1. Обзор
Apache Kafka — это масштабируемая, высокопроизводительная платформа с малой задержкой, которая позволяет считывать и записывать потоки данных, как система обмена сообщениями . Мы можем довольно легко начать с Kafka в Java .
Spark Streaming является частью платформы Apache Spark , обеспечивающей масштабируемую, высокопроизводительную и отказоустойчивую обработку потоков данных . Хотя Spark написан на Scala, он предлагает API-интерфейсы Java для работы с .
Apache Cassandra — это распределенное хранилище данных NoSQL с широкими столбцами . Более подробная информация о Cassandra доступна в нашей предыдущей статье.
В этом руководстве мы объединим их, чтобы создать хорошо масштабируемый и отказоустойчивый конвейер данных для потока данных в реальном времени .
2. Установки
Для начала нам понадобятся Kafka, Spark и Cassandra, установленные локально на нашем компьютере для запуска приложения. По ходу дела мы увидим, как разработать конвейер данных с использованием этих платформ.
Однако мы оставим все конфигурации по умолчанию, включая порты для всех установок, что поможет обеспечить бесперебойную работу учебника.
2.1. Кафка
Установка Kafka на нашу локальную машину довольно проста и может быть найдена как часть официальной документации . Мы будем использовать версию 2.1.0 Kafka.
Кроме того, Kafka требует запуска Apache Zookeeper , но для целей этого руководства мы будем использовать экземпляр Zookeeper с одним узлом, упакованный с Kafka.
После того, как нам удалось запустить Zookeeper и Kafka локально, следуя официальному руководству, мы можем приступить к созданию нашей темы под названием «сообщения»:
$KAFKA_HOME$\bin\windows\kafka-topics.bat --create \
--zookeeper localhost:2181 \
--replication-factor 1 --partitions 1 \
--topic messages
Обратите внимание, что приведенный выше сценарий предназначен для платформы Windows, но есть аналогичные сценарии, доступные и для Unix-подобных платформ.
2.2. Искра
Spark использует клиентские библиотеки Hadoop для HDFS и YARN. Следовательно, может быть очень сложно собрать совместимые версии всех этих файлов . Однако официальная загрузка Spark поставляется с предварительно упакованными популярными версиями Hadoop. В этом руководстве мы будем использовать пакет версии 2.3.0, «предварительно созданный для Apache Hadoop 2.7 и более поздних версий».
После распаковки нужного пакета Spark доступные сценарии можно использовать для отправки приложений. Мы увидим это позже, когда будем разрабатывать наше приложение в Spring Boot.
2.3. Кассандра
DataStax предоставляет общедоступную версию Cassandra для различных платформ, включая Windows. Мы можем легко загрузить и установить его на наш локальный компьютер, следуя официальной документации . Мы будем использовать версию 3.9.0.
После того, как нам удалось установить и запустить Cassandra на нашем локальном компьютере, мы можем приступить к созданию нашего пространства ключей и таблицы. Это можно сделать с помощью оболочки CQL, которая поставляется с нашей установкой:
CREATE KEYSPACE vocabulary
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
USE vocabulary;
CREATE TABLE words (word text PRIMARY KEY, count int);
Обратите внимание, что мы создали пространство имен под названием « словарь » и таблицу в нем под названием « слова » с двумя столбцами, « слово » и « количество » .
3. Зависимости
Мы можем интегрировать зависимости Kafka и Spark в наше приложение через Maven. Мы возьмем эти зависимости из Maven Central:
И мы можем добавить их в наш pom соответственно:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector-java_2.11</artifactId>
<version>1.5.2</version>
</dependency>
Обратите внимание, что некоторые из этих зависимостей помечены как предоставленные в области действия. Это связано с тем, что они будут доступны при установке Spark, где мы отправим приложение на выполнение с помощью spark-submit.
4. Spark Streaming — стратегии интеграции Kafka
На этом этапе стоит кратко рассказать о стратегиях интеграции Spark и Kafka.
Kafka представила новый потребительский API между версиями 0.8 и 0.10. Следовательно, соответствующие пакеты Spark Streaming доступны для обеих версий брокера. Важно выбрать правильный пакет в зависимости от доступного брокера и желаемых функций.
