1. Введение
В этом руководстве мы узнаем, что требуется при создании конвейеров данных для приложений IoT.
Попутно мы поймем характеристики архитектуры IoT и увидим, как использовать различные инструменты, такие как брокер MQTT, NiFi и InfluxDB, для создания масштабируемого конвейера данных для приложений IoT.
2. Интернет вещей и его архитектура
Во-первых, давайте рассмотрим некоторые основные концепции и разберемся с общей архитектурой приложения IoT.
2.1. Что такое Интернет вещей?
Интернет вещей ( IoT) в широком смысле относится к сети физических объектов , известных как «вещи». Например, вещи могут включать в себя что угодно, от обычных предметов домашнего обихода, таких как лампочка, до сложного промышленного оборудования. Через эту сеть мы можем подключить широкий спектр датчиков и исполнительных механизмов к Интернету для обмена данными:
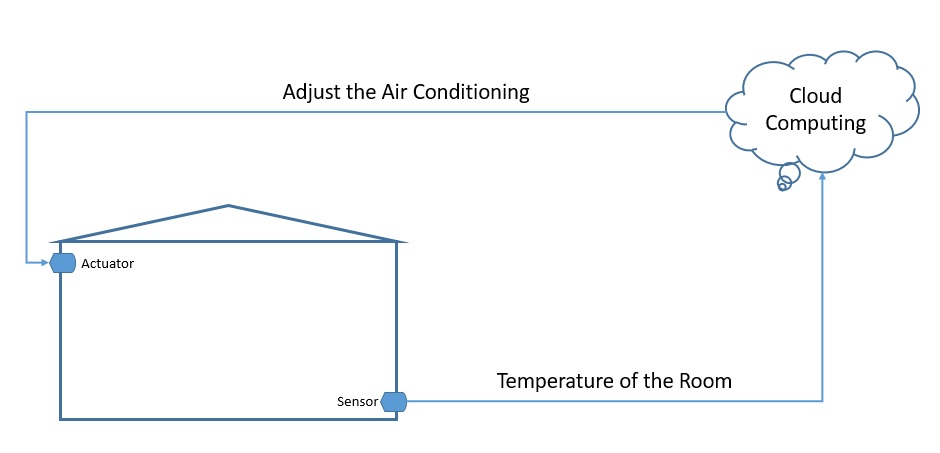
Теперь мы можем развертывать вещи в самых разных средах — например, среда может быть нашим домом или чем-то совершенно другим, например, движущимся грузовым автомобилем. Тем не менее, мы не можем делать никаких предположений о качестве электропитания и сети, которые будут доступны этим вещам. Следовательно, это порождает уникальные требования к приложениям IoT.
2.2. Введение в архитектуру Интернета вещей
Типичная архитектура IoT обычно состоит из четырех разных уровней. Давайте разберемся, как данные на самом деле проходят через эти слои:
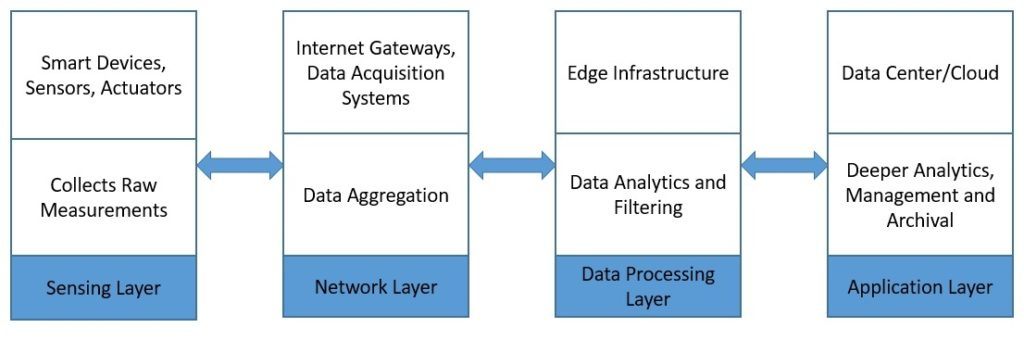
Во-первых, сенсорный слой состоит в основном из датчиков, которые собирают измерения из окружающей среды. Затем сетевой уровень помогает агрегировать необработанные данные и отправлять их через Интернет для обработки. Кроме того, уровень обработки данных фильтрует необработанные данные и генерирует предварительную аналитику. Наконец, прикладной уровень использует мощные возможности обработки данных для более глубокого анализа и управления данными.
