1. Обзор
Классы Buffer — это основа, на которой построен Java NIO. Однако в этих классах наиболее предпочтительным является класс ByteBuffer . Это потому, что тип byte является наиболее универсальным. Например, мы можем использовать байты для составления других небулевых примитивных типов в JVM. Кроме того, мы можем использовать байты для передачи данных между JVM и внешними устройствами ввода-вывода.
В этом руководстве мы рассмотрим различные аспекты класса ByteBuffer .
2. Создание байтового буфера
ByteBuffer — это абстрактный класс, поэтому мы не можем создать новый экземпляр напрямую. Однако он предоставляет статические фабричные методы для облегчения создания экземпляра. Вкратце, есть два способа создать экземпляр ByteBuffer , путем выделения или переноса:

2.1. Распределение
Распределение создаст экземпляр и выделит личное пространство с определенной емкостью . Если быть точным, класс ByteBuffer имеет два метода выделения: allocate и allocateDirect .
Используя метод allocate , мы получим непрямой буфер, то есть экземпляр буфера с базовым массивом байтов :
ByteBuffer buffer = ByteBuffer.allocate(10);
Когда мы используем метод allocateDirect , он создаст прямой буфер:
ByteBuffer buffer = ByteBuffer.allocateDirect(10);
Для простоты давайте сосредоточимся на непрямом буфере и оставим обсуждение прямого буфера на потом.
2.2. Оберточная бумага
Обертывание позволяет экземпляру повторно использовать существующий массив байтов :
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);
И приведенный выше код эквивалентен:
ByteBuffer buffer = ByteBuffer.wrap(bytes, 0, bytes.length);
Любые изменения, внесенные в элементы данных в существующем массиве байтов , будут отражены в экземпляре буфера, и наоборот.
2.3. Луковая модель
Теперь мы знаем, как получить экземпляр ByteBuffer . Далее давайте рассмотрим класс ByteBuffer как трехуровневую луковичную модель и рассмотрим ее слой за слоем изнутри:
- Уровень данных и индексов
- Передача уровня данных
- Просмотр слоя

На самом внутреннем уровне мы рассматриваем класс ByteBuffer как контейнер для массива байтов с дополнительными индексами. На среднем уровне мы фокусируемся на использовании экземпляра ByteBuffer для передачи данных из/в другие типы данных. Мы проверяем одни и те же базовые данные с помощью разных представлений на основе буфера на самом внешнем уровне.
3. Индексы байтового буфера
Концептуально класс ByteBuffer представляет собой массив байтов , заключенный в объект. Он предоставляет множество удобных методов для облегчения операций чтения или записи из/в базовые данные. И эти методы сильно зависят от поддерживаемых индексов.
Теперь давайте намеренно упростим класс ByteBuffer до контейнера массива байтов с дополнительными индексами:
ByteBuffer = byte array + index
Имея в виду эту концепцию, мы можем классифицировать связанные с индексами методы на четыре категории:
- Базовый
- Отметить и сбросить
- Очистить, перевернуть, перемотать и сжать
- Оставаться
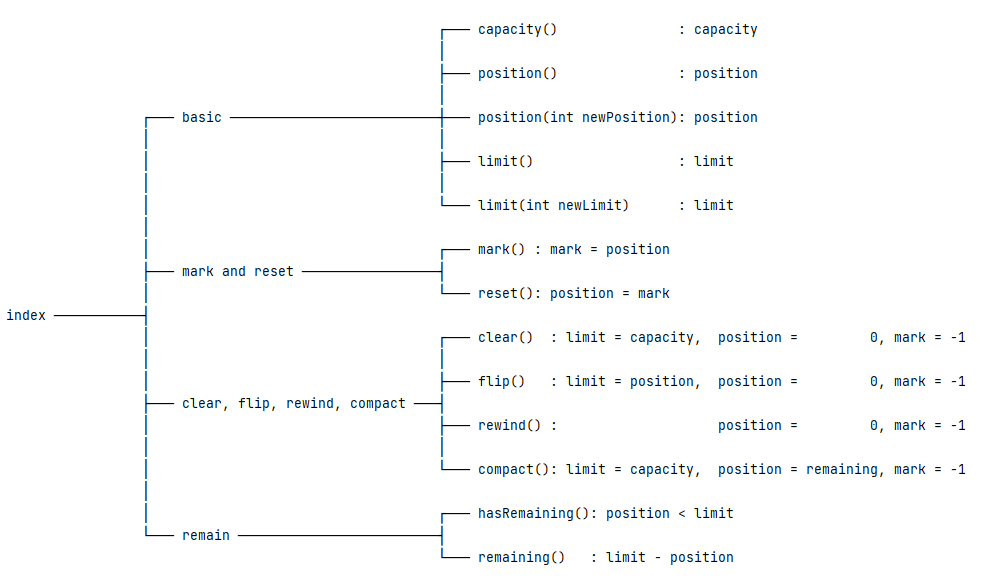
3.1. Четыре основных индекса
В классе Buffer определены четыре индекса . Эти индексы записывают состояние базовых элементов данных:
- Емкость: максимальное количество элементов данных, которые может хранить буфер.
