1. Введение
В этом руководстве мы рассмотрим некоторые основы тестирования параллельной программы. В первую очередь мы сосредоточимся на параллелизме на основе потоков и проблемах, которые он представляет при тестировании.
Мы также поймем, как решить некоторые из этих проблем и эффективно протестировать многопоточный код на Java.
2. Параллельное программирование
Параллельное программирование относится к программированию, в котором мы разбиваем большую часть вычислений на более мелкие, относительно независимые вычисления .
Целью этого упражнения является одновременное выполнение этих небольших вычислений, возможно, даже параллельно. Хотя есть несколько способов добиться этого, цель неизменно состоит в том, чтобы запустить программу быстрее.
2.1. Потоки и параллельное программирование
Поскольку процессоры содержат больше ядер, чем когда-либо, параллельное программирование выходит на первый план для их эффективного использования. Однако факт остается фактом: параллельные программы намного сложнее проектировать, писать, тестировать и поддерживать . Так что, если мы, в конце концов, сможем написать эффективные и автоматизированные тестовые примеры для параллельных программ, мы сможем решить большую часть этих проблем.
Итак, что же делает написание тестов для параллельного кода таким сложным? Чтобы понять это, мы должны понять, как мы достигаем параллелизма в наших программах. Один из самых популярных методов параллельного программирования включает использование потоков.
Теперь потоки могут быть нативными, и в этом случае они планируются базовыми операционными системами. Мы также можем использовать так называемые зеленые потоки, которые планируются непосредственно средой выполнения.
2.2. Сложность тестирования параллельных программ
Независимо от того, какой тип потоков мы используем, их использование затрудняет взаимодействие потоков. Если нам действительно удастся написать программу, в которой задействованы потоки, но нет связи между потоками, то нет ничего лучше! Более реалистично, потоки обычно должны взаимодействовать. Есть два способа добиться этого — разделяемая память и передача сообщений.
Большая часть проблем, связанных с параллельным программированием, возникает из-за использования собственных потоков с разделяемой памятью . Тестирование таких программ затруднено по тем же причинам. Несколько потоков с доступом к общей памяти обычно требуют взаимного исключения. Обычно мы достигаем этого с помощью некоторого защитного механизма, использующего блокировки.
Но это все равно может привести к множеству проблем, таких как условия гонки, живые блокировки, взаимоблокировки и голодание потоков , и это лишь некоторые из них. Более того, эти проблемы носят периодический характер, поскольку планирование потоков в случае нативных потоков полностью недетерминировано.
Следовательно, написание эффективных тестов для параллельных программ, которые могут обнаруживать эти проблемы детерминированным образом, действительно является сложной задачей!
2.3. Анатомия чередования потоков
Мы знаем, что нативные потоки могут быть запланированы операционными системами непредсказуемым образом. Если эти потоки обращаются к общим данным и изменяют их, это приводит к интересному чередованию потоков . В то время как некоторые из этих перемежений могут быть вполне приемлемыми, другие могут оставить окончательные данные в нежелательном состоянии.
