1. Введение
Приложения иногда зависают или работают медленно, и определение основной причины не всегда является простой задачей. Дамп потока предоставляет моментальный снимок текущего состояния запущенного процесса Java . Однако сгенерированные данные включают несколько длинных файлов. Таким образом, нам нужно будет проанализировать дампы потоков Java и найти проблему в большом куске несвязанной информации.
В этом руководстве мы увидим, как отфильтровать эти данные для эффективной диагностики проблем с производительностью. Также мы научимся находить узкие места или даже простые баги.
2. Потоки в JVM
JVM использует потоки для выполнения каждой внутренней и внешней операции. Как мы знаем, процесс сборки мусора имеет свой собственный поток, но и задачи внутри Java-приложения создают свои собственные.
За время своего существования поток проходит через множество состояний . Каждый поток имеет стек выполнения, отслеживающий текущую операцию. Кроме того, JVM также сохраняет все предыдущие успешно вызванные методы. Таким образом, можно проанализировать весь стек, чтобы изучить, что происходит с приложением, когда что-то идет не так.
Чтобы продемонстрировать тему этого руководства, мы будем использовать в качестве примера простое приложение Sender-Receiver ( NetworkDriver ) . Программа Java отправляет и получает пакеты данных, чтобы мы могли анализировать то, что происходит за кулисами.
2.1. Получение дампа потока Java
После запуска приложения существует несколько способов создания дампа потока Java для диагностики. В этом руководстве мы будем использовать две утилиты, включенные в установку JDK7+. Во- первых, мы выполним команду JVM Process Status (jps) , чтобы обнаружить процесс PID нашего приложения:
$ jps
80661 NetworkDriver
33751 Launcher
80665 Jps
80664 Launcher
57113 Application
Во-вторых, мы получаем PID для нашего приложения, в данном случае того, что рядом с NetworkDriver. Затем мы захватим дамп потока с помощью jstack . Наконец, мы сохраним результат в текстовом файле:
$ jstack -l 80661 > sender-receiver-thread-dump.txt
2.2. Структура образца дампа
Давайте посмотрим на сгенерированный дамп потока. В первой строке отображается метка времени, а во второй — информация о JVM:
2021-01-04 12:59:29
Full thread dump OpenJDK 64-Bit Server VM (15.0.1+9-18 mixed mode, sharing):
В следующем разделе показаны внутренние потоки Safe Memory Reclamation (SMR) и не-JVM:
Threads class SMR info:
_java_thread_list=0x00007fd7a7a12cd0, length=13, elements={
0x00007fd7aa808200, 0x00007fd7a7012c00, 0x00007fd7aa809800, 0x00007fd7a6009200,
0x00007fd7ac008200, 0x00007fd7a6830c00, 0x00007fd7ab00a400, 0x00007fd7aa847800,
0x00007fd7a6896200, 0x00007fd7a60c6800, 0x00007fd7a8858c00, 0x00007fd7ad054c00,
0x00007fd7a7018800
}
Затем дамп отображает список потоков. Каждый поток содержит следующую информацию:
- Имя: оно может предоставить полезную информацию, если разработчики включают осмысленное имя потока.
- Приоритет (ранее): приоритет потока
- Идентификатор Java (tid): уникальный идентификатор, присвоенный JVM.
- Собственный идентификатор (nid): уникальный идентификатор, предоставляемый ОС, полезный для извлечения корреляции с процессором или обработкой памяти.
- Состояние: фактическое состояние потока
- Трассировка стека: самый важный источник информации для расшифровки того, что происходит с нашим приложением .
