользователей в Fauna, мы можем настроить Spring Security для аутентификации против этого.
Для этого нам сначала понадобится UserDetailsService , который сравнивает пользователей с фауной:
public class FaunaUserDetailsService implements UserDetailsService {
private final FaunaClient faunaClient;
// standard constructors
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
try {
Value user = faunaClient.query(Map(
Paginate(Match(Index("users_by_username"), Value(username))),
Lambda(Value("user"), Get(Var("user")))))
.get();
Value userData = user.at("data").at(0).orNull();
if (userData == null) {
throw new UsernameNotFoundException("User not found");
}
return User.withDefaultPasswordEncoder()
.username(userData.at("data", "username").to(String.class).orNull())
.password(userData.at("data", "password").to(String.class).orNull())
.roles("USER")
.build();
} catch (ExecutionException | InterruptedException e) {
throw new RuntimeException(e);
}
}
}
Далее нам нужна некоторая конфигурация Spring для ее настройки. Это стандартная конфигурация Spring Security для подключения вышеуказанного UserDetailsService :
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class WebSecurityConfiguration extends WebSecurityConfigurerAdapter {
@Autowired
private FaunaClient faunaClient;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable();
http.authorizeRequests()
.antMatchers("/**").permitAll()
.and().httpBasic();
}
@Bean
@Override
public UserDetailsService userDetailsService() {
return new FaunaUserDetailsService(faunaClient);
}
}
На этом этапе мы можем добавить стандартные аннотации @PreAuthorize в наш код и принимать или отклонять запросы в зависимости от того, существуют ли данные аутентификации в нашей коллекции «users» в Fauna.
4. Добавление поддержки листинговых сообщений
Наша служба ведения блогов не была бы выдающейся, если бы не поддерживала концепцию сообщений. Это настоящие сообщения в блогах, которые были написаны и могут быть прочитаны другими.
4.1. Создание коллекции сообщений
Как и раньше, нам сначала нужна коллекция для хранения сообщений. Она создается так же, только называется «сообщения» вместо «пользователи». У нас будет четыре поля:
- title — название поста.
- контент — содержание поста.
- created — временная метка, когда было создано сообщение.
- authorRef — ссылка на запись «users» для автора сообщения.
Нам также понадобятся два индекса. Первый — «posts_by_author», который позволит нам искать записи «posts» с определенным автором:
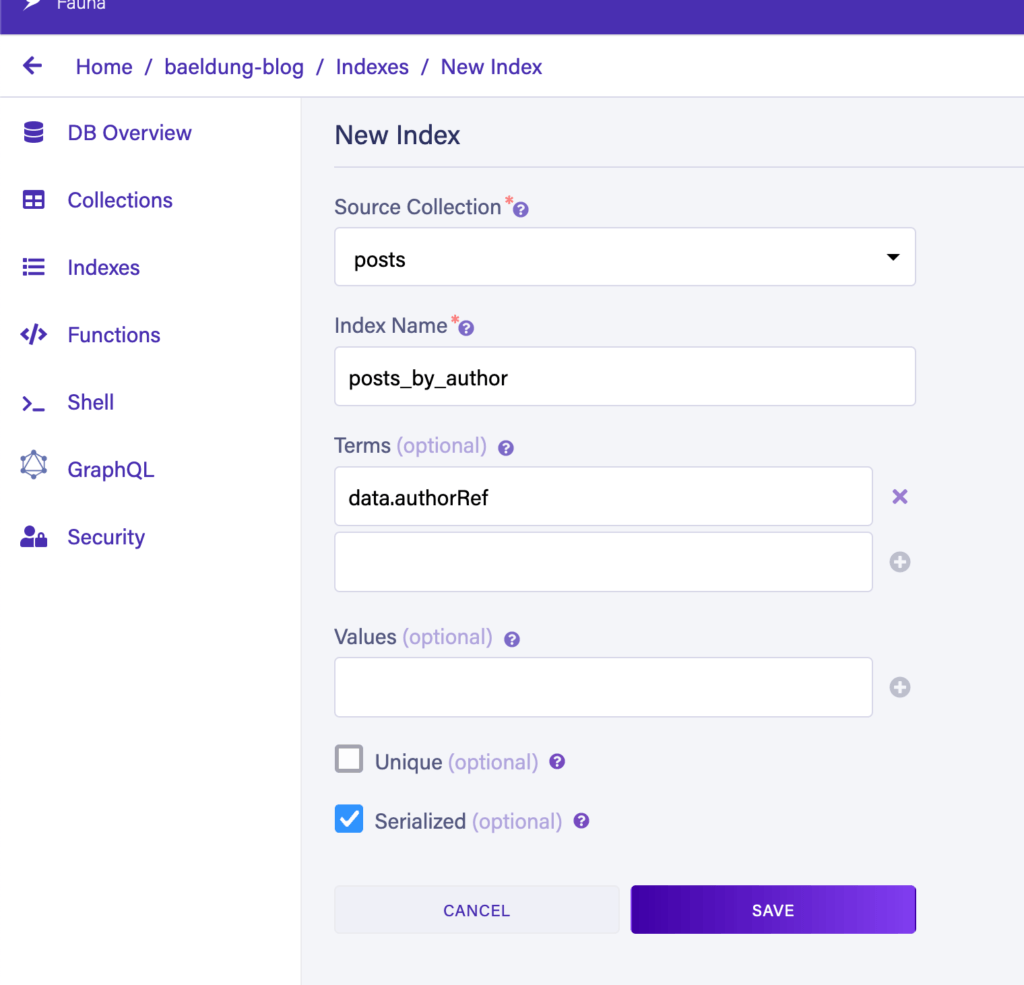