3. Введение в MQTT, NiFi и InfluxDB
Теперь давайте рассмотрим несколько продуктов, которые мы сегодня широко используем в настройке IoT. Все они предоставляют некоторые уникальные функции, которые делают их подходящими для требований к данным приложения IoT.
3.1. MQTT
Message Queuing Telemetry Transport (MQTT) — это облегченный сетевой протокол публикации-подписки . Теперь это стандарт OASIS и ISO . Первоначально IBM разработала его для передачи сообщений между устройствами. MQTT подходит для ограниченных сред, где недостаточно памяти, пропускной способности сети и источника питания.
MQTT следует модели клиент-сервер , в которой различные компоненты могут выступать в качестве клиентов и подключаться к серверу через TCP. Мы знаем этот сервер как MQTT-брокер. Клиенты могут публиковать сообщения по адресу, известному как тема. Они также могут подписаться на тему и получать все опубликованные в ней сообщения.
В типичной настройке IoT датчики могут публиковать измерения, такие как температура, брокеру MQTT, а вышестоящие системы обработки данных могут подписываться на эти темы для получения данных:
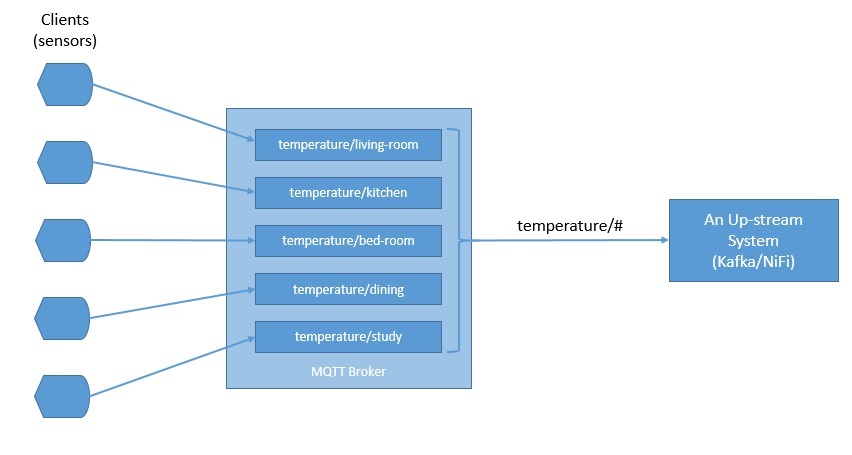
Как мы видим, темы в MQTT иерархичны. Система может легко подписаться на целую иерархию тем, используя подстановочный знак.
MQTT поддерживает три уровня качества обслуживания (QoS) . Это «доставлено не более одного раза», «доставлено хотя бы один раз» и «доставлено ровно один раз». QoS определяет уровень согласия между клиентом и сервером. Каждый клиент может выбрать уровень обслуживания, подходящий для его среды.
Клиент также может запросить у посредника сохранение сообщения во время публикации. В некоторых настройках брокер MQTT может потребовать от клиентов аутентификации по имени пользователя и паролю для подключения. Кроме того, в целях конфиденциальности TCP-соединение может быть зашифровано с помощью SSL/TLS.
Для использования доступно несколько реализаций брокера MQTT и клиентских библиотек — например, HiveMQ , Mosquitto и Paho MQTT . Мы будем использовать Mosquitto в нашем примере в этом уроке. Mosquitto является частью Eclipse Foundation, и мы можем легко установить его на такую плату, как Raspberry Pi или Arduino.
3.2. Апач НиФи
Apache NiFi изначально разрабатывался АНБ как NiagaraFiles. Он облегчает автоматизацию и управление потоком данных между системами и основан на модели программирования на основе потока, которая определяет приложения как сеть процессов черного ящика.
Давайте сначала рассмотрим некоторые из основных понятий. Объект , перемещающийся по системе в NiFi, называется FlowFile . Процессоры FlowFile фактически выполняют полезную работу, такую как маршрутизация, преобразование и посредничество с FlowFiles. Процессоры FlowFile связаны с соединениями.