Мы можем видеть сверху вниз, что делают разные потоки во время моментального снимка. Давайте сосредоточимся только на интересных битах стека, ожидающих обработки сообщения:
"Monitor Ctrl-Break" #12 daemon prio=5 os_prio=31 cpu=17.42ms elapsed=11.42s tid=0x00007fd7a6896200 nid=0x6603 runnable [0x000070000dcc5000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.SocketDispatcher.read0(java.base@15.0.1/Native Method)
at sun.nio.ch.SocketDispatcher.read(java.base@15.0.1/SocketDispatcher.java:47)
at sun.nio.ch.NioSocketImpl.tryRead(java.base@15.0.1/NioSocketImpl.java:261)
at sun.nio.ch.NioSocketImpl.implRead(java.base@15.0.1/NioSocketImpl.java:312)
at sun.nio.ch.NioSocketImpl.read(java.base@15.0.1/NioSocketImpl.java:350)
at sun.nio.ch.NioSocketImpl$1.read(java.base@15.0.1/NioSocketImpl.java:803)
at java.net.Socket$SocketInputStream.read(java.base@15.0.1/Socket.java:981)
at sun.nio.cs.StreamDecoder.readBytes(java.base@15.0.1/StreamDecoder.java:297)
at sun.nio.cs.StreamDecoder.implRead(java.base@15.0.1/StreamDecoder.java:339)
at sun.nio.cs.StreamDecoder.read(java.base@15.0.1/StreamDecoder.java:188)
- locked <0x000000070fc949b0> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(java.base@15.0.1/InputStreamReader.java:181)
at java.io.BufferedReader.fill(java.base@15.0.1/BufferedReader.java:161)
at java.io.BufferedReader.readLine(java.base@15.0.1/BufferedReader.java:326)
- locked <0x000000070fc949b0> (a java.io.InputStreamReader)
at java.io.BufferedReader.readLine(java.base@15.0.1/BufferedReader.java:392)
at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:61)
Locked ownable synchronizers:
- <0x000000070fc8a668> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
На первый взгляд мы видим, что трассировка основного стека выполняет java.io.BufferedReader.readLine , что является ожидаемым поведением. Если мы посмотрим дальше, то увидим все методы JVM, выполняемые нашим приложением за кулисами . Поэтому мы можем определить корень проблемы, просмотрев исходный код или другую внутреннюю обработку JVM.
В конце дампа мы заметим несколько дополнительных потоков , выполняющих фоновые операции, такие как сборка мусора (GC) или завершение объекта :
"VM Thread" os_prio=31 cpu=1.85ms elapsed=11.50s tid=0x00007fd7a7a0c170 nid=0x3603 runnable
"GC Thread#0" os_prio=31 cpu=0.21ms elapsed=11.51s tid=0x00007fd7a5d12990 nid=0x4d03 runnable
"G1 Main Marker" os_prio=31 cpu=0.06ms elapsed=11.51s tid=0x00007fd7a7a04a90 nid=0x3103 runnable
"G1 Conc#0" os_prio=31 cpu=0.05ms elapsed=11.51s tid=0x00007fd7a5c10040 nid=0x3303 runnable
"G1 Refine#0" os_prio=31 cpu=0.06ms elapsed=11.50s tid=0x00007fd7a5c2d080 nid=0x3403 runnable
"G1 Young RemSet Sampling" os_prio=31 cpu=1.23ms elapsed=11.50s tid=0x00007fd7a9804220 nid=0x4603 runnable
"VM Periodic Task Thread" os_prio=31 cpu=5.82ms elapsed=11.42s tid=0x00007fd7a5c35fd0 nid=0x9903 waiting on condition
Наконец, в дампе отображаются ссылки на Java Native Interface (JNI). Мы должны обратить особое внимание на это, когда происходит утечка памяти, потому что они не удаляются автоматически сборщиком мусора:
JNI global refs: 15, weak refs: 0
Дампы потоков довольно похожи по своей структуре, но мы хотим избавиться от неважных данных, сгенерированных для нашего варианта использования. С другой стороны, нам нужно будет хранить и группировать важную информацию из множества журналов, созданных трассировкой стека. Давайте посмотрим, как это сделать!
3. Рекомендации по анализу дампа потока
Чтобы понять, что происходит с нашим приложением, нам нужно эффективно проанализировать сгенерированный снимок. У нас будет много информации с точными данными всех потоков на момент дампа . Тем не менее, нам нужно будет курировать файлы журнала, выполнив некоторую фильтрацию и группировку, чтобы извлечь полезные подсказки из трассировки стека. Как только мы подготовим дамп, мы сможем проанализировать проблему, используя различные инструменты. Давайте посмотрим, как расшифровать содержимое образца дампа.