Второй индекс будет «posts_sort_by_created_desc». Это позволит нам сортировать результаты по дате создания, чтобы более свежие сообщения возвращались первыми. Нам нужно создать это по-другому, потому что это зависит от функции, недоступной в веб-интерфейсе, указывающей на то, что индекс хранит значения в обратном порядке.
Для этого нам нужно выполнить часть FQL в Fauna Shell:
CreateIndex({
name: "posts_sort_by_created_desc",
source: Collection("posts"),
terms: [ { field: ["ref"] } ],
values: [
{ field: ["data", "created"], reverse: true },
{ field: ["ref"] }
]
})
Все, что делает веб-интерфейс, можно сделать таким же образом, что позволяет лучше контролировать то, что именно делается.
Затем мы можем создать сообщение в Fauna Shell, чтобы иметь некоторые исходные данные:
Create(
Collection("posts"),
{
data: {
title: "My First Post",
contents: "This is my first post",
created: Now(),
authorRef: Select("ref", Get(Match(Index("users_by_username"), "foreach")))
}
}
)
Здесь нам нужно убедиться, что значение для «authorRef» является правильным значением из нашей записи «users», которую мы создали ранее. Мы делаем это, запрашивая индекс «users_by_username», чтобы получить ссылку, просматривая наше имя пользователя.
4.2. Служба сообщений
Теперь, когда у нас есть поддержка сообщений в Fauna, мы можем создать сервисный уровень в нашем приложении для работы с ним.
Во-первых, нам нужны некоторые записи Java для представления данных, которые мы извлекаем. Он будет состоять из класса записей Author и Post :
public record Author(String username, String name) {}
public record Post(String id, String title, String content, Author author, Instant created, Long version) {}
Теперь мы можем запустить нашу службу сообщений. Это будет компонент Spring, который обертывает FaunaClient и использует его для доступа к хранилищу данных:
@Component
public class PostsService {
@Autowired
private FaunaClient faunaClient;
}
4.3. Получение всех сообщений
Теперь в нашем PostsService мы можем реализовать метод для получения всех сообщений. На данный момент мы не собираемся беспокоиться о правильном разбиении на страницы и вместо этого используем только значения по умолчанию, что означает первые 64 документа из набора результатов.
Для этого мы добавим в наш класс PostsService следующий метод :
List<Post> getAllPosts() throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Documents(Collection("posts")),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}
Это выполняет запрос для извлечения каждого документа из коллекции «posts», отсортированного в соответствии с индексом «posts_sort_by_created_desc». Затем он применяет Lambda для создания ответа, состоящего из двух документов для каждой записи — самого сообщения и автора сообщения.
