1. Обзор
В этом руководстве мы узнаем о кеше LRU и рассмотрим его реализацию на Java.
2. LRU-кэш
Кэш-память наименее использовавшихся (LRU) — это алгоритм вытеснения кэша, который упорядочивает элементы в порядке их использования. В LRU, как следует из названия, элемент, который не использовался дольше всего, будет удален из кэша.
Например, если у нас есть кэш емкостью три элемента:
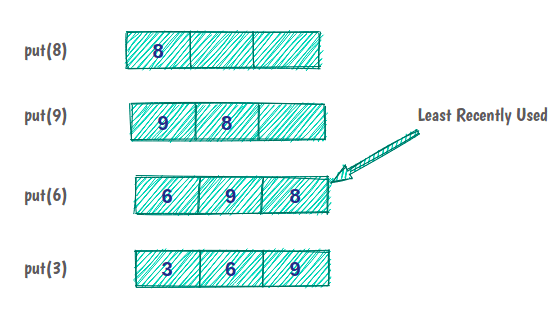
Изначально кеш пуст, и мы кладем в кеш элемент 8. Элементы 9 и 6 кэшируются, как и раньше. Но теперь емкость кеша заполнена, и чтобы поместить следующий элемент, мы должны удалить последний использованный элемент из кеша.
Прежде чем мы реализуем кеш LRU в Java, полезно знать некоторые аспекты кеша:
- Все операции должны выполняться в порядке O(1)
- Кэш имеет ограниченный размер
- Обязательно, чтобы все операции кэширования поддерживали параллелизм.
- Если кэш заполнен, добавление нового элемента должно вызывать стратегию LRU.
2.1. Структура кэша LRU
Теперь давайте подумаем над вопросом, который поможет нам в разработке кэша.
Как мы можем разработать структуру данных, которая могла бы выполнять такие операции, как чтение, сортировка (временная сортировка) и удаление элементов за постоянное время?
Похоже, чтобы найти ответ на этот вопрос, нам нужно глубоко задуматься над тем, что было сказано о кэше LRU и его особенностях:
- На практике LRU-кеш — это своего рода
Очередь —при повторном доступе к элементу он переходит в конец порядка вытеснения. - Эта очередь будет иметь определенную емкость, поскольку кэш имеет ограниченный размер. Всякий раз, когда вносится новый элемент, он добавляется в начало очереди. Когда происходит выселение, оно происходит из хвоста очереди.
- Обращение к данным в кеше должно выполняться за постоянное время, что невозможно в
Queue! Но это возможно с помощью структуры данныхHashMap в Java. - Удаление наименее использованного элемента должно выполняться за постоянное время, что означает, что для реализации
Queueмы будем использоватьDoublyLinkedListвместоSingleLinkedListили массива.
Итак, кэш LRU — это не что иное, как комбинация DoublyLinkedList и HashMap , как показано ниже:
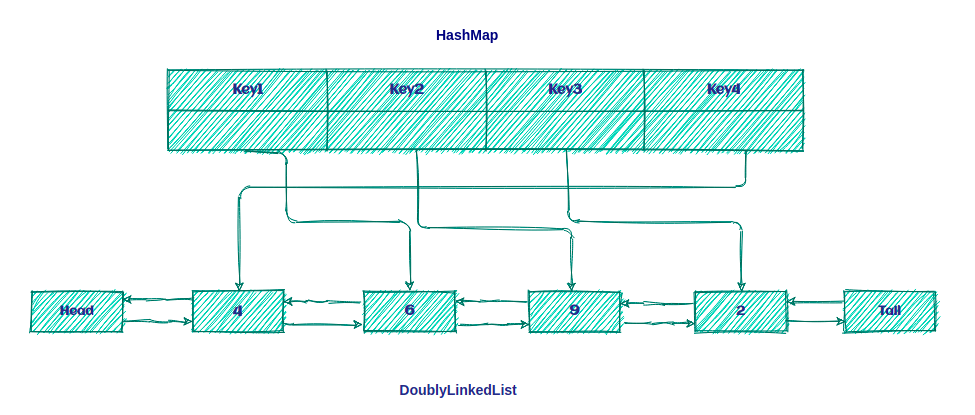
Идея состоит в том, чтобы сохранить ключи на Карте для быстрого доступа к данным внутри Очереди .