- Ограничение: индекс для остановки чтения или записи
- Позиция: текущий индекс для чтения или записи
- Метка: запомненная позиция
Также между этими индексами существует инвариантная связь:
0 <= mark <= position <= limit <= capacity
И мы должны отметить, что все методы, связанные с индексами, вращаются вокруг этих четырех индексов .
Когда мы создаем новый экземпляр ByteBuffer , метка не определена, позиция равна 0, а предел равен емкости . Например, давайте выделим ByteBuffer с 10 элементами данных:
ByteBuffer buffer = ByteBuffer.allocate(10);
Или давайте обернем существующий массив байтов 10 элементами данных:
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);
В результате метка будет -1, позиция будет 0, а лимит и вместимость будут равны 10:
int position = buffer.position(); // 0
int limit = buffer.limit(); // 10
int capacity = buffer.capacity(); // 10
Емкость доступна только для чтения и не может быть изменена. Но мы можем использовать методы position(int) и limit(int) для изменения соответствующих position и limit :
buffer.position(2);
buffer.limit(5);
Тогда позиция будет 2, а лимит 5.
3.2. Отметить и сбросить
Методы mark() и reset() позволяют нам запомнить определенную позицию и вернуться к ней позже.
Когда мы впервые создаем экземпляр ByteBuffer , метка не определена. Затем мы можем вызвать метод mark() , и метка будет установлена в текущую позицию. После некоторых операций вызов метода reset() изменит позицию обратно на метку .
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0
buffer.position(2); // mark = -1, position = 2
buffer.mark(); // mark = 2, position = 2
buffer.position(5); // mark = 2, position = 5
buffer.reset(); // mark = 2, position = 2
Следует отметить одну вещь: если метка не определена, вызов метода reset() приведет к InvalidMarkException .
3.3. Очистить, перевернуть, перемотать и сжать
Методы clear() , flip() , rewind() и compact() имеют некоторые общие черты и небольшие различия:

Для сравнения этих методов подготовим фрагмент кода:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10
buffer.position(2); // mark = -1, position = 2, limit = 10
buffer.mark(); // mark = 2, position = 2, limit = 10
buffer.position(5); // mark = 2, position = 5, limit = 10
buffer.limit(8); // mark = 2, position = 5, limit = 8
Метод clear() изменит ограничение на емкость , позицию на 0 и отметку на -1:
buffer.clear(); // mark = -1, position = 0, limit = 10
Метод flip() изменит ограничение на position , position на 0 и mark на -1:
buffer.flip(); // mark = -1, position = 0, limit = 5
Метод rewind() сохраняет лимит неизменным и изменяет позицию на 0, а метку на -1:
buffer.rewind(); // mark = -1, position = 0, limit = 8
Метод compact() изменит ограничение на вместимость , позицию на оставшуюся ( limit – position ) и отметку на -1:
buffer.compact(); // mark = -1, position = 3, limit = 10
Вышеупомянутые четыре метода имеют свои варианты использования:
- Для повторного использования буфера удобен метод
clear() .Он установит индексы в начальное состояние и будет готов к новым операциям записи. - После вызова метода
flip()экземпляр буфера переключается из режима записи в режим чтения. Но нам следует избегать двойного вызова методаflip() .Это связано с тем, что второй вызов установитпределравным 0, и никакие элементы данных не смогут быть прочитаны. - Если мы хотим прочитать базовые данные более одного раза, нам пригодится метод
rewind() . - Метод
compact()подходит для частичного повторного использования буфера. Например, предположим, что мы хотим прочитать некоторые, но не все базовые данные, а затем хотим записать данные в буфер. Методcompact()скопирует непрочитанные данные в начало буфера и изменит индексы буфера, чтобы они были готовы к операциям записи.