Группа процессов — это механизм группировки компонентов для организации потока данных в NiFi. Группа процессов может получать данные через порты ввода и отправлять данные через порты вывода. Группа удаленных процессов (RPG) предоставляет механизм для отправки данных или получения данных от удаленного экземпляра NiFi.
Теперь, с этими знаниями, давайте пройдемся по архитектуре NiFi:
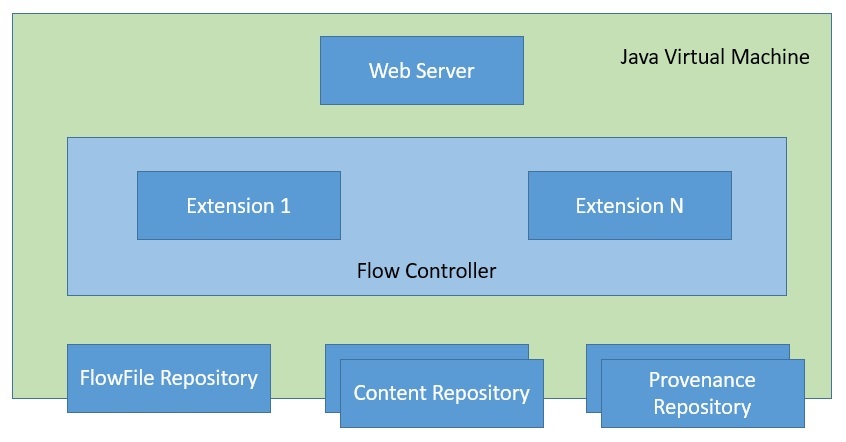
NiFi — это программа на основе Java, которая запускает несколько компонентов в JVM. Веб-сервер — это компонент, на котором размещается API управления и контроля. Flow Controller — это основной компонент NiFi, который управляет расписанием получения расширениями ресурсов для выполнения. Расширения позволяют расширять NiFi и поддерживать интеграцию с различными системами.
NiFi отслеживает состояние FlowFile в репозитории FlowFile. Фактические байты содержимого FlowFile находятся в репозитории содержимого. Наконец, данные о происхождении событий, связанные с FlowFile, находятся в репозитории происхождения.
Поскольку для сбора данных в источнике может потребоваться меньшая площадь и низкое потребление ресурсов, у NiFi есть подпроект, известный как MiNiFi . MiNiFi обеспечивает дополнительный подход к сбору данных для NiFi и легко интегрируется с NiFi через протокол Site-to-Site (S2S):
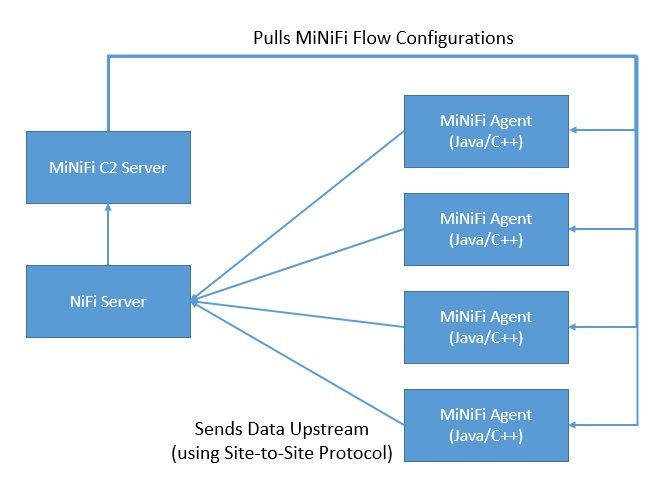
Более того, он позволяет централизованно управлять агентами через протокол MiNiFi Command and Control (C2) . Кроме того, это помогает установить происхождение данных, генерируя полную информацию о цепочке хранения.
3.3. InfluxDB
InfluxDB — это база данных временных рядов, написанная на Go и разработанная InfluxData . Он предназначен для быстрого и высокодоступного хранения и извлечения данных временных рядов. Это особенно подходит для обработки метрик приложений, данных датчиков IoT и аналитики в реальном времени.