3.1. Проблемы с синхронизацией
Одним из интересных советов по фильтрации трассировки стека является состояние потока. В основном мы сосредоточимся на потоках RUNNABLE или BLOCKED и, в конечном итоге, на потоках TIMED_WAITING . Эти состояния укажут нам направление конфликта между двумя или более потоками:
- В тупиковой ситуации, когда несколько запущенных потоков удерживают синхронизированный блок в общем объекте
- В конфликте потоков , когда поток блокируется в ожидании завершения других. Например, дамп, созданный в предыдущем разделе
3.2. Проблемы с выполнением
Как показывает опыт, при аномально высокой загрузке ЦП нам нужно смотреть только на RUNNABLE threads . Мы будем использовать дампы потоков вместе с другими командами для получения дополнительной информации. Одной из таких команд является top -H -p PID, которая показывает, какие потоки потребляют ресурсы ОС в данном конкретном процессе. Нам также нужно на всякий случай взглянуть на внутренние потоки JVM, такие как GC. С другой стороны, когда производительность обработки ненормально низкая , мы рассмотрим заблокированные потоки.
В таких случаях одного дампа наверняка будет недостаточно, чтобы понять, что происходит. Нам понадобится несколько дампов через близкие промежутки времени , чтобы сравнить стеки одних и тех же потоков в разное время. С одной стороны, одного снимка не всегда достаточно, чтобы выяснить корень проблемы. С другой стороны, нам нужно избегать шума между снимками (слишком много информации).
Чтобы понять эволюцию потоков с течением времени, рекомендуется делать как минимум 3 дампа, по одному каждые 10 секунд . Еще один полезный совет — разбивать дампы на небольшие куски, чтобы избежать сбоев при загрузке файлов.
3.3. Рекомендации
Чтобы эффективно расшифровать корень проблемы, нам нужно организовать огромное количество информации в трассировке стека. Поэтому примем во внимание следующие рекомендации:
- В вопросах выполнения сделайте несколько снимков с интервалом в 10 секунд , это поможет сосредоточиться на реальных проблемах. Также рекомендуется разделить файлы, если это необходимо, чтобы избежать сбоев при загрузке.
- Используйте имена при создании новых потоков , чтобы лучше идентифицировать исходный код.
- В зависимости от проблемы игнорируйте внутреннюю обработку JVM (например, GC) .
- Сосредоточьтесь на длительных или заблокированных потоках при выдаче ненормального использования ЦП или памяти.
- Сопоставьте стек потока с обработкой ЦП , используя
top -H -p PID - И самое главное, используйте инструменты Analyzer
Анализ дампов потоков Java вручную может быть утомительным занятием. Для простых приложений можно идентифицировать потоки, создающие проблему. С другой стороны, для сложных ситуаций нам понадобятся инструменты, облегчающие эту задачу. В следующих разделах мы покажем, как использовать инструменты, используя дамп, созданный для примера конфликта потоков.
4. Онлайн-инструменты
Доступно несколько онлайн-инструментов. При использовании такого программного обеспечения необходимо учитывать вопросы безопасности. Помните, что мы можем делиться журналами со сторонними организациями .
