1. Обзор
В этой статье рассказывается о LMAX Disruptor и о том, как он помогает достичь параллелизма программного обеспечения с малой задержкой. Мы также увидим базовое использование библиотеки Disruptor.
2. Что такое разрушитель?
Disruptor — это библиотека Java с открытым исходным кодом, написанная LMAX. Это среда параллельного программирования для обработки большого количества транзакций с малой задержкой (и без сложностей параллельного кода). Оптимизация производительности достигается за счет дизайна программного обеспечения, использующего эффективность базового оборудования.
2.1. Механическая симпатия
Давайте начнем с основной концепции механической симпатии — это все о понимании того, как работает базовое оборудование, и о программировании таким образом, чтобы оно лучше всего работало с этим оборудованием.
Например, давайте посмотрим, как ЦП и организация памяти могут повлиять на производительность программного обеспечения. Процессор имеет несколько уровней кэша между ним и основной памятью. Когда ЦП выполняет операцию, он сначала ищет данные в L1, затем в L2, затем в L3 и, наконец, в основной памяти. Чем дальше, тем больше времени займет операция.
Если одна и та же операция выполняется над частью данных несколько раз (например, счетчик циклов), имеет смысл загрузить эти данные в место, очень близкое к центральному процессору.
Некоторые ориентировочные цифры стоимости кэш-промахов:
| Задержка между процессором и | Циклы процессора | Время |
| Основная память | Несколько | ~60-80 нс |
| Кэш L3 | ~40-45 циклов | ~15 нс |
| Кэш L2 | ~10 циклов | ~3 нс |
| Кэш L1 | ~3-4 цикла | ~1 нс |
| регистр | 1 цикл | Очень очень быстро |
2.2. Почему не очереди
Реализации очередей, как правило, имеют конкуренцию за запись в переменные начала, хвоста и размера. Очереди, как правило, всегда почти заполнены или почти пусты из-за различий в скорости между потребителями и производителями. Они очень редко работают в уравновешенном среднем положении, когда скорость производства и потребления уравновешены.
Чтобы справиться с конкуренцией за запись, очередь часто использует блокировки, которые могут вызвать переключение контекста на ядро. Когда это происходит, задействованный процессор, скорее всего, потеряет данные в своих кэшах.
Чтобы обеспечить наилучшее поведение кэширования, в проекте должно быть только одно ядро, выполняющее запись в любую ячейку памяти (несколько считывателей — это нормально, поскольку процессоры часто используют специальные высокоскоростные каналы между своими кэшами). Очереди не соответствуют принципу одного автора.
Если два отдельных потока записывают два разных значения, каждое ядро делает недействительной строку кеша другого (данные передаются между основной памятью и кешем блоками фиксированного размера, называемыми строками кеша). Это конфликт записи между двумя потоками, даже если они пишут в две разные переменные. Это называется ложным разделением, потому что каждый раз, когда осуществляется доступ к голове, также осуществляется доступ к хвосту, и наоборот.
2.3. Как работает разрушитель
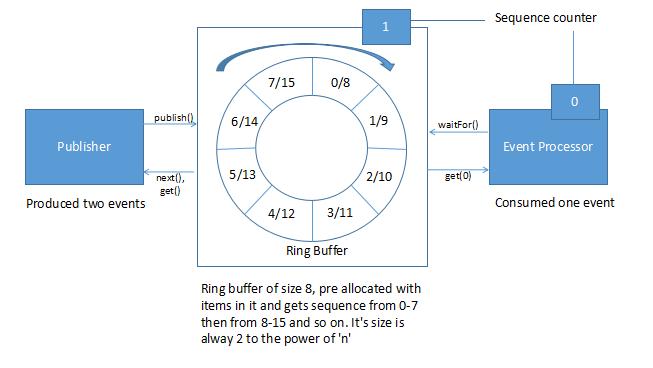
Disruptor имеет циклическую структуру данных на основе массива (кольцевой буфер). Это массив с указателем на следующий доступный слот. Он заполняется предварительно выделенными объектами передачи. Производители и потребители выполняют запись и чтение данных в кольцо без блокировки или конкуренции.
В Disruptor все события публикуются для всех потребителей (многоадресная рассылка) для параллельного потребления через отдельные нисходящие очереди. Из-за параллельной обработки потребителями необходимо согласовывать зависимости между потребителями (граф зависимостей).