Начнем с того, что данные в InfluxDB организованы по временным рядам. Временной ряд может содержать ноль или много точек. Точка представляет собой одну запись данных, состоящую из четырех компонентов — измерения, набора тегов, набора полей и метки времени:
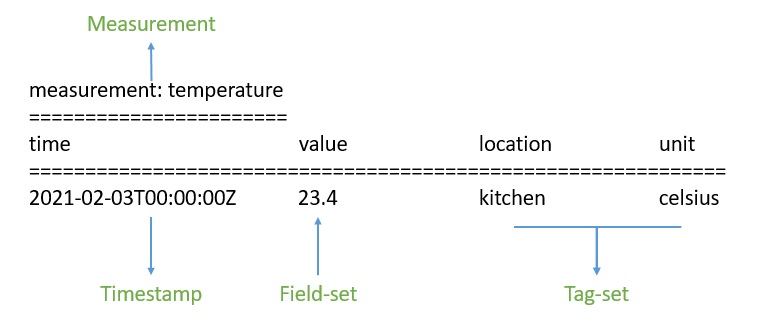
Во- первых, временная метка показывает дату и время в формате UTC, связанные с определенной точкой . Набор полей состоит из одной или нескольких пар поле-ключ и поле-значение. Они захватывают фактические данные с метками для точки. Точно так же набор тегов состоит из пар тег-ключ и тег-значение, но они необязательны. В основном они действуют как метаданные для точки и могут быть проиндексированы для более быстрого ответа на запрос.
Измерение действует как контейнер для набора тегов, набора полей и метки времени. Кроме того, с каждой точкой в InfluxDB может быть связана политика хранения. Политика хранения описывает, как долго InfluxDB будет хранить данные и сколько копий будет создано посредством репликации.
Наконец, база данных действует как логический контейнер для пользователей, политик хранения, непрерывных запросов и данных временных рядов . Мы можем понять, что база данных в InfluxDB во многом похожа на традиционную реляционную базу данных.
Кроме того, InfluxDB является частью платформы InfluxData, которая предлагает несколько других продуктов для эффективной обработки данных временных рядов. InfluxData теперь предлагает его как InfluxDB OSS 2.0, платформу с открытым исходным кодом, и InfluxDB Cloud, коммерческое предложение:
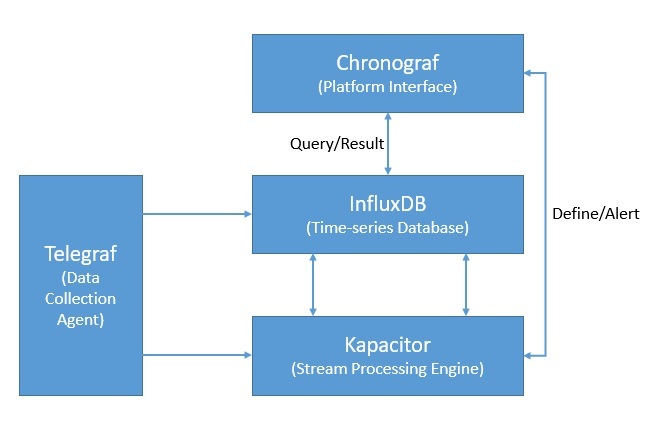
Помимо InfluxDB, платформа включает Chronograf , который предлагает полный интерфейс для платформы InfluxData. Кроме того, он включает в себя Telegraf , агент для сбора и составления отчетов о метриках и событиях. Наконец, есть Kapacitor , механизм обработки потоковых данных в реальном времени.
4. Практический опыт работы с конвейером данных IoT
Теперь мы рассмотрели достаточно возможностей, чтобы использовать эти продукты вместе для создания конвейера данных для нашего приложения IoT. Предположим, что для этого руководства мы собираем измерения, связанные с качеством воздуха, с нескольких станций наблюдения в нескольких городах. Например, измерения включают приземный озон, окись углерода, двуокись серы, двуокись азота и аэрозоли.