2.2. Алгоритм LRU
Алгоритм LRU довольно прост! Если ключ присутствует в HashMap, это попадание в кеш; в противном случае это промах кеша.
Мы выполним два шага после промаха кеша:
- Добавьте новый элемент перед списком.
- Добавьте новую запись в
HashMapи обратитесь к началу списка.
И мы сделаем два шага после попадания в кеш:
- Удалите элемент попадания и добавьте его перед списком.
- Обновите
HashMap, указав новую ссылку в начале списка.
Теперь пришло время посмотреть, как мы можем реализовать кеш LRU в Java!
3. Реализация на Java
Во-первых, мы определим наш интерфейс Cache :
public interface Cache<K, V> {
boolean set(K key, V value);
Optional<V> get(K key);
int size();
boolean isEmpty();
void clear();
}
Теперь мы определим класс LRUCache , который представляет наш кеш:
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new HashMap<>(maxSize);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// rest of the implementation
}
Мы можем создать экземпляр LRUCache определенного размера. В этой реализации мы используем коллекцию HashMap для хранения всех ссылок на LinkedListNode .
Теперь давайте обсудим операции с нашим LRUCache .
3.1. Положите операцию
Первый — это метод put :
public boolean put(K key, V value) {
CacheElement<K, V> item = new CacheElement<K, V>(key, value);
LinkedListNode<CacheElement<K, V>> newNode;
if (this.linkedListNodeMap.containsKey(key)) {
LinkedListNode<CacheElement<K, V>> node = this.linkedListNodeMap.get(key);
newNode = doublyLinkedList.updateAndMoveToFront(node, item);
} else {
if (this.size() >= this.size) {
this.evictElement();
}
newNode = this.doublyLinkedList.add(item);
}
if(newNode.isEmpty()) {
return false;
}
this.linkedListNodeMap.put(key, newNode);
return true;
}
Сначала мы находим ключ в linkedListNodeMap , в котором хранятся все ключи/ссылки. Если ключ существует, произошло попадание в кэш, и он готов извлечь CacheElement из DoublyLinkedList и переместить его на передний план .
После этого мы обновляем linkedListNodeMap новой ссылкой и перемещаем ее в начало списка:
public LinkedListNode<T> updateAndMoveToFront(LinkedListNode<T> node, T newValue) {
if (node.isEmpty() || (this != (node.getListReference()))) {
return dummyNode;
}
detach(node);
add(newValue);
return head;
}
Во-первых, мы проверяем, что узел не пуст. Кроме того, ссылка узла должна совпадать со списком. После этого мы отсоединяем узел от списка и добавляем в список newValue .
Но если ключ не существует, то произошел промах кеша, и мы должны поместить новый ключ в linkedListNodeMap . Прежде чем мы сможем это сделать, мы проверяем размер списка. Если список заполнен, мы должны исключить из списка последний использованный элемент.
3.2. Получить операцию
Давайте посмотрим на нашу операцию get :
public Optional<V> get(K key) {
LinkedListNode<CacheElement<K, V>> linkedListNode = this.linkedListNodeMap.get(key);
if(linkedListNode != null && !linkedListNode.isEmpty()) {
linkedListNodeMap.put(key, this.doublyLinkedList.moveToFront(linkedListNode));
return Optional.of(linkedListNode.getElement().getValue());
}
return Optional.empty();
}
Как мы видим выше, эта операция проста. Сначала мы получаем узел из linkedListNodeMap , а после этого проверяем, что он не нулевой и не пустой.
