1. Введение
В этом руководстве мы узнаем, что такое неблокирующие структуры данных и почему они являются важной альтернативой параллельным структурам данных на основе блокировок.
Во- первых, мы рассмотрим некоторые термины, такие как отсутствие препятствий , отсутствие блокировки и отсутствие ожидания .
Во-вторых, мы рассмотрим основные строительные блоки неблокирующих алгоритмов, таких как CAS (сравнение и замена).
В-третьих, мы рассмотрим реализацию очереди без блокировок в Java и, наконец, обрисуем подход к достижению свободы ожидания .
2. Блокировка против голодания
Во-первых, давайте посмотрим на разницу между заблокированным и голодающим потоком.
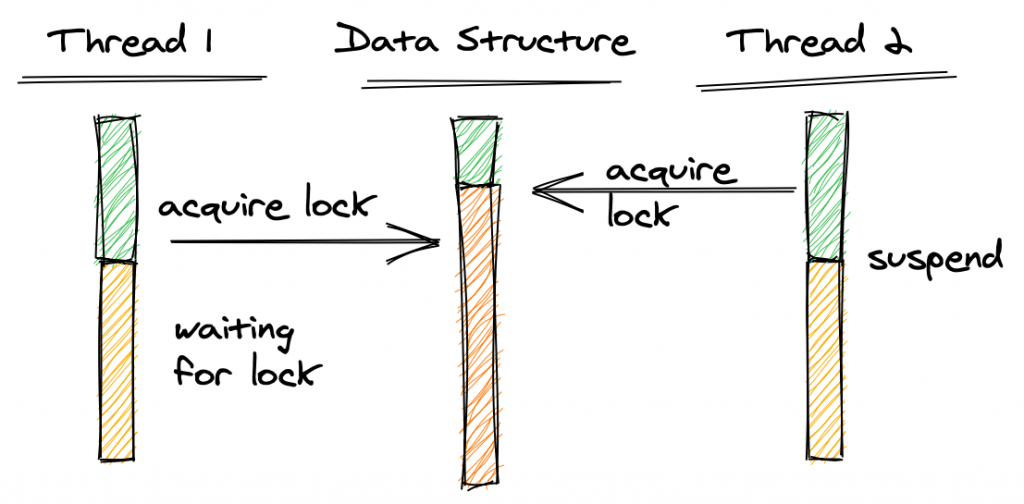
На приведенном выше рисунке поток 2 получает блокировку структуры данных. Когда поток 1 также пытается получить блокировку, ему нужно дождаться, пока поток 2 освободит блокировку; это не будет продолжаться, пока он не сможет получить блокировку. Если мы приостановим поток 2, пока он удерживает блокировку, потоку 1 придется ждать вечно.
Следующая картинка иллюстрирует голодание потока:
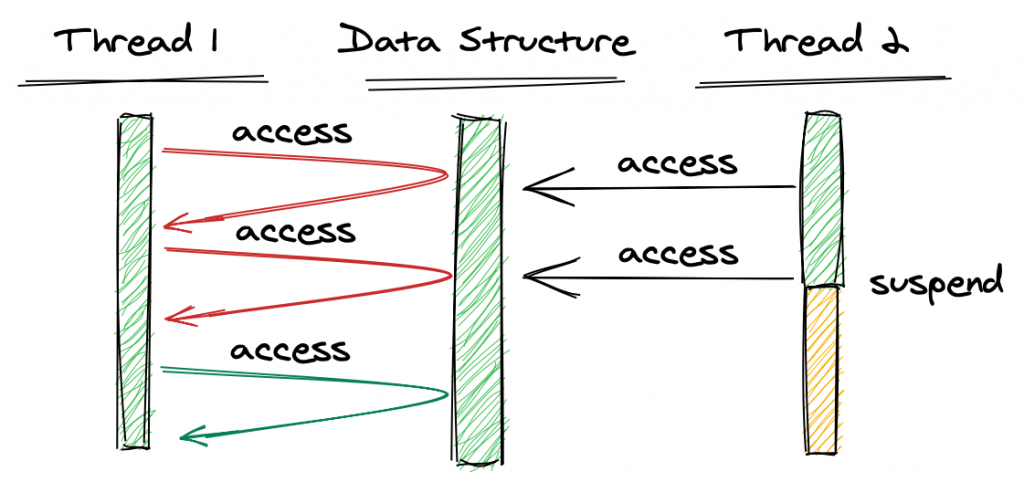
Здесь поток 2 обращается к структуре данных, но не получает блокировки. Поток 1 одновременно пытается получить доступ к структуре данных, обнаруживает одновременный доступ и немедленно возвращается, информируя поток о том, что он не может завершить операцию (красный). Затем поток 1 будет пытаться снова, пока ему не удастся завершить операцию (зеленый).
