1. Введение
Предсказание ветвления — интересная концепция в компьютерных науках, которая может сильно повлиять на производительность наших приложений. Тем не менее, как правило, это не совсем понятно, и большинство разработчиков уделяют этому очень мало внимания.
В этой статье мы собираемся подробно изучить, что это такое, как оно влияет на наше программное обеспечение и что мы можем с этим поделать.
2. Что такое конвейеры инструкций?
Когда мы пишем любую компьютерную программу, мы пишем набор команд, которые, как мы ожидаем, компьютер будет последовательно выполнять.
Ранние компьютеры запускали их по одному. Это означает, что каждая команда загружается в память, выполняется полностью, и только после ее завершения загружается следующая.
Инструкционные конвейеры являются улучшением по сравнению с этим. Они позволяют процессору разбивать работу на части, а затем выполнять разные части параллельно. Это позволит процессору выполнять одну команду, загружая следующую, готовую к работе.
Более длинные конвейеры внутри процессора не только позволяют упростить каждую часть, но и позволяют выполнять большее количество ее частей параллельно. Это может улучшить общую производительность системы.
Например, у нас может быть простая программа:
int a = 0;
a += 1;
a += 2;
a += 3;
Это может быть обработано конвейером, состоящим из сегментов Fetch, Decode, Execute, Store, как:
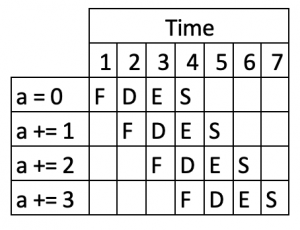
Здесь мы видим, как общее выполнение четырех команд выполняется параллельно, что ускоряет всю последовательность.
3. Каковы опасности?
Некоторые команды, которые должен выполнить процессор, вызовут проблемы при конвейерной обработке . Это любые команды, в которых выполнение одной части конвейера зависит от более ранних частей, но эти более ранние части могут еще не выполняться.
Ветки представляют собой особую форму опасности. Они заставляют выполнение идти в одном из двух направлений, и невозможно узнать, в каком направлении, пока ветвь не будет разрешена. Это означает, что любая попытка загрузить команды после ветки небезопасна, потому что у нас нет возможности узнать, откуда их загружать.
Давайте изменим нашу простую программу, чтобы ввести ветку:
int a = 0;
a += 1;
if (a < 10) {
a += 2;
}
a += 3;
Результат такой же, как и раньше, но мы добавили оператор if в его середину. Компьютер увидит это и не сможет загружать команды после этого, пока это не будет разрешено . Таким образом, поток будет выглядеть примерно так:
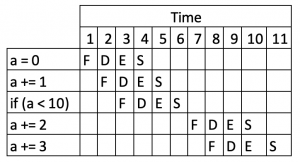
Мы можем сразу увидеть влияние, которое это оказывает на выполнение нашей программы, и сколько тактов потребовалось для выполнения того же результата.
4. Что такое предсказание переходов?
Предсказание ветвления — это усовершенствование вышеописанного, когда наш компьютер пытается предсказать, в каком направлении пойдет ветвь, а затем действовать соответствующим образом.
В приведенном выше примере процессор может предсказать, что if (a < 10) , скорее всего, будет true , и поэтому он будет действовать так, как если бы следующей выполнялась инструкция a += 2 . Это приведет к тому, что поток будет выглядеть примерно так:
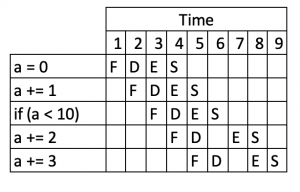
Мы сразу видим, что это улучшило производительность нашей программы — теперь она занимает девять тиков, а не 11, поэтому она на 19% быстрее.
Однако это не без риска. Если предсказание ветвления ошибается, то оно начнет ставить в очередь инструкции, которые не должны выполняться. Если это произойдет, то компьютеру нужно будет их выбросить и начать заново.
Давайте изменим наше условное выражение так, чтобы оно стало ложным :
int a = 0;
a += 1;
if (a > 10) {
a += 2;
}
a += 3;
Это может выполнить что-то вроде:
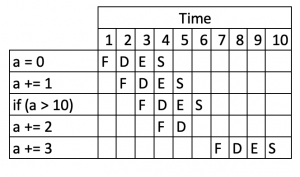
Теперь это медленнее, чем предыдущий поток, хотя мы делаем меньше! Процессор неправильно предсказал, что ветвь будет оцениваться как true , начал ставить в очередь инструкцию a += 2 , а затем должен был отбросить ее и начать заново, когда ветвь оценивалась как false.
5. Реальное влияние на код
Теперь, когда мы знаем, что такое предсказание ветвлений и каковы его преимущества, как оно может повлиять на нас? В конце концов, речь идет о потере нескольких тактов процессора на высокоскоростных компьютерах, поэтому, конечно, это не будет заметно.