4.1. Настройка инфраструктуры
Во-первых, предположим, что каждая метеостанция в городе оснащена всем сенсорным оборудованием. Кроме того, эти датчики подключаются к плате, такой как Raspberry Pi, для сбора аналоговых данных и их оцифровки . Плата подключена к беспроводной сети для отправки необработанных измерений вверх по течению:
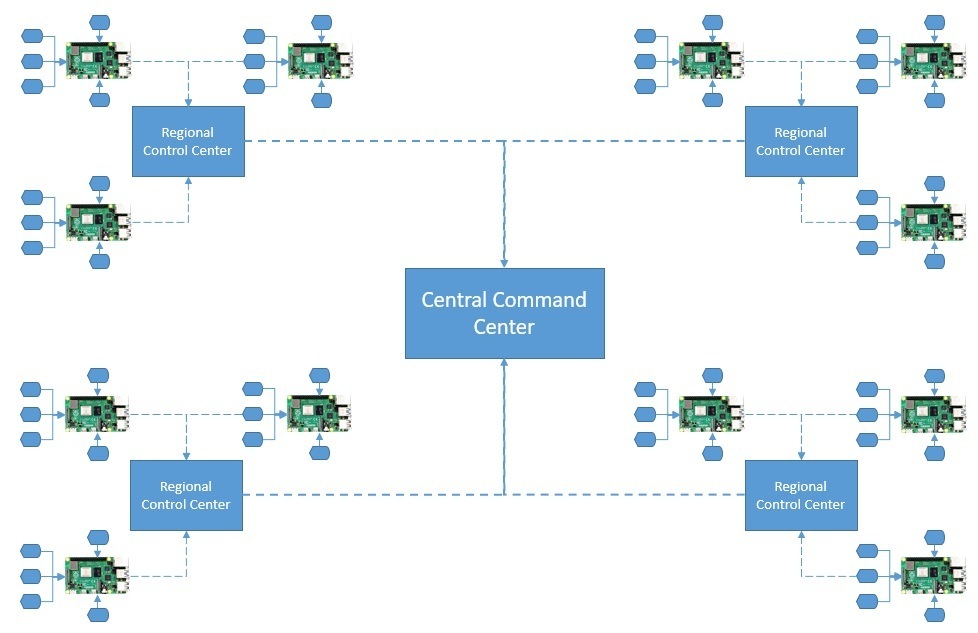
Региональная диспетчерская собирает данные со всех метеостанций города. Мы можем агрегировать и передавать эти данные в какую-либо локальную аналитическую систему для более быстрого понимания. Отфильтрованные данные из всех региональных центров управления отправляются в центральный командный центр, который в основном размещен в облаке.
4.2. Создание архитектуры Интернета вещей
Теперь мы готовы разработать архитектуру IoT для нашего простого приложения для контроля качества воздуха. Здесь мы будем использовать брокера MQTT, Java-агентов MiNiFi, NiFi и InfluxDB:
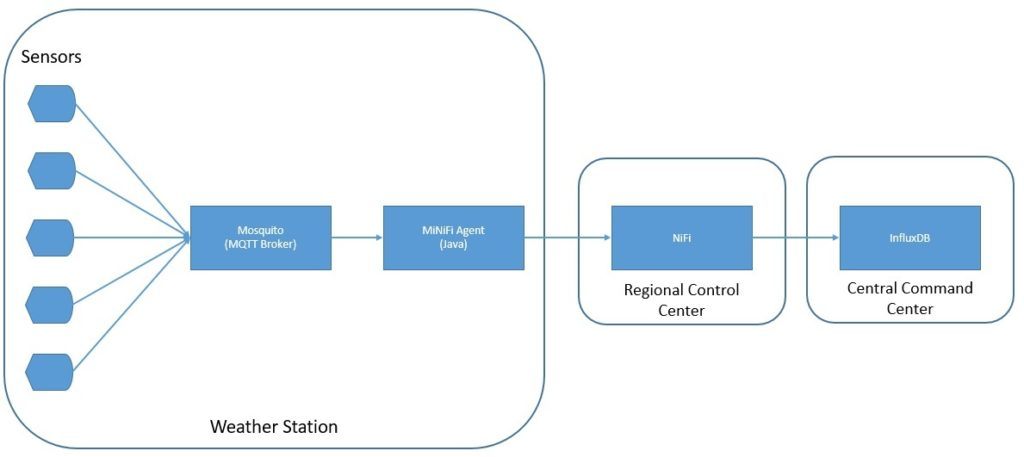
Как мы видим, мы используем MQTT-брокера Mosquitto и Java-агента MiNiFi на сайтах метеостанций . В региональных центрах управления мы используем сервер NiFi для сбора и маршрутизации данных. Наконец, мы используем InfluxDB для хранения измерений на уровне командного центра.