3.4. Оставаться
Методы hasRemaining() и rest( ) вычисляют отношение лимита и позиции :

Когда лимит больше позиции , функция hasRemaining() вернет true . Кроме того, метод rest() возвращает разницу между лимитом и позицией .
Например, если буфер имеет позицию 2 и предел 8, то его остаток будет равен 6:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10
buffer.position(2); // mark = -1, position = 2, limit = 10
buffer.limit(8); // mark = -1, position = 2, limit = 8
boolean flag = buffer.hasRemaining(); // true
int remaining = buffer.remaining(); // 6
4. Передача данных
Второй уровень луковой модели связан с передачей данных. В частности, класс ByteBuffer предоставляет методы для передачи данных из/в другие типы данных ( byte , char , short , int , long , float и double ):
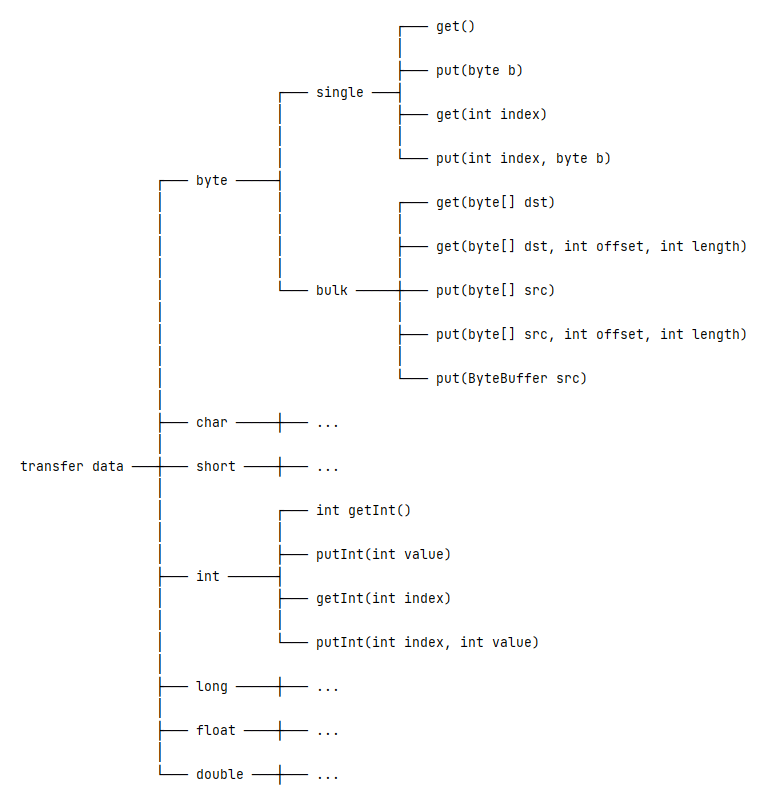
4.1. Передача байтовых данных
Для передачи байтовых данных класс ByteBuffer предоставляет одиночные и массовые операции.
Мы можем читать или записывать один байт из/в базовые данные буфера за одну операцию. Эти операции включают в себя:
public abstract byte get();
public abstract ByteBuffer put(byte b);
public abstract byte get(int index);
public abstract ByteBuffer put(int index, byte b);
Мы можем заметить две версии методов get() / put() из приведенных выше методов: одна не имеет параметров, а другая принимает индекс . Итак, какая разница?
Операция без индекса — это относительная операция, которая работает с элементом данных в текущей позиции, а затем увеличивает позицию на 1. Однако операция с индексом — это целая операция, которая работает с элементами данных в индексе и не изменит положение .
Напротив, массовые операции могут считывать или записывать несколько байтов из/в базовые данные буфера. Эти операции включают в себя:
public ByteBuffer get(byte[] dst);
public ByteBuffer get(byte[] dst, int offset, int length);
public ByteBuffer put(byte[] src);
public ByteBuffer put(byte[] src, int offset, int length);
Все вышеперечисленные методы относятся к относительным операциям. То есть они будут читать или записывать из/в текущую позицию и изменять значение позиции соответственно.
Также есть еще один метод put() , который принимает параметр ByteBuffer :
public ByteBuffer put(ByteBuffer src);
4.2. Передача данных _
Помимо чтения или записи байтовых данных, класс ByteBuffer также поддерживает другие примитивные типы, кроме логического типа. Возьмем в качестве примера тип int . К родственным методам относятся:
public abstract int getInt();
public abstract ByteBuffer putInt(int value);
public abstract int getInt(int index);
public abstract ByteBuffer putInt(int index, int value);
Точно так же методы getInt() и putInt() с параметром index являются абсолютными операциями, в противном случае относительными операциями.