Возьмем пример. Предположим, у нас есть глобальный счетчик, который увеличивается с каждым потоком. К концу обработки мы хотели бы, чтобы состояние этого счетчика было точно таким же, как количество выполненных потоков:
private int counter;
public void increment() {
counter++;
}
Теперь увеличение примитивного целого числа в Java не является атомарной операцией . Он состоит из чтения значения, его увеличения и, наконец, сохранения. Когда несколько потоков выполняют одну и ту же операцию, это может привести к множеству возможных чередований:
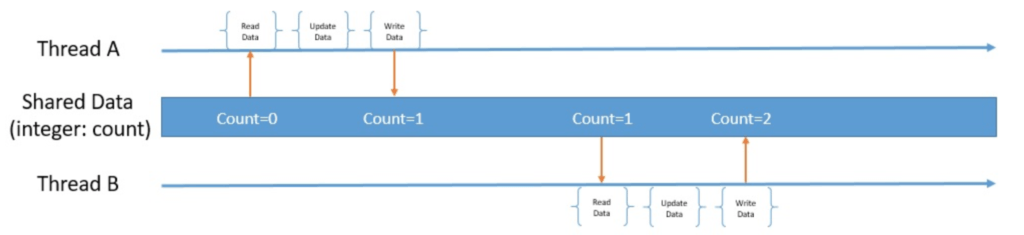
Хотя это конкретное чередование дает вполне приемлемые результаты, как насчет этого:
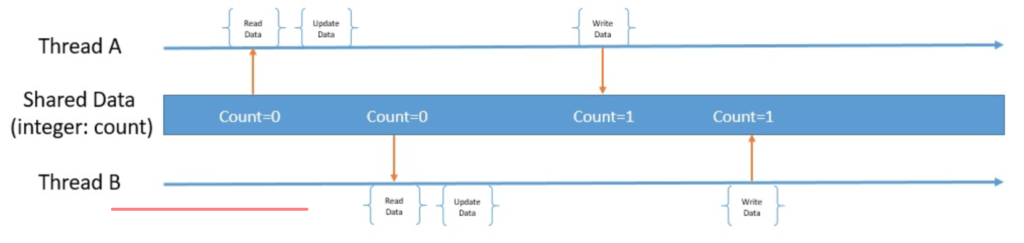
Это не то, что мы ожидали. А теперь представьте сотни потоков, выполняющих гораздо более сложный код. Это приведет к невообразимым способам чередования потоков.
Есть несколько способов написать код, позволяющий избежать этой проблемы, но это не является предметом данного руководства. Синхронизация с помощью блокировки — одна из распространенных, но у нее есть свои проблемы, связанные с условиями гонки.
3. Тестирование многопоточного кода
Теперь, когда мы понимаем основные проблемы тестирования многопоточного кода, мы увидим, как их преодолеть. Мы создадим простой вариант использования и попытаемся смоделировать как можно больше проблем, связанных с параллелизмом.
Давайте начнем с определения простого класса, который подсчитывает, возможно, что угодно:
public class MyCounter {
private int count;
public void increment() {
int temp = count;
count = temp + 1;
}
// Getter for count
}
Это, казалось бы, безобидный фрагмент кода, но нетрудно понять, что он не является потокобезопасным . Если нам случится написать параллельную программу с этим классом, она обязательно будет дефектной. Целью тестирования здесь является выявление таких дефектов.
3.1. Тестирование неконкурентных частей
Как правило, всегда рекомендуется тестировать код, изолируя его от любого параллельного поведения . Это делается для того, чтобы разумно убедиться, что в коде нет других дефектов, не связанных с параллелизмом. Давайте посмотрим, как мы можем это сделать:
@Test
public void testCounter() {
MyCounter counter = new MyCounter();
for (int i = 0; i < 500; i++) {
counter.increment();
}
assertEquals(500, counter.getCount());
}
Хотя здесь ничего особенного не происходит, этот тест дает нам уверенность в том, что он работает, по крайней мере, в отсутствие параллелизма.
3.2. Первая попытка тестирования с параллелизмом
Давайте снова протестируем тот же код, на этот раз в параллельной настройке. Мы попробуем получить доступ к одному и тому же экземпляру этого класса с несколькими потоками и посмотрим, как он себя поведет:
@Test
public void testCounterWithConcurrency() throws InterruptedException {
int numberOfThreads = 10;
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
MyCounter counter = new MyCounter();
for (int i = 0; i < numberOfThreads; i++) {
service.execute(() -> {
counter.increment();
latch.countDown();
});
}
latch.await();
assertEquals(numberOfThreads, counter.getCount());
}
Этот тест разумен, так как мы пытаемся работать с общими данными с несколькими потоками. Поскольку мы сохраняем небольшое количество потоков, например 10, мы заметим, что он проходит почти все время. Интересно, что если мы начнем увеличивать количество потоков, скажем, до 100, то увидим, что тест начинает падать большую часть времени .
3.3. Лучшая попытка тестирования с параллелизмом
Хотя предыдущий тест показал, что наш код не является потокобезопасным, с этим тестом возникла проблема. Этот тест не является детерминированным, поскольку базовые потоки чередуются недетерминированным образом. Мы действительно не можем полагаться на этот тест для нашей программы.