4.3. Выполнение установок
Установить брокера Mosquitto MQTT и агента Java MiNiFi на такую плату, как Raspberry Pi, довольно просто. Однако для этого руководства мы установим их на наш локальный компьютер .
Официальная страница загрузки Eclipse Mosquito содержит двоичные файлы для нескольких платформ. После установки запустить Mosquitto довольно просто из каталога установки:
net start mosquitto
Кроме того, бинарные файлы NiFi также доступны для загрузки с официального сайта. Мы должны извлечь загруженный архив в подходящий каталог. Поскольку MiNiFi будет подключаться к NiFi с использованием протокола site-to-site, мы должны указать порт входного сокета site-to-site в <NIFI_HOME>/conf/nifi.properties:
# Site to Site properties
nifi.remote.input.host=
nifi.remote.input.secure=false
nifi.remote.input.socket.port=1026
nifi.remote.input.http.enabled=true
nifi.remote.input.http.transaction.ttl=30 sec
Затем мы можем запустить NiFi:
<NIFI_HOME>/bin/run-nifi.bat
Точно так же бинарные файлы агента MiNiFi Java или C++ и инструментария доступны для загрузки с официального сайта. Опять же, нам нужно распаковать архивы в подходящую директорию.
MiNiFi по умолчанию поставляется с очень минимальным набором процессоров . Поскольку мы будем использовать данные из MQTT, нам нужно скопировать процессор MQTT в каталог <MINIFI_HOME>/lib. Они объединены в файлы архива NiFi (NAR) и могут находиться в каталоге <NIFI_HOME>/lib:
COPY <NIFI_HOME>/lib/nifi-mqtt-nar-x.x.x.nar <MINIFI_HOME>/lib/nifi-mqtt-nar-x.x.x.nar
Затем мы можем запустить агент MiNiFi:
<MINIFI_HOME>/bin/run-minifi.bat
Наконец, мы можем загрузить версию InfluxDB с открытым исходным кодом с официального сайта. Как и прежде, мы можем извлечь архив и запустить InfluxDB с помощью простой команды:
<INFLUXDB_HOME>/influxd.exe
Мы должны оставить все остальные конфигурации, включая порт, по умолчанию для этого руководства. На этом установка и настройка на нашем локальном компьютере завершена.
4.4. Определение потока данных NiFi
Теперь мы готовы определить наш поток данных. NiFi предоставляет простой в использовании интерфейс для создания и мониторинга потоков данных . Это доступно по URL-адресу http://localhost:8080/nifi.
Для начала определим основной поток данных, который будет работать на сервере NiFi:
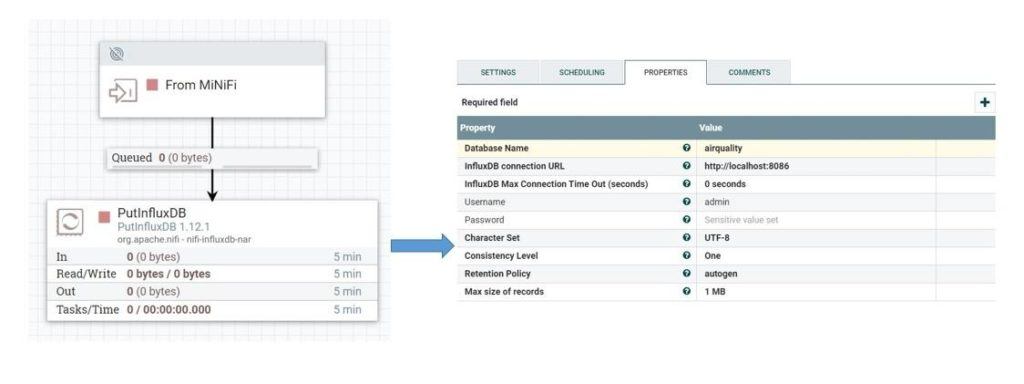
Здесь, как мы видим, мы определили входной порт, который будет получать данные от агентов MiNiFi. Далее он отправляет данные через соединение с процессором PutInfluxDB , отвечающим за хранение данных в InfluxDB. В конфигурации этого процессора мы определили URL-адрес подключения InfluxDB и имя базы данных, куда мы хотим отправлять данные.