Теперь нам нужно иметь возможность преобразовать этот ответ обратно в наши объекты Post :
private Post parsePost(Value entry) {
var author = entry.at("author");
var post = entry.at("post");
return new Post(
post.at("ref").to(Value.RefV.class).get().getId(),
post.at("data", "title").to(String.class).get(),
post.at("data", "contents").to(String.class).get(),
new Author(
author.at("data", "username").to(String.class).get(),
author.at("data", "name").to(String.class).get()
),
post.at("data", "created").to(Instant.class).get(),
post.at("ts").to(Long.class).get()
);
}
Это берет один результат из нашего запроса, извлекает все его значения и создает наши более богатые объекты.
Обратите внимание, что поле «ts» представляет собой метку времени последнего обновления записи, но не относится к типу «Временная метка фауны » . Вместо этого это тип Long , представляющий количество микросекунд, прошедших с эпохи UNIX. В этом случае мы рассматриваем его как непрозрачный идентификатор версии, а не преобразовываем его в отметку времени.
4.4. Получение постов для одного автора
Мы также хотим получить все сообщения, созданные конкретным автором, а не только все сообщения, которые когда-либо были написаны. Это вопрос использования нашего индекса «posts_by_author», а не просто сопоставления каждого документа.
Мы также будем ссылаться на индекс «users_by_username» для запроса по имени пользователя вместо ссылки на запись пользователя.
Для этого добавим в класс PostsService новый метод :
List<Post> getAuthorPosts(String author) throws Exception {
var postsResult = faunaClient.query(Map(
Paginate(
Join(
Match(Index("posts_by_author"), Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))),
Index("posts_sort_by_created_desc")
)
),
Lambda(
Arr(Value("extra"), Value("ref")),
Obj(
"post", Get(Var("ref")),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Get(Var("ref"))))
)
)
)).get();
var posts = postsResult.at("data").asCollectionOf(Value.class).get();
return posts.stream().map(this::parsePost).collect(Collectors.toList());
}
4.5. Контроллер сообщений
Теперь мы можем написать наш контроллер сообщений, который позволит HTTP-запросам к нашему сервису получать сообщения. Это прослушает URL-адрес «/posts» и вернет либо все сообщения, либо сообщения для одного автора, в зависимости от того, указан ли параметр «автор»:
@RestController
@RequestMapping("/posts")
public class PostsController {
@Autowired
private PostsService postsService;
@GetMapping
public List<Post> listPosts(@RequestParam(value = "author", required = false) String author)
throws Exception {
return author == null
? postsService.getAllPosts()
: postsService.getAuthorPosts(author);
}
}
На этом этапе мы можем запустить наше приложение и сделать запросы к /posts или /posts?author=foreach и получить результаты:
[
{
"author": {
"name": "ForEach",
"username": "foreach"
},
"content": "Introduction to FaunaDB with Spring",
"created": "2022-01-25T07:36:24.563534Z",
"id": "321742264960286786",
"title": "Introduction to FaunaDB with Spring",
"version": 1643096184600000
},
{
"author": {
"name": "ForEach",
"username": "foreach"
},
"content": "This is my second post",
"created": "2022-01-25T07:34:38.303614Z",
"id": "321742153548038210",
"title": "My Second Post",
"version": 1643096078350000
},
{
"author": {
"name": "ForEach",
"username": "foreach"
},
"content": "This is my first post",
"created": "2022-01-25T07:34:29.873590Z",
"id": "321742144715882562",
"title": "My First Post",
"version": 1643096069920000
}
]
5. Создание и обновление сообщений
На данный момент у нас есть полностью доступный только для чтения сервис, который позволяет нам получать самые последние сообщения. Однако, чтобы быть полезными, мы также хотим создавать и обновлять сообщения.
5.1. Создание новых сообщений
Во-первых, мы будем поддерживать создание новых сообщений. Для этого мы добавим в наш PostsService новый метод :
public void createPost(String author, String title, String contents) throws Exception {
faunaClient.query(
Create(Collection("posts"),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents),
"created", Now(),
"authorRef", Select(Value("ref"), Get(Match(Index("users_by_username"), Value(author))))
)
)
)
).get();
}
Если это кажется вам знакомым, это эквивалентно Java, когда мы ранее создавали новый пост в оболочке Fauna.