Производители и потребители имеют счетчик последовательности, чтобы указать, с каким слотом в буфере он работает в данный момент. Каждый производитель/потребитель может записывать свой собственный счетчик последовательности, но может считывать счетчики последовательности других. Производители и потребители считывают счетчики, чтобы гарантировать, что слот, в который они хотят записать, доступен без каких-либо блокировок.
3. Использование библиотеки Disruptor
3.1. Зависимость от Maven
Начнем с добавления зависимости библиотеки Disruptor в pom.xml :
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.6</version>
</dependency>
Последнюю версию зависимости можно проверить здесь .
3.2. Определение события
Давайте определим событие, которое несет данные:
public static class ValueEvent {
private int value;
public final static EventFactory EVENT_FACTORY
= () -> new ValueEvent();
// standard getters and setters
}
EventFactory позволяет Disruptor предварительно распределять события .
3.3. Потребитель
Потребители читают данные из кольцевого буфера. Давайте определим потребителя, который будет обрабатывать события:
public class SingleEventPrintConsumer {
...
public EventHandler<ValueEvent>[] getEventHandler() {
EventHandler<ValueEvent> eventHandler
= (event, sequence, endOfBatch)
-> print(event.getValue(), sequence);
return new EventHandler[] { eventHandler };
}
private void print(int id, long sequenceId) {
logger.info("Id is " + id
+ " sequence id that was used is " + sequenceId);
}
}
В нашем примере потребитель просто печатает в журнал.
3.4. Создание Разрушителя
Соберите Разрушитель:
ThreadFactory threadFactory = DaemonThreadFactory.INSTANCE;
WaitStrategy waitStrategy = new BusySpinWaitStrategy();
Disruptor<ValueEvent> disruptor
= new Disruptor<>(
ValueEvent.EVENT_FACTORY,
16,
threadFactory,
ProducerType.SINGLE,
waitStrategy);
В конструкторе Disruptor определены:
- Фабрика событий — отвечает за создание объектов, которые будут храниться в кольцевом буфере во время инициализации.
- Размер кольцевого буфера. Мы определили 16 как размер кольцевого буфера. Это должна быть степень двойки, иначе при инициализации возникнет исключение. Это важно, потому что большинство операций легко выполнить с помощью логических бинарных операторов, например, операцию mod.
- Thread Factory — Фабрика для создания потоков для обработчиков событий.
- Тип производителя — указывает, будет ли у нас один или несколько производителей.
- Стратегия ожидания — определяет, как мы хотели бы обращаться с медленным подписчиком, который не поспевает за темпами производителя.
Подключить обработчик потребителя:
disruptor.handleEventsWith(getEventHandler());
Disruptor можно предоставить нескольким потребителям для обработки данных, созданных производителем. В приведенном выше примере у нас есть только один потребитель, также известный как обработчик событий.
3.5. Запуск Разрушителя
Чтобы запустить Разрушитель:
RingBuffer<ValueEvent> ringBuffer = disruptor.start();
3.6. Продюсирование и публикация событий
Производители помещают данные в кольцевой буфер в определенной последовательности. Производители должны знать о следующем доступном слоте, чтобы не перезаписывать данные, которые еще не используются.
Используйте RingBuffer от Disruptor для публикации:
for (int eventCount = 0; eventCount < 32; eventCount++) {
long sequenceId = ringBuffer.next();
ValueEvent valueEvent = ringBuffer.get(sequenceId);
valueEvent.setValue(eventCount);
ringBuffer.publish(sequenceId);
}
Здесь производитель производит и публикует элементы последовательно. Здесь важно отметить, что Disruptor работает аналогично протоколу двухфазной фиксации. Он считывает новый sequenceId и публикует. В следующий раз он должен получить sequenceId + 1 в качестве следующего sequenceId.
4. Вывод
В этом руководстве мы увидели, что такое Disruptor и как он обеспечивает параллелизм с малой задержкой. Мы рассмотрели концепцию механической симпатии и то, как ее можно использовать для достижения низкой задержки. Затем мы увидели пример использования библиотеки Disruptor.
Пример кода можно найти в проекте GitHub — это проект на основе Maven, поэтому его легко импортировать и запускать как есть.