4.5. Определение потока данных MiNiFi
Далее мы определим поток данных, который будет работать на агентах MiNiFi. Мы будем использовать тот же пользовательский интерфейс NiFi и экспортируем поток данных в качестве шаблона, чтобы настроить его в агенте MiNiFi . Давайте определим поток данных для агента MiNiFi:
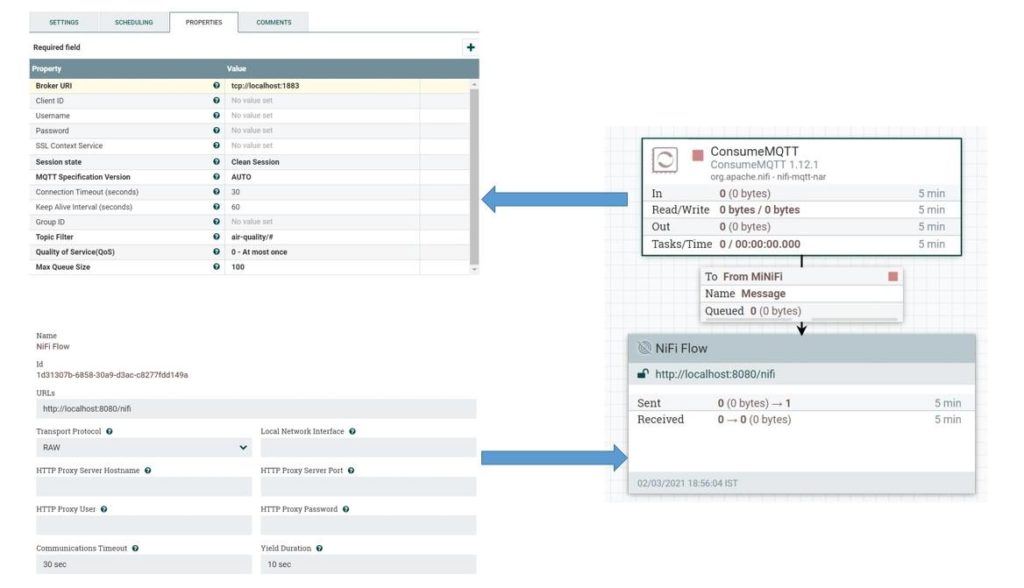
Здесь мы определили процессор ConsumeMQTT , который отвечает за получение данных от брокера MQTT. Мы указали URI брокера, а также фильтр тем в свойствах. Мы извлекаем данные из всех тем, определенных в иерархии качества воздуха .
Мы также определили группу удаленных процессов и подключили ее к процессору ConcumeMQTT. Группа удаленных процессов отвечает за отправку данных в NiFi через протокол site-to-site.
Мы можем сохранить этот поток данных в виде шаблона и загрузить его в виде XML-файла. Назовем этот файл config.xml . Теперь мы можем использовать набор инструментов конвертера для преобразования этого шаблона из XML в YAML, который использует агент MiNiFi:
<MINIFI_TOOLKIT_HOME>/bin/config.bat transform config.xml config.yml
Это даст нам файл config.yml , в котором нам нужно будет вручную добавить хост и порт сервера NiFi:
Input Ports:
- id: 19442f9d-aead-3569-b94c-1ad397e8291c
name: From MiNiFi
comment: ''
max concurrent tasks: 1
use compression: false
Properties: # Deviates from spec and will later be removed when this is autonegotiated
Port: 1026
Host Name: localhost
Теперь мы можем поместить этот файл в каталог <MINIFI_HOME>/conf, заменив файл, который там уже может быть. После этого нам придется перезапустить агент MiNiFi.
Здесь мы делаем много ручной работы, чтобы создать поток данных и настроить его в агенте MiNiFi. Это нецелесообразно для реальных сценариев, когда сотни агентов могут находиться в удаленных местах. Однако, как мы видели ранее, мы можем автоматизировать это с помощью сервера MiNiFi C2 . Но это не входит в задачи данного урока.