И иногда это правда. Но иногда это может иметь неожиданное значение для производительности наших приложений. Это во многом зависит от того, что именно мы делаем. В частности, это зависит от того, сколько мы делаем за короткое время.
5.1. Подсчет записей списка
Давайте попробуем подсчитать записи в списке. Мы создадим список чисел, а затем подсчитаем, сколько из них меньше определенного порога. Это очень похоже на приведенные выше примеры, но мы делаем это в цикле, а не в виде одной инструкции:
List<Long> numbers = LongStream.range(0, top)
.boxed()
.collect(Collectors.toList());
if (shuffle) {
Collections.shuffle(numbers);
}
long cutoff = top / 2;
long count = 0;
long start = System.currentTimeMillis();
for (Long number : numbers) {
if (number < cutoff) {
++count;
}
}
long end = System.currentTimeMillis();
LOG.info("Counted {}/{} {} numbers in {}ms",
count, top, shuffle ? "shuffled" : "sorted", end - start);
Обратите внимание, что мы синхронизируем только цикл, который выполняет подсчет, потому что это то, что нас интересует. Итак, сколько времени это занимает?
Если мы генерируем достаточно маленькие списки, то код работает так быстро, что его нельзя засечь по времени — список размером 100 000 по-прежнему показывает время 0 мс. Однако, когда список становится достаточно большим, чтобы мы могли его рассчитать, мы можем увидеть значительную разницу в зависимости от того, перетасовали ли мы список или нет. Для списка из 10 000 000 номеров:
- Сортировка – 44 мс
- В случайном порядке — 221 мс
То есть перемешанный список требует в 5 раз больше времени для подсчета, чем отсортированный список, даже если фактически подсчитываемые числа одинаковы.
Однако акт сортировки списка значительно дороже, чем просто выполнение подсчета. Мы всегда должны профилировать наш код и определять, выгоден ли какой-либо прирост производительности.
5.2. Порядок отделений
Следуя вышеизложенному, кажется разумным, что порядок ветвлений в операторе if/else должен быть важен . То есть мы могли бы ожидать, что следующее будет работать лучше, чем если бы мы переупорядочили ветки:
if (mostLikely) {
// Do something
} else if (lessLikely) {
// Do something
} else if (leastLikely) {
// Do something
}
Однако современные компьютеры могут избежать этой проблемы, используя кеш предсказания ветвлений . Действительно, мы можем проверить и это:
List<Long> numbers = LongStream.range(0, top)
.boxed()
.collect(Collectors.toList());
if (shuffle) {
Collections.shuffle(numbers);
}
long cutoff = (long)(top * cutoffPercentage);
long low = 0;
long high = 0;
long start = System.currentTimeMillis();
for (Long number : numbers) {
if (number < cutoff) {
++low;
} else {
++high;
}
}
long end = System.currentTimeMillis();
LOG.info("Counted {}/{} numbers in {}ms", low, high, end - start);
Этот код выполняется примерно за одно и то же время — ~35 мс для отсортированных чисел, ~200 мс для перетасованных чисел — при подсчете 10 000 000 чисел, независимо от значения cutoffPercentage .
Это связано с тем, что предиктор ветвлений обрабатывает обе ветви одинаково и правильно угадывает, в каком направлении мы собираемся их использовать.
5.3. Условия объединения
Что, если у нас есть выбор между одним или двумя условиями? Можно было бы переписать нашу логику по-другому, но так ли это?
Например, если мы сравниваем два числа с 0, альтернативный подход состоит в том, чтобы умножить их вместе и сравнить результат с 0. Тогда это заменяет условие умножением. Но стоит ли это?
Рассмотрим пример:
long[] first = LongStream.range(0, TOP)
.map(n -> Math.random() < FRACTION ? 0 : n)
.toArray();
long[] second = LongStream.range(0, TOP)
.map(n -> Math.random() < FRACTION ? 0 : n)
.toArray();
long count = 0;
long start = System.currentTimeMillis();
for (int i = 0; i < TOP; i++) {
if (first[i] != 0 && second[i] != 0) {
++count;
}
}
long end = System.currentTimeMillis();
LOG.info("Counted {}/{} numbers using separate mode in {}ms", count, TOP, end - start);
Наше условие внутри цикла можно заменить, как описано выше. Это действительно влияет на время выполнения:
- Отдельные условия – 40 мс
- Множественное и одиночное условие – 22 мс
Таким образом, вариант, использующий два разных условия, на самом деле выполняется в два раза дольше.
6. Заключение
Мы увидели, что такое предсказание ветвлений и как оно может повлиять на наши программы. Это может дать нам некоторые дополнительные инструменты для обеспечения максимальной эффективности наших программ.
Однако, как всегда, нам нужно помнить о профилировании нашего кода, прежде чем вносить серьезные изменения . Иногда может случиться так, что внесение изменений, помогающих предсказанию ветвлений, обходится дороже по другим причинам.
Примеры кейсов из этой статьи доступны на GitHub .