4.1. Искра Потоковая Кафка 0.8
Версия 0.8 — это стабильный API интеграции с вариантами использования Receiver-based или Direct Approach . Мы не будем вдаваться в подробности этих подходов, которые можно найти в официальной документации . Здесь важно отметить, что этот пакет совместим с версией Kafka Broker 0.8.2.1 или выше.
4.2. Искра Потоковая Кафка 0.10
В настоящее время он находится в экспериментальном состоянии и совместим только с версиями Kafka Broker 0.10.0 или выше. Этот пакет предлагает только прямой подход, теперь использующий новый потребительский API Kafka . Подробнее об этом мы можем узнать в официальной документации . Важно отметить, что он не имеет обратной совместимости со старыми версиями Kafka Broker .
Обратите внимание, что для этого руководства мы будем использовать пакет 0.10. Зависимость, упомянутая в предыдущем разделе, относится только к этому.
5. Разработка конвейера данных
Мы создадим простое приложение на Java с помощью Spark, которое будет интегрироваться с темой Kafka, которую мы создали ранее. Приложение будет читать сообщения в том виде, в котором они были опубликованы, и подсчитывать частоту слов в каждом сообщении. Затем это будет обновлено в таблице Cassandra, которую мы создали ранее.
Давайте быстро представим, как будут передаваться данные:
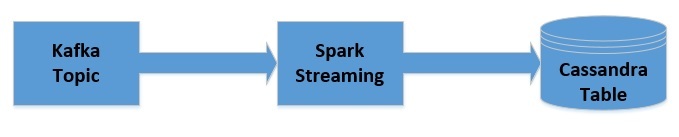
5.1. Получение JavaStreamingContext
Во-первых, мы начнем с инициализации JavaStreamingContext , который является точкой входа для всех приложений Spark Streaming :
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("WordCountingApp");
sparkConf.set("spark.cassandra.connection.host", "127.0.0.1");
JavaStreamingContext streamingContext = new JavaStreamingContext(
sparkConf, Durations.seconds(1));
5.2. Получение DStream от Kafka
Теперь мы можем подключиться к топику Kafka из JavaStreamingContext :
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
Collection<String> topics = Arrays.asList("messages");
JavaInputDStream<ConsumerRecord<String, String>> messages =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String> Subscribe(topics, kafkaParams));
Обратите внимание, что здесь мы должны предоставить десериализаторы для ключа и значения. Для распространенных типов данных, таких как String , десериализатор доступен по умолчанию . Однако, если мы хотим получить пользовательские типы данных, нам придется предоставить пользовательские десериализаторы.
Здесь мы получили JavaInputDStream , который является реализацией Discretized Streams или DStreams, базовой абстракции, предоставляемой Spark Streaming . Внутренне DStreams — это не что иное, как непрерывная серия RDD.
5.3. Обработка полученного DStream
Теперь мы выполним серию операций над JavaInputDStream , чтобы получить частоты слов в сообщениях:
JavaPairDStream<String, String> results = messages
.mapToPair(
record -> new Tuple2<>(record.key(), record.value())
);
JavaDStream<String> lines = results
.map(
tuple2 -> tuple2._2()
);
JavaDStream<String> words = lines
.flatMap(
x -> Arrays.asList(x.split("\\s+")).iterator()
);
JavaPairDStream<String, Integer> wordCounts = words
.mapToPair(
s -> new Tuple2<>(s, 1)
).reduceByKey(
(i1, i2) -> i1 + i2
);
5.4. Сохранение обработанного DStream в Cassandra
Наконец, мы можем перебрать обработанный JavaPairDStream , чтобы вставить его в нашу таблицу Cassandra:
wordCounts.foreachRDD(
javaRdd -> {
Map<String, Integer> wordCountMap = javaRdd.collectAsMap();
for (String key : wordCountMap.keySet()) {
List<Word> wordList = Arrays.asList(new Word(key, wordCountMap.get(key)));
JavaRDD<Word> rdd = streamingContext.sparkContext().parallelize(wordList);
javaFunctions(rdd).writerBuilder(
"vocabulary", "words", mapToRow(Word.class)).saveToCassandra();
}
}
);
5.5. Запуск приложения
Поскольку это приложение для потоковой обработки, мы хотели бы, чтобы это продолжалось:
streamingContext.start();
streamingContext.awaitTermination();
6. Использование контрольных точек
В приложении потоковой обработки часто полезно сохранять состояние между обрабатываемыми пакетами данных .