4.1. FastThread
FastThread , вероятно, является лучшим онлайн-инструментом для анализа дампов потоков для производственных сред. Он обеспечивает очень приятный графический пользовательский интерфейс. Он также включает в себя несколько функций, таких как использование ЦП потоками, длина стека и наиболее часто используемые и сложные методы:
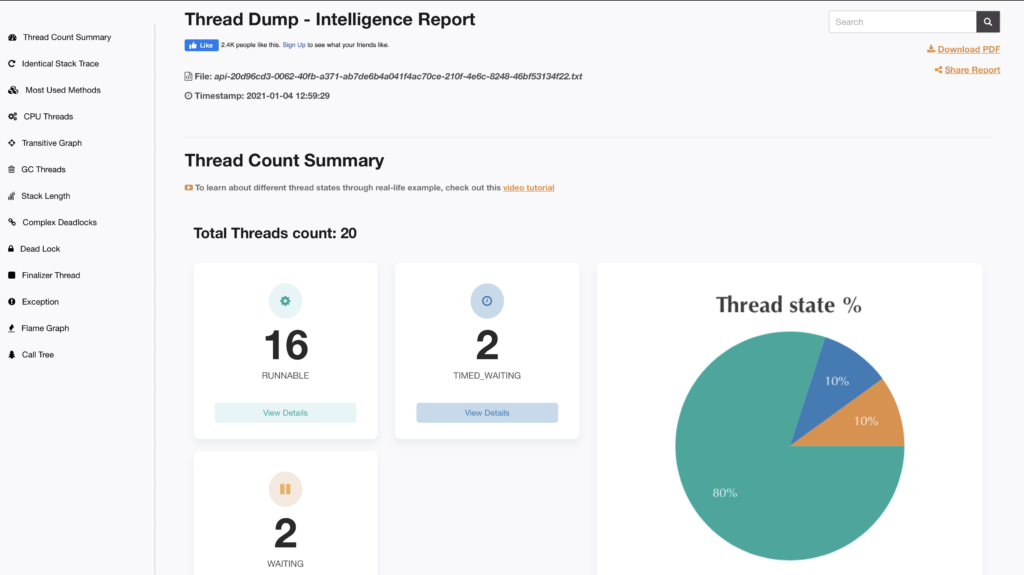
FastThread включает функцию REST API для автоматизации анализа дампов потоков. С помощью простой команды cURL можно мгновенно отправить результаты. Основным недостатком является безопасность, поскольку трассировка стека хранится в облаке .
4.2. Обзор JStack
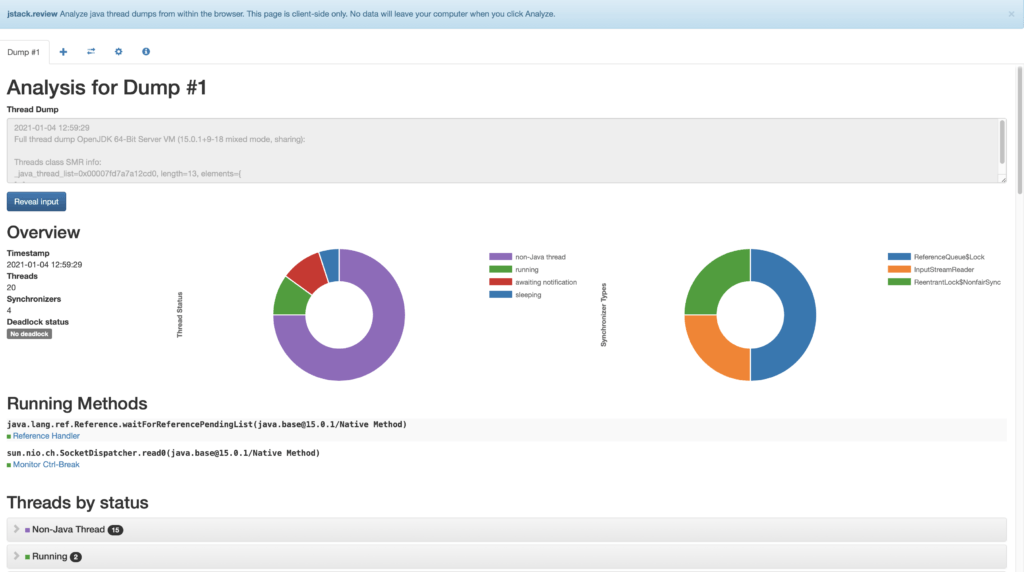
JStack Review — это онлайн-инструмент, который анализирует дампы в браузере. Это только на стороне клиента, поэтому никакие данные не хранятся вне вашего компьютера . С точки зрения безопасности это большое преимущество. Он предоставляет графический обзор всех потоков, отображая запущенные методы, а также группируя их по статусу. JStack Review отделяет потоки, создающие стек, от остальных, что очень важно, чтобы игнорировать, например, внутренние процессы. Наконец, он также включает синхронизаторы и игнорируемые строки:
4.3. Spotify Online Анализатор дампа потока Java
Spotify Online Java Thread Dump Analyzer — это онлайн-инструмент с открытым исходным кодом, написанный на JavaScript. Он показывает результаты в виде обычного текста, разделяя потоки со стеком и без него. Он также отображает лучшие методы из запущенных потоков:

5. Автономные приложения
Есть также несколько автономных приложений, которые мы можем использовать локально.