Что нам нужно, так это способ управления чередованием потоков, чтобы мы могли выявлять проблемы параллелизма детерминированным образом с гораздо меньшим количеством потоков. Мы начнем с небольшой настройки кода, который мы тестируем:
public synchronized void increment() throws InterruptedException {
int temp = count;
wait(100);
count = temp + 1;
}
Здесь мы сделали метод синхронизированным и ввели ожидание между двумя шагами внутри метода. Синхронизированное ключевое слово гарантирует, что только один поток может изменять переменную счетчика за раз, а ожидание вводит задержку между выполнением каждого потока.
Обратите внимание, что нам не обязательно изменять код, который мы собираемся тестировать. Однако, поскольку существует не так много способов повлиять на планирование потоков, мы прибегаем к этому.
В следующем разделе мы увидим, как это можно сделать без изменения кода.
Теперь давайте протестируем этот код так же, как и раньше:
@Test
public void testSummationWithConcurrency() throws InterruptedException {
int numberOfThreads = 2;
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
MyCounter counter = new MyCounter();
for (int i = 0; i < numberOfThreads; i++) {
service.submit(() -> {
try {
counter.increment();
} catch (InterruptedException e) {
// Handle exception
}
latch.countDown();
});
}
latch.await();
assertEquals(numberOfThreads, counter.getCount());
}
Здесь мы запускаем это только с двумя потоками, и есть вероятность, что мы сможем получить дефект, который мы упустили. Здесь мы попытались добиться определенного чередования потоков, которое, как мы знаем, может повлиять на нас. Это хорошо для демонстрации, но может оказаться бесполезным для практических целей .
4. Доступные инструменты тестирования
По мере роста числа потоков возможное количество способов их чередования растет экспоненциально. Просто невозможно вычислить все такие чередования и протестировать их . Мы должны полагаться на инструменты, чтобы предпринять те же или аналогичные усилия для нас. К счастью, есть пара из них, которые облегчают нашу жизнь.
Для тестирования параллельного кода нам доступны две широкие категории инструментов. Первый позволяет нам производить достаточно высокую нагрузку на параллельный код с большим количеством потоков. Стресс увеличивает вероятность редкого чередования и, таким образом, увеличивает наши шансы найти дефекты.
Второй позволяет нам имитировать определенное чередование потоков, тем самым помогая нам находить дефекты с большей уверенностью.
4.1. темпус-фугит
Java - библиотека tempus-fugit помогает нам с легкостью писать и тестировать параллельный код . Здесь мы просто сосредоточимся на тестовой части этой библиотеки. Ранее мы видели, что создание нагрузки на код с несколькими потоками увеличивает вероятность обнаружения дефектов, связанных с параллелизмом.
Хотя мы можем написать утилиту для создания стресса самостоятельно, tempus-fugit предоставляет удобные способы добиться того же.
Давайте вернемся к тому же коду, для которого мы пытались создать стресс ранее, и поймем, как мы можем добиться того же, используя tempus-fugit:
public class MyCounterTests {
@Rule
public ConcurrentRule concurrently = new ConcurrentRule();
@Rule
public RepeatingRule rule = new RepeatingRule();
private static MyCounter counter = new MyCounter();
@Test
@Concurrent(count = 10)
@Repeating(repetition = 10)
public void runsMultipleTimes() {
counter.increment();
}
@AfterClass
public static void annotatedTestRunsMultipleTimes() throws InterruptedException {
assertEquals(counter.getCount(), 100);
}
}
Здесь мы используем два правила , доступных нам из tempus-fugit. Эти правила перехватывают тесты и помогают нам применять желаемое поведение, например повторение и параллелизм. Таким образом, мы фактически повторяем тестируемую операцию десять раз в каждом из десяти разных потоков.
По мере увеличения повторения и параллелизма наши шансы обнаружить дефекты, связанные с параллелизмом, будут увеличиваться.