Например, в нашей предыдущей попытке мы смогли сохранить только текущую частоту слов. Что, если вместо этого мы хотим сохранить кумулятивную частоту? Spark Streaming делает это возможным благодаря концепции, называемой контрольными точками.
Теперь мы изменим конвейер, который мы создали ранее, чтобы использовать контрольные точки:
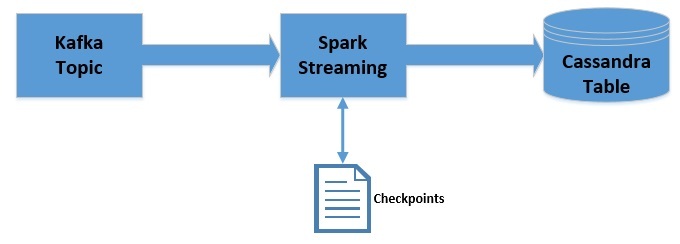
Обратите внимание, что мы будем использовать контрольные точки только для сеанса обработки данных. Это не обеспечивает отказоустойчивости. Однако контрольные точки также можно использовать для обеспечения отказоустойчивости.
Есть несколько изменений, которые мы должны внести в наше приложение, чтобы использовать контрольные точки. Это включает предоставление JavaStreamingContext местоположения контрольной точки:
streamingContext.checkpoint("./.checkpoint");
Здесь мы используем локальную файловую систему для хранения контрольных точек. Однако для надежности его следует хранить в таком месте, как HDFS, S3 или Kafka. Подробнее об этом можно прочитать в официальной документации .
Затем нам нужно будет получить контрольную точку и создать совокупное количество слов при обработке каждого раздела с помощью функции сопоставления:
JavaMapWithStateDStream<String, Integer, Integer, Tuple2<String, Integer>> cumulativeWordCounts = wordCounts
.mapWithState(
StateSpec.function(
(word, one, state) -> {
int sum = one.orElse(0) + (state.exists() ? state.get() : 0);
Tuple2<String, Integer> output = new Tuple2<>(word, sum);
state.update(sum);
return output;
}
)
);
Как только мы получим общее количество слов, мы можем продолжить итерацию и сохранить их в Cassandra, как и раньше.
Обратите внимание, что, хотя контрольные точки данных полезны для обработки с отслеживанием состояния, они сопряжены с задержкой . Следовательно, необходимо использовать это с умом вместе с оптимальным интервалом контрольных точек.
7. Понимание смещений
Если мы вспомним некоторые из параметров Kafka, которые мы установили ранее:
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
В основном это означает, что мы не хотим автоматически фиксировать смещение и хотели бы выбирать последнее смещение каждый раз, когда инициализируется группа потребителей . Следовательно, наше приложение сможет использовать сообщения, отправленные только в течение периода его работы.
Если мы хотим использовать все отправленные сообщения независимо от того, запущено приложение или нет, а также хотим отслеживать уже отправленные сообщения, нам придется соответствующим образом настроить смещение вместе с сохранением состояния смещения, хотя это немного выходит за рамки данного руководства.
Это также способ, которым Spark Streaming предлагает определенный уровень гарантии, такой как «ровно один раз». В основном это означает, что каждое сообщение, размещенное в теме Kafka, будет обработано Spark Streaming только один раз.
8. Развертывание приложения
Мы можем развернуть наше приложение с помощью скрипта Spark-submit, который поставляется вместе с установкой Spark:
$SPARK_HOME$\bin\spark-submit \
--class com.foreach.data.pipeline.WordCountingAppWithCheckpoint \
--master local[2]
\target\spark-streaming-app-0.0.1-SNAPSHOT-jar-with-dependencies.jar
Обратите внимание, что jar, который мы создаем с помощью Maven, должен содержать зависимости, которые не помечены как предоставленные в области видимости.
Как только мы отправим это приложение и опубликуем несколько сообщений в теме Kafka, которую мы создали ранее, мы должны увидеть совокупное количество слов, публикуемых в таблице Cassandra, которую мы создали ранее.
9. Заключение
Подводя итог, в этом руководстве мы узнали, как создать простой конвейер данных с помощью Kafka, Spark Streaming и Cassandra. Мы также узнали, как использовать контрольные точки в Spark Streaming для сохранения состояния между пакетами.
Как всегда, код примеров доступен на GitHub .