Остальная часть операции такая же, как и раньше, с одним отличием в методе moveToFront :
public LinkedListNode<T> moveToFront(LinkedListNode<T> node) {
return node.isEmpty() ? dummyNode : updateAndMoveToFront(node, node.getElement());
}
Теперь давайте создадим несколько тестов, чтобы убедиться, что наш кеш работает нормально:
@Test
public void addSomeDataToCache_WhenGetData_ThenIsEqualWithCacheElement(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
assertEquals("test1",lruCache.get("1").get());
assertEquals("test2",lruCache.get("2").get());
assertEquals("test3",lruCache.get("3").get());
}
Теперь давайте протестируем политику выселения:
@Test
public void addDataToCacheToTheNumberOfSize_WhenAddOneMoreData_ThenLeastRecentlyDataWillEvict(){
LRUCache<String,String> lruCache = new LRUCache<>(3);
lruCache.put("1","test1");
lruCache.put("2","test2");
lruCache.put("3","test3");
lruCache.put("4","test4");
assertFalse(lruCache.get("1").isPresent());
}
4. Работа с параллелизмом
До сих пор мы предполагали, что наш кеш просто использовался в однопоточной среде.
Чтобы сделать этот контейнер потокобезопасным, нам нужно синхронизировать все общедоступные методы. Давайте добавим ReentrantReadWriteLock и ConcurrentHashMap в предыдущую реализацию:
public class LRUCache<K, V> implements Cache<K, V> {
private int size;
private final Map<K, LinkedListNode<CacheElement<K,V>>> linkedListNodeMap;
private final DoublyLinkedList<CacheElement<K,V>> doublyLinkedList;
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
public LRUCache(int size) {
this.size = size;
this.linkedListNodeMap = new ConcurrentHashMap<>(size);
this.doublyLinkedList = new DoublyLinkedList<>();
}
// ...
}
Мы предпочитаем использовать реентерабельную блокировку чтения/записи, а не объявлять методы синхронизированными , потому что это дает нам больше гибкости при принятии решения о том, когда использовать блокировку чтения и записи.
4.1. записьLock
Теперь давайте добавим вызов writeLock в наш метод put :
public boolean put(K key, V value) {
this.lock.writeLock().lock();
try {
//..
} finally {
this.lock.writeLock().unlock();
}
}
Когда мы используем writeLock для ресурса, только поток, удерживающий блокировку, может записывать или читать из ресурса. Таким образом, все другие потоки, пытающиеся либо прочитать, либо записать ресурс, должны будут ждать, пока текущий держатель блокировки не освободит его.
Это очень важно для предотвращения взаимоблокировки . Если какая-либо из операций внутри блока try терпит неудачу, мы все равно снимаем блокировку перед выходом из функции с блоком finally в конце метода.
Еще одной операцией, которая требует writeLock , является evictElement , которую мы использовали в методе put :
private boolean evictElement() {
this.lock.writeLock().lock();
try {
//...
} finally {
this.lock.writeLock().unlock();
}
}
4.2. readLock
А теперь пришло время добавить вызов readLock в метод get :
public Optional<V> get(K key) {
this.lock.readLock().lock();
try {
//...
} finally {
this.lock.readLock().unlock();
}
}
Кажется, именно это мы и сделали с методом put . Единственная разница в том, что мы используем readLock вместо writeLock . Таким образом, это различие между блокировками чтения и записи позволяет нам читать кэш параллельно, пока он не обновляется.
Теперь давайте проверим наш кеш в параллельной среде:
@Test
public void runMultiThreadTask_WhenPutDataInConcurrentToCache_ThenNoDataLost() throws Exception {
final int size = 50;
final ExecutorService executorService = Executors.newFixedThreadPool(5);
Cache<Integer, String> cache = new LRUCache<>(size);
CountDownLatch countDownLatch = new CountDownLatch(size);
try {
IntStream.range(0, size).<Runnable>mapToObj(key -> () -> {
cache.put(key, "value" + key);
countDownLatch.countDown();
}).forEach(executorService::submit);
countDownLatch.await();
} finally {
executorService.shutdown();
}
assertEquals(cache.size(), size);
IntStream.range(0, size).forEach(i -> assertEquals("value" + i,cache.get(i).get()));
}
5. Вывод
В этом руководстве мы узнали, что такое кэш LRU, включая некоторые из его наиболее распространенных функций. Затем мы увидели один из способов реализации кэша LRU в Java и изучили некоторые из наиболее распространенных операций.
Наконец, мы рассмотрели параллелизм в действии с помощью механизма блокировки.
Как обычно, все примеры, использованные в этой статье, доступны на GitHub .