5.1. JProfiler
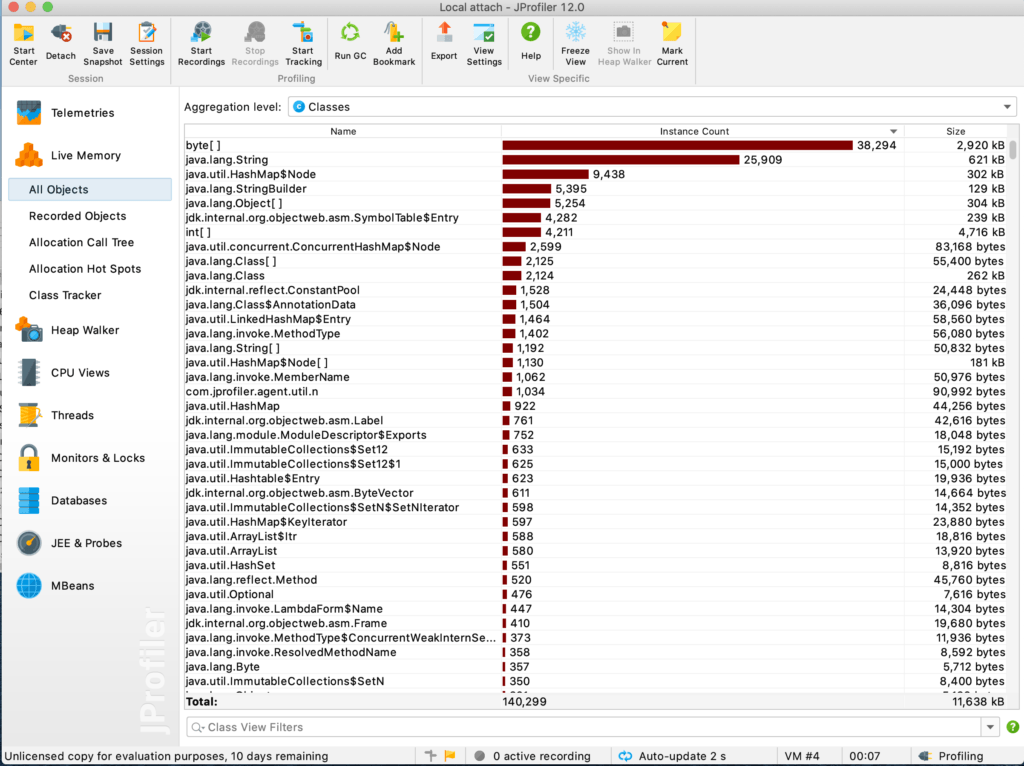
JProfiler — самый мощный инструмент на рынке, хорошо известный в сообществе разработчиков Java. Функционал можно протестировать с 10-дневной пробной лицензией. JProfiler позволяет создавать профили и прикреплять к ним запущенные приложения. Он включает в себя несколько функций для выявления проблем на месте, таких как использование ЦП и памяти и анализ базы данных. Он также поддерживает интеграцию с IDE:
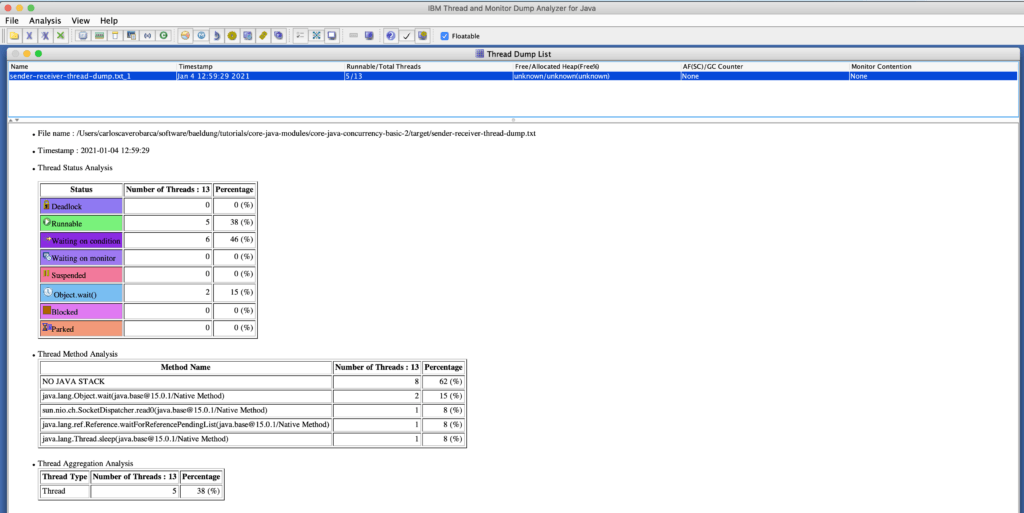
5.2. IBM Thread Monitor и анализатор дампа для Java (TMDA)
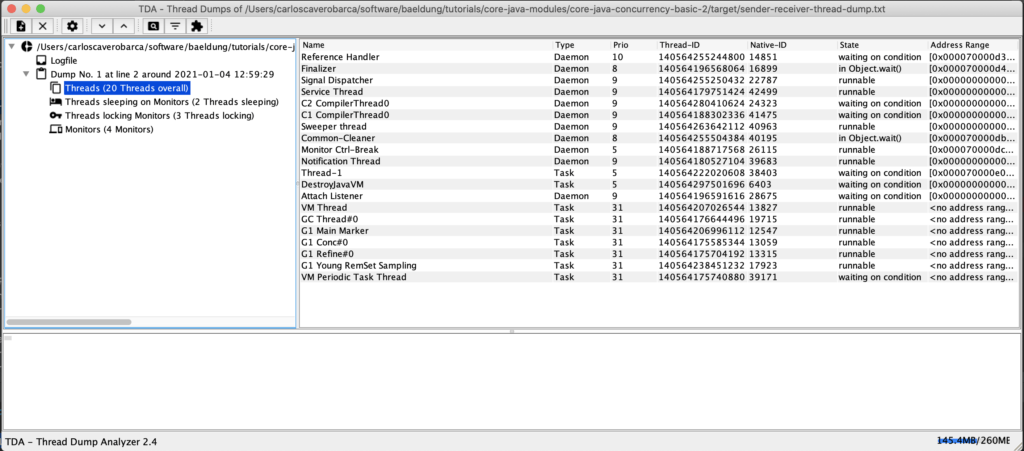
IBM TMDA можно использовать для выявления конфликтов между потоками, взаимоблокировок и узких мест. Он свободно распространяется и поддерживается, но не предлагает никаких гарантий или поддержки со стороны IBM:
5.3. Анализатор дампа резьбы Irockel (TDA)
Irockel TDA — это автономный инструмент с открытым исходным кодом под лицензией LGPL v2.1. Последняя версия (v2.4) была выпущена в августе 2020 года, поэтому поддерживается в хорошем состоянии. Он отображает дамп потока в виде дерева, предоставляя также некоторую статистику для облегчения навигации:
Наконец, IDE поддерживают базовый анализ дампов потоков, что позволяет отлаживать приложение во время разработки.
5. Вывод
В этой статье мы продемонстрировали, как анализ дампа потока Java может помочь нам выявить проблемы с синхронизацией или выполнением.
Самое главное, мы рассмотрели, как правильно их анализировать, включая рекомендации по организации огромного объема информации, встроенной в снимок.