4.2. Нить ткач
Thread Weaver — это, по сути , Java-фреймворк для тестирования многопоточного кода . Ранее мы видели, что чередование потоков совершенно непредсказуемо, и, следовательно, мы можем никогда не обнаружить определенные дефекты с помощью регулярных тестов. Что нам действительно нужно, так это способ управления чередованием и тестирование всех возможных чередований. Это оказалось довольно сложной задачей в нашей предыдущей попытке.
Давайте посмотрим, как Thread Weaver может помочь нам в этом. Thread Weaver позволяет нам чередовать выполнение двух отдельных потоков большим количеством способов, не беспокоясь о том, как это сделать. Это также дает нам возможность точного контроля над тем, как мы хотим, чтобы потоки чередовались.
Давайте посмотрим, как мы можем улучшить нашу предыдущую наивную попытку:
public class MyCounterTests {
private MyCounter counter;
@ThreadedBefore
public void before() {
counter = new MyCounter();
}
@ThreadedMain
public void mainThread() {
counter.increment();
}
@ThreadedSecondary
public void secondThread() {
counter.increment();
}
@ThreadedAfter
public void after() {
assertEquals(2, counter.getCount());
}
@Test
public void testCounter() {
new AnnotatedTestRunner().runTests(this.getClass(), MyCounter.class);
}
}
Здесь мы определили два потока, которые пытаются увеличить наш счетчик. Thread Weaver попытается запустить этот тест с этими потоками во всех возможных сценариях чередования. Возможно, в одном из чередований мы получим дефект, который вполне очевиден в нашем коде.
4.3. МногопоточныйTC
MultithreadedTC — еще один фреймворк для тестирования параллельных приложений . Он оснащен метрономом, который используется для точного управления последовательностью действий в нескольких потоках. Он поддерживает тестовые случаи, которые осуществляют определенное чередование потоков. Следовательно, в идеале мы должны иметь возможность детерминистически тестировать каждое значимое чередование в отдельном потоке.
Полное введение в эту многофункциональную библиотеку выходит за рамки данного руководства. Но мы, безусловно, можем увидеть, как быстро настроить тесты, которые предоставят нам возможные чередования между исполняющимися потоками.
Давайте посмотрим, как мы можем более детерминировано протестировать наш код с помощью MultithreadedTC:
public class MyTests extends MultithreadedTestCase {
private MyCounter counter;
@Override
public void initialize() {
counter = new MyCounter();
}
public void thread1() throws InterruptedException {
counter.increment();
}
public void thread2() throws InterruptedException {
counter.increment();
}
@Override
public void finish() {
assertEquals(2, counter.getCount());
}
@Test
public void testCounter() throws Throwable {
TestFramework.runManyTimes(new MyTests(), 1000);
}
}
Здесь мы настраиваем два потока для работы с общим счетчиком и увеличения его. Мы настроили MultithreadedTC для выполнения этого теста с этими потоками до тысячи различных чередований, пока не обнаружит один из них, который не работает.
4.4. Java _
OpenJDK поддерживает проект Code Tool, чтобы предоставить инструменты разработчика для работы над проектами OpenJDK. В рамках этого проекта есть несколько полезных инструментов, в том числе стресс-тесты параллелизма Java (jcstress) . Он разрабатывается как экспериментальная система и набор тестов для проверки правильности поддержки параллелизма в Java.
Хотя это экспериментальный инструмент, мы все еще можем использовать его для анализа параллельного кода и написания тестов для финансирования дефектов, связанных с ним. Давайте посмотрим, как мы можем протестировать код, который мы использовали до сих пор в этом руководстве. Концепция очень похожа с точки зрения использования:
@JCStressTest
@Outcome(id = "1", expect = ACCEPTABLE_INTERESTING, desc = "One update lost.")
@Outcome(id = "2", expect = ACCEPTABLE, desc = "Both updates.")
@State
public class MyCounterTests {
private MyCounter counter;
@Actor
public void actor1() {
counter.increment();
}
@Actor
public void actor2() {
counter.increment();
}
@Arbiter
public void arbiter(I_Result r) {
r.r1 = counter.getCount();
}
}
Здесь мы пометили класс аннотацией State , которая указывает, что он содержит данные, измененные несколькими потоками. Кроме того, мы используем аннотацию Actor , которая помечает методы, содержащие действия, выполняемые разными потоками.