Затем мы можем добавить метод контроллера, чтобы клиенты могли создавать сообщения. Для этого нам сначала нужна запись Java для представления данных входящего запроса:
public record UpdatedPost(String title, String content) {}
Теперь мы можем создать новый метод контроллера в PostsController для обработки запросов:
@PostMapping
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void createPost(@RequestBody UpdatedPost post) throws Exception {
String name = SecurityContextHolder.getContext().getAuthentication().getName();
postsService.createPost(name, post.title(), post.content());
}
Обратите внимание, что мы используем аннотацию @PreAuthorize для проверки подлинности запроса, а затем используем имя пользователя, прошедшего проверку подлинности, в качестве автора нового сообщения.
На этом этапе запуск службы и отправка POST в конечную точку приведет к созданию новой записи в нашей коллекции, которую мы затем сможем получить с помощью более ранних обработчиков.
5.2. Обновление существующих сообщений
Нам также было бы полезно обновлять существующие сообщения, а не создавать новые. Мы справимся с этим, приняв запрос PUT с новым заголовком и содержимым и обновив сообщение, чтобы оно имело эти значения.
Как и раньше, первое, что нам нужно, это новый метод PostsService для поддержки этого:
public void updatePost(String id, String title, String contents) throws Exception {
faunaClient.query(
Update(Ref(Collection("posts"), id),
Obj(
"data", Obj(
"title", Value(title),
"contents", Value(contents)
)
)
)
).get();
}
Далее мы добавляем наш обработчик в PostsController :
@PutMapping("/{id}")
@ResponseStatus(HttpStatus.NO_CONTENT)
@PreAuthorize("isAuthenticated()")
public void updatePost(@PathVariable("id") String id, @RequestBody UpdatedPost post)
throws Exception {
postsService.updatePost(id, post.title(), post.content());
}
Обратите внимание, что мы используем одно и то же тело запроса для создания и обновления сообщений. Это совершенно нормально, так как оба имеют одинаковую форму и значение — новые детали для рассматриваемого поста.
На этом этапе запуск службы и отправка PUT на правильный URL-адрес приведет к обновлению этой записи. Однако, если мы позвоним с неизвестным идентификатором, мы получим ошибку. Мы можем исправить это с помощью метода обработчика исключений:
@ExceptionHandler(NotFoundException.class)
@ResponseStatus(HttpStatus.NOT_FOUND)
public void postNotFound() {}
Теперь это приведет к тому, что запрос на обновление неизвестного сообщения будет возвращать HTTP 404.
6. Получение прошлых версий сообщений
Теперь, когда мы можем обновлять сообщения, может быть полезно просмотреть их старые версии.
Во-первых, мы добавим в наш PostsService новый метод для получения сообщений. Здесь принимается идентификатор поста и, необязательно, версия, до которой мы хотим получить — другими словами, если мы предоставляем версию «5», то вместо этого мы хотим вернуть версию «4»:
Post getPost(String id, Long before) throws Exception {
var query = Get(Ref(Collection("posts"), id));
if (before != null) {
query = At(Value(before - 1), query);
}
var postResult = faunaClient.query(
Let(
"post", query
).in(
Obj(
"post", Var("post"),
"author", Get(Select(Arr(Value("data"), Value("authorRef")), Var("post")))
)
)
).get();
return parsePost(postResult);
}
Здесь мы вводим метод At , который заставит Fauna вернуть данные в заданный момент времени. Наши номера версий — это просто метки времени в микросекундах, поэтому мы можем получить значение до заданной точки, просто запросив данные за 1 мкс до значения, которое нам дали.
Опять же, для этого нам нужен метод контроллера для обработки входящих вызовов. Мы добавим это в наш PostsController :
@GetMapping("/{id}")
public Post getPost(@PathVariable("id") String id, @RequestParam(value = "before", required = false) Long before)
throws Exception {
return postsService.getPost(id, before);
}
И теперь мы можем получать отдельные версии отдельных сообщений. Вызов /posts/321742144715882562 позволит получить самую последнюю версию этого сообщения, но вызов /posts/321742144715882562?before=1643183487660000 позволит получить версию сообщения, которая непосредственно предшествовала этой версии.
7. Заключение
Здесь мы рассмотрели некоторые функции базы данных Fauna и то, как с их помощью создать приложение. Есть еще много того, что может сделать Фауна, чего мы здесь не рассмотрели, но почему бы не попробовать изучить их для вашего следующего проекта?
Как всегда, весь показанный здесь код доступен на GitHub .