5. Различные взгляды
Третий уровень луковой модели предназначен для чтения одних и тех же базовых данных с разных точек зрения .

Каждый метод на изображении выше будет генерировать новое представление, которое использует те же базовые данные, что и исходный буфер. Чтобы понять новый взгляд, нас должны волновать две проблемы:
- Как новое представление будет анализировать базовые данные?
- Как новое представление будет записывать свои индексы?
5.1. Представление байтового буфера
Чтобы прочитать экземпляр ByteBuffer как другое представление ByteBuffer , у него есть три метода: дубликат() , slice() и asReadOnlyBuffer() .
Давайте посмотрим на иллюстрацию этих различий:
ByteBuffer buffer = ByteBuffer.allocate(10); // mark = -1, position = 0, limit = 10, capacity = 10
buffer.position(2); // mark = -1, position = 2, limit = 10, capacity = 10
buffer.mark(); // mark = 2, position = 2, limit = 10, capacity = 10
buffer.position(5); // mark = 2, position = 5, limit = 10, capacity = 10
buffer.limit(8); // mark = 2, position = 5, limit = 8, capacity = 10
Метод дубликат() создает новый экземпляр ByteBuffer , точно такой же, как исходный. Но каждый из двух буферов будет иметь свой независимый limit , position и mark :
ByteBuffer view = buffer.duplicate(); // mark = 2, position = 5, limit = 8, capacity = 10
Метод slice() создает общее подпредставление базовых данных. Позиция представления будет равна 0, а его предел и емкость будут равны оставшейся части исходного буфера :
ByteBuffer view = buffer.slice(); // mark = -1, position = 0, limit = 3, capacity = 3
По сравнению с методом дубликата() метод asReadOnlyBuffer() работает аналогично, но создает буфер только для чтения. Это означает, что мы не можем использовать это представление только для чтения для изменения базовых данных:
ByteBuffer view = buffer.asReadOnlyBuffer(); // mark = 2, position = 5, limit = 8, capacity = 10
5.2. Другой вид
ByteBuffer также предоставляет другие представления: asCharBuffer() , asShortBuffer() , asIntBuffer() , asLongBuffer() , asFloatBuffer() и asDoubleBuffer() . Эти методы аналогичны методу slice() , т. е. они обеспечивают представление в виде среза, соответствующее текущему положению и пределу базовых данных . Основное различие между ними заключается в интерпретации базовых данных в другие значения примитивного типа.
Вопросы, которые нас должны волновать:
- Как интерпретировать базовые данные
- С чего начать толкование
- Сколько элементов будет представлено в новом сгенерированном представлении
Новое представление будет объединять несколько байтов в тип целевого примитива и запускать интерпретацию с текущей позиции исходного буфера. Новое представление будет иметь емкость, равную количеству оставшихся элементов в исходном буфере, деленному на количество байтов, составляющих примитивный тип представления. Любые оставшиеся байты в конце не будут видны в представлении.
Теперь возьмем asIntBuffer() в качестве примера:
byte[] bytes = new byte[]{
(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE, // CAFEBABE ---> cafebabe
(byte) 0xF0, (byte) 0x07, (byte) 0xBA, (byte) 0x11, // F007BA11 ---> football
(byte) 0x0F, (byte) 0xF1, (byte) 0xCE // 0FF1CE ---> office
};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
IntBuffer intBuffer = buffer.asIntBuffer();
int capacity = intBuffer.capacity(); // 2
В приведенном выше фрагменте кода буфер имеет 11 элементов данных, а тип int занимает 4 байта. Таким образом, intBuffer будет иметь 2 элемента данных (11/4 = 2) и не включать лишние 3 байта (11% 4 = 3).
6. Прямой буфер
Что такое прямой буфер? Прямой буфер относится к базовым данным буфера, размещенным в области памяти, где функции ОС могут напрямую обращаться к ним. Непрямой буфер относится к буферу, базовые данные которого представляют собой массив байтов , выделенный в области кучи Java.
Тогда как мы можем создать прямой буфер? Прямой ByteBuffer создается путем вызова метода allocateDirect () с желаемой емкостью:
ByteBuffer buffer = ByteBuffer.allocateDirect(10);
Зачем нужен прямой буфер? Ответ прост: непрямой буфер всегда требует ненужных операций копирования. При отправке данных непрямого буфера на устройства ввода-вывода собственный код должен «заблокировать» базовый массив байтов , скопировать его за пределы кучи Java, а затем вызвать функцию ОС для сброса данных. Однако собственный код может напрямую обращаться к базовым данным и вызывать функции ОС для сброса данных без каких-либо дополнительных затрат с помощью прямого буфера.
