1. Обзор
В этой статье мы увидим значение коэффициента загрузки в HashMap Java и то, как он влияет на производительность карты.
2. Что такое HashMap ?
Класс HashMap принадлежит платформе Java Collection и обеспечивает базовую реализацию интерфейса Map . Мы можем использовать его, когда хотим хранить данные в виде пар ключ-значение. Эти пары ключ-значение называются записями карты и представлены классом Map.Entry .
3. Внутреннее устройство HashMap
Прежде чем обсуждать коэффициент загрузки, давайте рассмотрим несколько терминов:
перемешивание
вместимость
порог
перефразирование
столкновение
HashMap работает по принципу хеширования — алгоритму сопоставления данных объекта с некоторым репрезентативным целочисленным значением . Хеш-функция применяется к ключевому объекту для вычисления индекса корзины для хранения и извлечения любой пары ключ-значение.
Емкость — это количество сегментов в HashMap . Начальная емкость — это емкость на момент создания карты . Наконец, начальная емкость HashMap по умолчанию равна 16.
По мере увеличения количества элементов в HashMap емкость увеличивается. Коэффициент загрузки — это мера, которая определяет, когда следует увеличить емкость Карты . Коэффициент загрузки по умолчанию составляет 75% от емкости.
Порог HashMap приблизительно равен произведению текущей емкости и коэффициента загрузки. Перехеширование — это процесс пересчета хеш-кода уже сохраненных записей. Проще говоря, когда количество записей в хеш-таблице превышает пороговое значение, Карта повторно хешируется так, что она имеет примерно вдвое больше сегментов, чем раньше.
Коллизия возникает, когда хеш-функция возвращает одно и то же местоположение корзины для двух разных ключей.
Давайте создадим нашу HashMap :
Map<String, String> mapWithDefaultParams = new HashMap<>();
mapWithDefaultParams.put("1", "one");
mapWithDefaultParams.put("2", "two");
mapWithDefaultParams.put("3", "three");
mapWithDefaultParams.put("4", "four");
Вот структура нашей карты :
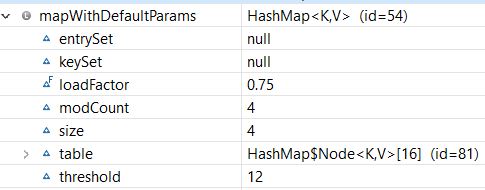
Как мы видим, наш HashMap был создан с начальной емкостью по умолчанию (16) и коэффициентом загрузки по умолчанию (0,75). Кроме того, порог равен 16 * 0,75 = 12, что означает, что емкость увеличится с 16 до 32 после добавления 12-й записи (пара «ключ-значение-пара»).
4. Пользовательская начальная мощность и коэффициент загрузки
В предыдущем разделе мы создали нашу HashMap с конструктором по умолчанию. В следующих разделах мы увидим, как создать HashMap , передав исходную емкость и коэффициент загрузки конструктору.
4.1. С начальной емкостью
Во-первых, давайте создадим карту с начальной емкостью:
Map<String, String> mapWithInitialCapacity = new HashMap<>(5);
Это создаст пустую карту с начальной емкостью (5) и коэффициентом загрузки по умолчанию (0,75).
4.2. С начальной мощностью и коэффициентом нагрузки
Точно так же мы можем создать нашу карту , используя как начальную емкость, так и коэффициент загрузки:
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5, 0.5f);
Здесь он создаст пустую карту с начальной емкостью 5 и коэффициентом загрузки 0,5.
5. Производительность
Хотя у нас есть возможность выбрать начальную емкость и коэффициент загрузки, нам нужно выбирать их с умом. Оба они влияют на производительность карты . Давайте углубимся в то, как эти параметры связаны с производительностью.
5.1. Сложность
Как мы знаем, HashMap внутренне использует хеш-код в качестве основы для хранения пар ключ-значение. Если метод hashCode() хорошо написан, HashMap распределит элементы по всем корзинам. Таким образом, HashMap сохраняет и извлекает записи за постоянное время O(1) .
Однако проблема возникает, когда количество элементов увеличивается, а размер корзины фиксирован. В каждом сегменте будет больше элементов, что нарушит временную сложность.
Решение состоит в том, что мы можем увеличить количество сегментов при увеличении количества элементов. Затем мы можем перераспределить элементы по всем корзинам. Таким образом, мы сможем поддерживать постоянное количество элементов в каждом сегменте и поддерживать временную сложность O(1) .
Здесь коэффициент загрузки помогает нам решить, когда увеличить количество сегментов . При более низком коэффициенте загрузки будет больше свободных ковшей и, следовательно, меньше шансов на столкновение. Это поможет нам добиться лучшей производительности для нашей карты . Следовательно, нам нужно поддерживать низкий коэффициент загрузки, чтобы добиться низкой временной сложности .
HashMap обычно имеет пространственную сложность O(n) , где n — количество записей. Более высокое значение коэффициента загрузки снижает затраты пространства, но увеличивает стоимость поиска .
5.2. Перефразирование
Когда количество элементов на карте превышает пороговое значение, вместимость карты удваивается. Как обсуждалось ранее, при увеличении емкости нам необходимо равномерно распределить все записи (включая существующие записи и новые записи) по всем корзинам. Здесь нам нужна перефразировка. То есть для каждой существующей пары ключ-значение снова вычислить хеш-код с увеличенной емкостью в качестве параметра.