Наконец, у нас есть метод, помеченный аннотацией Arbiter , который, по сути, посещает состояние только после того , как его посетили все Актеры . Мы также использовали аннотацию «Результат » , чтобы определить наши ожидания.
В целом, настройка довольно проста и интуитивно понятна. Мы можем запустить это, используя тестовую обвязку, предоставленную фреймворком, которая находит все классы, аннотированные с помощью JCStressTest, и выполняет их в несколько итераций, чтобы получить все возможные чередования.
5. Другие способы обнаружения проблем параллелизма
Написание тестов для параллельного кода сложно, но возможно. Мы видели проблемы и некоторые популярные способы их преодоления. Однако мы не можем выявить все возможные проблемы параллелизма только с помощью тестов, особенно когда дополнительные затраты на написание большего количества тестов начинают перевешивать их преимущества.
Следовательно, вместе с разумным количеством автоматических тестов мы можем использовать другие методы для выявления проблем параллелизма. Это повысит наши шансы на обнаружение проблем параллелизма, не слишком углубляясь в сложность автоматических тестов. Мы рассмотрим некоторые из них в этом разделе.
5.1. Статический анализ
Статический анализ относится к анализу программы без ее фактического выполнения . Что хорошего может сделать такой анализ? Мы подойдем к этому, но давайте сначала поймем, как это отличается от динамического анализа. Модульные тесты, которые мы написали до сих пор, должны запускаться при фактическом выполнении программы, которую они тестируют. Именно по этой причине они являются частью того, что мы в основном называем динамическим анализом.
Обратите внимание, что статический анализ никоим образом не заменяет динамический анализ. Однако он предоставляет бесценный инструмент для изучения структуры кода и выявления возможных дефектов задолго до того, как мы его выполним. Статический анализ использует множество шаблонов, созданных с учетом опыта и понимания.
Хотя вполне возможно просто просмотреть код и сравнить с лучшими практиками и правилами, которые мы курировали, мы должны признать, что это неприемлемо для более крупных программ. Однако есть несколько инструментов, доступных для выполнения этого анализа. Они довольно зрелые, с обширным набором правил для большинства популярных языков программирования.
Распространенным инструментом статического анализа для Java является FindBugs . FindBugs ищет экземпляры «образцов ошибок». Шаблон ошибки — это идиома кода, которая довольно часто является ошибкой. Это может произойти из-за нескольких причин, таких как сложные языковые особенности, неправильно понятые методы и неправильно понятые инварианты.
FindBugs проверяет байт-код Java на наличие шаблонов ошибок без фактического выполнения байт-кода. Это довольно удобно в использовании и быстро работает. FindBugs сообщает об ошибках, относящихся ко многим категориям, таким как условия, дизайн и дублированный код.
Сюда также входят дефекты, связанные с параллелизмом. Однако следует отметить, что FindBugs может сообщать о ложных срабатываниях. На практике их меньше, но их необходимо соотносить с ручным анализом.
5.2. Проверка модели
Проверка модели — это метод проверки того, соответствует ли модель системы с конечным числом состояний заданной спецификации . Это определение может показаться слишком академическим, но потерпите его некоторое время!
Обычно мы можем представить вычислительную задачу в виде конечного автомата. Хотя это сама по себе обширная область, она дает нам модель с конечным набором состояний и правил перехода между ними с четко определенными начальными и конечными состояниями.
Теперь спецификация определяет, как должна вести себя модель, чтобы считать ее корректной . По сути, эта спецификация содержит все требования системы, которую представляет модель. Одним из способов получения спецификаций является использование формулы темпоральной логики, разработанной Амиром Пнуэли.
Хотя логически возможно выполнить проверку модели вручную, это совершенно непрактично. К счастью, есть много инструментов, которые могут помочь нам в этом. Одним из таких инструментов, доступных для Java, является Java PathFinder (JPF). JPF был разработан с учетом многолетнего опыта и исследований НАСА.