В свете вышеизложенного, является ли прямой буфер идеальным? Нет. Основная проблема заключается в том, что выделять и освобождать прямой буфер дорого. Итак, в действительности всегда ли прямой буфер работает быстрее, чем непрямой буфер? Не обязательно. Это потому, что многие факторы в игре. И компромиссы производительности могут сильно различаться в зависимости от JVM, операционной системы и дизайна кода.
Наконец, существует практическое правило программного обеспечения, которому нужно следовать: сначала заставьте его работать, а затем сделайте его быстрым . Это означает, что давайте сначала сосредоточимся на правильности кода. Если код работает недостаточно быстро, то проведем соответствующую оптимизацию.
7. Разное
Класс ByteBuffer также предоставляет несколько вспомогательных методов:

7.1. Is-родственные методы
Метод isDirect() может сказать нам, является ли буфер прямым буфером или непрямым буфером. Обратите внимание, что обернутые буферы, созданные с помощью метода wrap() , всегда непрямые.
Все буферы доступны для чтения, но не все для записи. Метод isReadOnly() указывает, можем ли мы записывать базовые данные.
Чтобы сравнить эти два метода, метод isDirect() заботится о том, где находятся базовые данные, в куче Java или в области памяти . Однако метод isReadOnly() заботится о том, можно ли изменить базовые элементы данных .
Если исходный буфер является прямым или доступным только для чтения, новое сгенерированное представление унаследует эти атрибуты.
7.2. Методы, связанные с массивами
Если экземпляр ByteBuffer является прямым или доступным только для чтения, мы не можем получить его базовый массив байтов. Но если буфер не прямой и не предназначен только для чтения, это не обязательно означает, что его базовые данные доступны.
Чтобы быть точным, метод hasArray() может сказать нам, есть ли у буфера доступный резервный массив или нет . Если метод hasArray() возвращает true , то мы можем использовать методы array() и arrayOffset() для получения более релевантной информации.
7.3. Порядок байтов
По умолчанию порядок байтов класса ByteBuffer всегда равен ByteOrder.BIG_ENDIAN . И мы можем использовать методы order() и order(ByteOrder) для получения и установки текущего порядка байтов соответственно.
Порядок байтов влияет на то, как интерпретировать базовые данные. Например, предположим, что у нас есть экземпляр буфера :
byte[] bytes = new byte[]{(byte) 0xCA, (byte) 0xFE, (byte) 0xBA, (byte) 0xBE};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
Используя ByteOrder.BIG_ENDIAN , значение будет -889275714 (0xCAFEBABE) :
buffer.order(ByteOrder.BIG_ENDIAN);
int val = buffer.getInt();
Однако при использовании ByteOrder.LITTLE_ENDIAN val будет равен -1095041334 (0xBEBAFECA):
buffer.order(ByteOrder.LITTLE_ENDIAN);
int val = buffer.getInt();
7.4. Сравнение
Класс ByteBuffer предоставляет методы equals() и compareTo() для сравнения двух экземпляров буфера. Оба этих метода выполняют сравнение на основе оставшихся элементов данных, которые находятся в диапазоне [position, limit) .
Например, два экземпляра буфера с разными базовыми данными и индексами могут быть равны:
byte[] bytes1 = "World".getBytes(StandardCharsets.UTF_8);
byte[] bytes2 = "HelloWorld".getBytes(StandardCharsets.UTF_8);
ByteBuffer buffer1 = ByteBuffer.wrap(bytes1);
ByteBuffer buffer2 = ByteBuffer.wrap(bytes2);
buffer2.position(5);
boolean equal = buffer1.equals(buffer2); // true
int result = buffer1.compareTo(buffer2); // 0
8. Заключение
В этой статье мы попытались рассматривать класс ByteBuffer как луковую модель. Сначала мы упростили его до контейнера байтового массива с дополнительными индексами. Затем мы говорили о том, как использовать класс ByteBuffer для передачи данных из/в другие типы данных.
Затем мы рассмотрели одни и те же базовые данные с разных точек зрения. Наконец, мы обсудили прямой буфер и некоторые другие методы.
Как обычно, исходный код этого руководства можно найти на GitHub .