4.6. Тестирование конвейера данных
Наконец, мы готовы протестировать наш конвейер данных! Поскольку у нас нет возможности использовать настоящие датчики, мы создадим небольшую симуляцию. Мы будем генерировать данные датчика с помощью небольшой программы на Java :
class Sensor implements Callable<Boolean> {
String city;
String station;
String pollutant;
String topic;
Sensor(String city, String station, String pollutant, String topic) {
this.city = city;
this.station = station;
this.pollutant = pollutant;
this.topic = topic;
}
@Override
public Boolean call() throws Exception {
MqttClient publisher = new MqttClient(
"tcp://localhost:1883", UUID.randomUUID().toString());
MqttConnectOptions options = new MqttConnectOptions();
options.setAutomaticReconnect(true);
options.setCleanSession(true);
options.setConnectionTimeout(10);
publisher.connect(options);
IntStream.range(0, 10).forEach(i -> {
String payload = String.format("%1$s,city=%2$s,station=%3$s value=%4$04.2f",
pollutant,
city,
station,
ThreadLocalRandom.current().nextDouble(0, 100));
MqttMessage message = new MqttMessage(payload.getBytes());
message.setQos(0);
message.setRetained(true);
try {
publisher.publish(topic, message);
Thread.sleep(1000);
} catch (MqttException | InterruptedException e) {
e.printStackTrace();
}
});
return true;
}
}
Здесь мы используем Java-клиент Eclipse Paho для генерации сообщений брокеру MQTT. Мы можем добавить столько датчиков, сколько захотим для создания нашей симуляции:
ExecutorService executorService = Executors.newCachedThreadPool();
List<Callable<Boolean>> sensors = Arrays.asList(
new Simulation.Sensor("london", "central", "ozone", "air-quality/ozone"),
new Simulation.Sensor("london", "central", "co", "air-quality/co"),
new Simulation.Sensor("london", "central", "so2", "air-quality/so2"),
new Simulation.Sensor("london", "central", "no2", "air-quality/no2"),
new Simulation.Sensor("london", "central", "aerosols", "air-quality/aerosols"));
List<Future<Boolean>> futures = executorService.invokeAll(sensors);
Если все работает как надо, мы сможем запросить наши данные в базе данных InfluxDB:
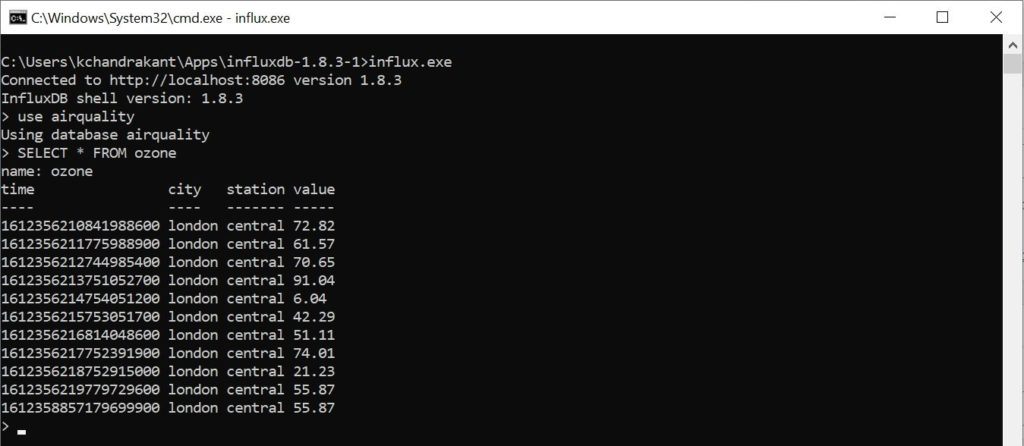
Например, мы можем увидеть все точки, относящиеся к измерению «озон» в базе данных «качество воздуха».
5. Вывод
Подводя итог, мы рассмотрели базовый вариант использования IoT в этом руководстве. Мы также поняли, как использовать такие инструменты, как MQTT, NiFi и InfluxDB, для создания масштабируемого конвейера данных. Конечно, это не охватывает всю широту приложения IoT, а возможности расширения конвейера для анализа данных безграничны.
Кроме того, пример, который мы выбрали в этом руководстве, предназначен только для демонстрационных целей. Фактическая инфраструктура и архитектура приложения IoT могут быть весьма разнообразными и сложными. Более того, мы можем завершить цикл обратной связи, отодвигая действенные идеи назад в виде команд.