В частности, JPF — это средство проверки модели для байт-кода Java . Он запускает программу всеми возможными способами, тем самым проверяя нарушения свойств, такие как взаимоблокировка и необработанные исключения, на всех возможных путях выполнения. Поэтому он может оказаться весьма полезным при поиске дефектов, связанных с параллелизмом в любой программе.
6. Запоздалые мысли
К настоящему моменту нас не должно удивлять, что лучше избегать сложностей, связанных с многопоточным кодом , насколько это возможно. Разработка программ с более простым дизайном, которые легче тестировать и поддерживать, должна быть нашей главной целью. Мы должны согласиться с тем, что параллельное программирование часто необходимо для современных приложений.
Тем не менее, мы можем использовать несколько лучших практик и принципов при разработке параллельных программ , которые могут облегчить нашу жизнь. В этом разделе мы рассмотрим некоторые из этих лучших практик, но мы должны помнить, что этот список далеко не полный!
6.1. Уменьшить сложность
Сложность — это фактор, который может затруднить тестирование программы даже без каких-либо параллельных элементов. Это просто усложняется перед лицом параллелизма. Нетрудно понять, почему более простые и небольшие программы легче анализировать и, следовательно, эффективно тестировать . Есть несколько лучших шаблонов, которые могут помочь нам в этом, например, SRP (Single Responsibility Pattern) и KISS (Keep It Stupid Simple), и это лишь некоторые из них.
Теперь, хотя они и не решают проблему написания тестов для параллельного кода напрямую, они облегчают работу.
6.2. Рассмотрим атомарные операции
Атомарные операции — это операции, которые выполняются полностью независимо друг от друга . Следовательно, можно просто избежать трудностей прогнозирования и тестирования перемежения. Сравнить и поменять местами — одна из таких широко используемых атомарных инструкций. Проще говоря, он сравнивает содержимое ячейки памяти с заданным значением и, только если они совпадают, изменяет содержимое этой ячейки памяти.
Большинство современных микропроцессоров предлагают тот или иной вариант этой инструкции. Java предлагает ряд атомарных классов, таких как AtomicInteger и AtomicBoolean , предлагающих преимущества инструкций сравнения и замены под ними.
6.3. Примите неизменность
В многопоточном программировании общие данные, которые можно изменить, всегда оставляют место для ошибок. Неизменяемость относится к состоянию, при котором структура данных не может быть изменена после создания экземпляра . Это совпадение, созданное на небесах для параллельных программ. Если состояние объекта не может быть изменено после его создания, конкурирующие потоки не должны применять к ним взаимное исключение. Это значительно упрощает написание и тестирование параллельных программ.
Однако обратите внимание, что у нас не всегда может быть свобода выбора неизменности, но мы должны выбирать ее, когда это возможно.
6.4. Избегайте общей памяти
Большинство проблем, связанных с многопоточным программированием, можно отнести к тому факту, что у нас есть общая память между конкурирующими потоками. Что, если бы мы могли просто избавиться от них! Что ж, нам все еще нужен какой-то механизм для взаимодействия потоков.
Существуют альтернативные шаблоны проектирования для параллельных приложений, которые предлагают нам такую возможность . Одной из популярных является акторная модель, предписывающая актор в качестве базовой единицы параллелизма. В этой модели акторы взаимодействуют друг с другом, отправляя сообщения.
Akka — это фреймворк, написанный на Scala, который использует акторную модель для улучшения примитивов параллелизма.
7. Заключение
В этом уроке мы рассмотрели некоторые основы параллельного программирования. Мы подробно обсудили многопоточный параллелизм в Java. Мы прошли через проблемы, которые он ставит перед нами при тестировании такого кода, особенно с общими данными. Кроме того, мы рассмотрели некоторые инструменты и методы, доступные для тестирования параллельного кода.
Мы также обсудили другие способы избежать проблем с параллелизмом, включая инструменты и методы помимо автоматических тестов. Наконец, мы рассмотрели некоторые передовые методы программирования, связанные с параллельным программированием.
Исходный код этой статьи можно найти на GitHub .