В основном, когда коэффициент загрузки увеличивается, сложность увеличивается. Повторное хеширование выполняется для поддержания низкого коэффициента загрузки и низкой сложности всех операций.
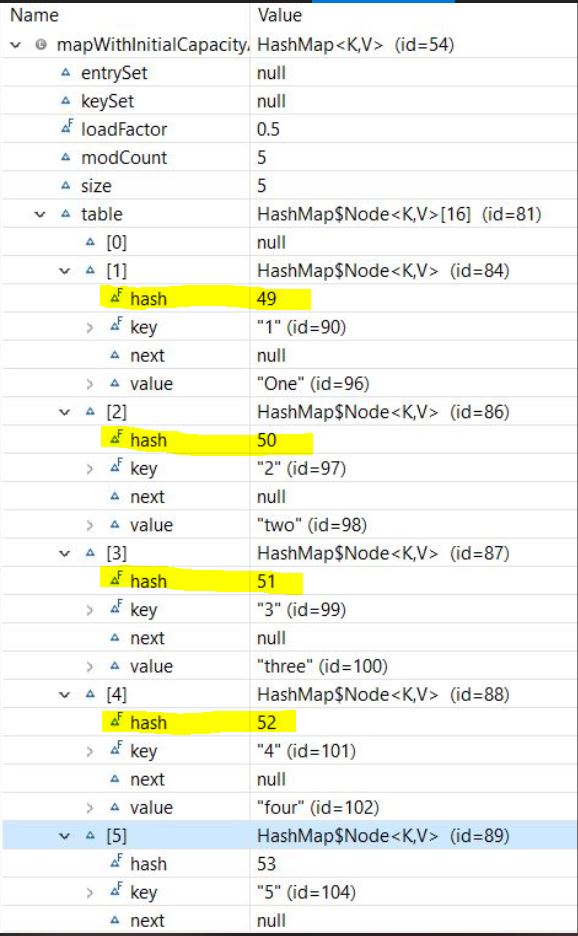
Давайте инициализируем нашу карту :
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5,0.75f);
mapWithInitialCapacityAndLF.put("1", "one");
mapWithInitialCapacityAndLF.put("2", "two");
mapWithInitialCapacityAndLF.put("3", "three");
mapWithInitialCapacityAndLF.put("4", "four");
mapWithInitialCapacityAndLF.put("5", "five");
И давайте посмотрим на структуру карты :
Теперь давайте добавим больше записей на нашу карту :
mapWithInitialCapacityAndLF.put("6", "Six");
mapWithInitialCapacityAndLF.put("7", "Seven");
//.. more entries
mapWithInitialCapacityAndLF.put("15", "fifteen");
И давайте снова посмотрим на структуру нашей карты :
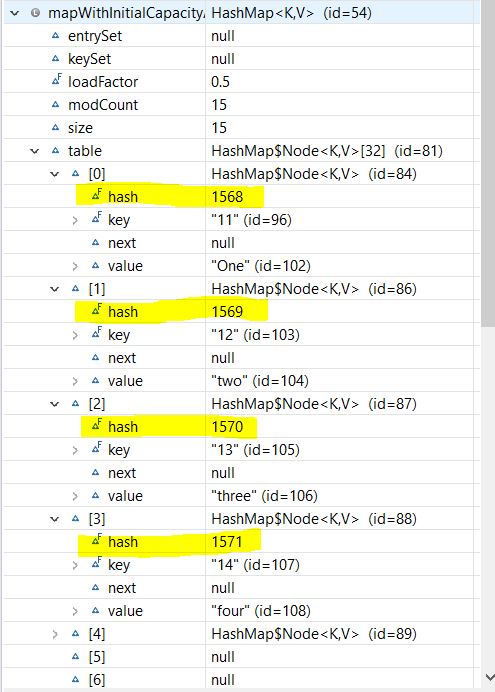
Хотя перефразирование помогает сохранить низкую сложность, это дорогостоящий процесс. Если нам нужно хранить огромное количество данных, мы должны создать нашу HashMap с достаточной емкостью. Это более эффективно, чем автоматическое перефразирование.
5.3. Столкновение
Коллизии могут возникать из-за плохого алгоритма хэш-кода и часто замедляют работу Карты .
До Java 8 HashMap в Java обрабатывает коллизии, используя LinkedList для хранения записей карты. Если ключ оказывается в той же корзине, где уже существует другая запись, он добавляется в начало LinkedList . В худшем случае это увеличит сложность до O(n) .
Чтобы избежать этой проблемы, Java 8 и более поздние версии используют сбалансированное дерево (также называемое красно-черным деревом ) вместо LinkedList для хранения конфликтующих записей. Это улучшает производительность HashMap в худшем случае с O(n) до O(log n) .
HashMap изначально использует LinkedList. Затем, когда количество записей превышает определенный порог, LinkedList заменяется сбалансированным двоичным деревом. Константа TREEIFY_THRESHOLD определяет это пороговое значение. В настоящее время это значение равно 8, что означает, что если в одном сегменте более 8 элементов, Map будет использовать дерево для их хранения.
6. Заключение
В этой статье мы обсудили одну из самых популярных структур данных: HashMap . Мы также увидели, как коэффициент загрузки вместе с емкостью влияет на его производительность.
Как всегда, примеры кода для этой статьи доступны на GitHub .