Преимущество этого подхода в том, что нам не нужна блокировка. Однако может случиться так, что если поток 2 (или другие потоки) будет обращаться к структуре данных с высокой частотой, то потоку 1 потребуется большое количество попыток, пока он, наконец, не добьется успеха. Мы называем это голоданием.
Позже мы увидим, как операция сравнения и замены обеспечивает неблокирующий доступ.
3. Типы неблокирующих структур данных
Мы можем различать три уровня неблокирующих структур данных.
3.1. Без препятствий
Свобода от препятствий — самая слабая форма неблокирующей структуры данных. Здесь мы требуем только, чтобы поток гарантированно продолжался, если все остальные потоки приостановлены .
Точнее, поток не будет продолжать голодать, если все остальные потоки будут приостановлены. Это отличается от использования блокировок в том смысле, что если поток ожидал блокировки, а поток, который удерживает блокировку, приостановлен, ожидающий поток будет ждать вечно.
3.2. Без блокировки
Структура данных обеспечивает свободу от блокировок, если в любой момент времени может продолжить работу хотя бы один поток . Все остальные потоки могут голодать. Разница со свободой от препятствий заключается в том, что существует по крайней мере один независящий поток, даже если ни один из потоков не приостановлен.
3.3. без ожидания
Структура данных не требует ожидания, если она свободна от блокировок и гарантируется, что каждый поток продолжит работу после конечного числа шагов, то есть потоки не будут голодать из-за «необоснованно большого» количества шагов.
3.4. Резюме
Обобщим эти определения в графическом представлении:
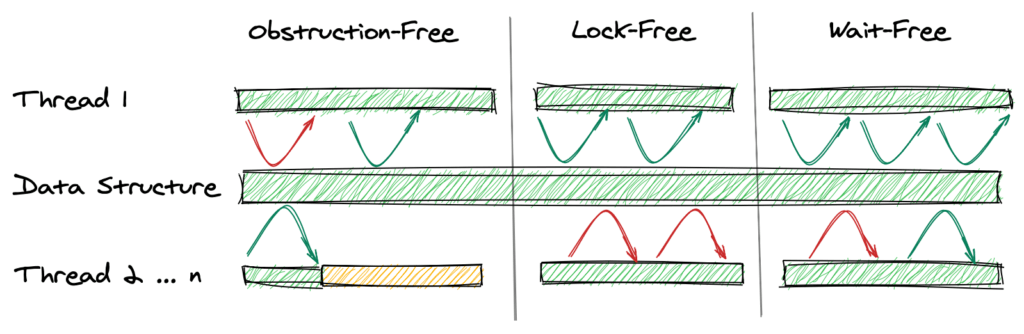
Первая часть изображения показывает отсутствие препятствий, поскольку поток 1 (верхний поток) может продолжаться (зеленая стрелка), как только мы приостанавливаем другие потоки (внизу желтым цветом).
Средняя часть показывает свободу блокировки. По крайней мере, поток 1 может развиваться, в то время как другие могут голодать (красная стрелка).
Последняя часть демонстрирует свободу ожидания. Здесь мы гарантируем, что поток 1 может продолжаться (зеленая стрелка) после определенного периода голодания (красные стрелки).
4. Неблокирующие примитивы
В этом разделе мы рассмотрим три основные операции, которые помогают нам создавать операции без блокировок со структурами данных.
4.1. Сравните и обменяйте
Одной из основных операций, используемых для предотвращения блокировки, является операция сравнения и замены (CAS) .
Идея сравнения и замены заключается в том, что переменная обновляется только в том случае, если она все еще имеет то же значение, что и в момент, когда мы извлекли значение переменной из основной памяти. CAS — это атомарная операция, что означает, что выборка и обновление вместе являются одной операцией :
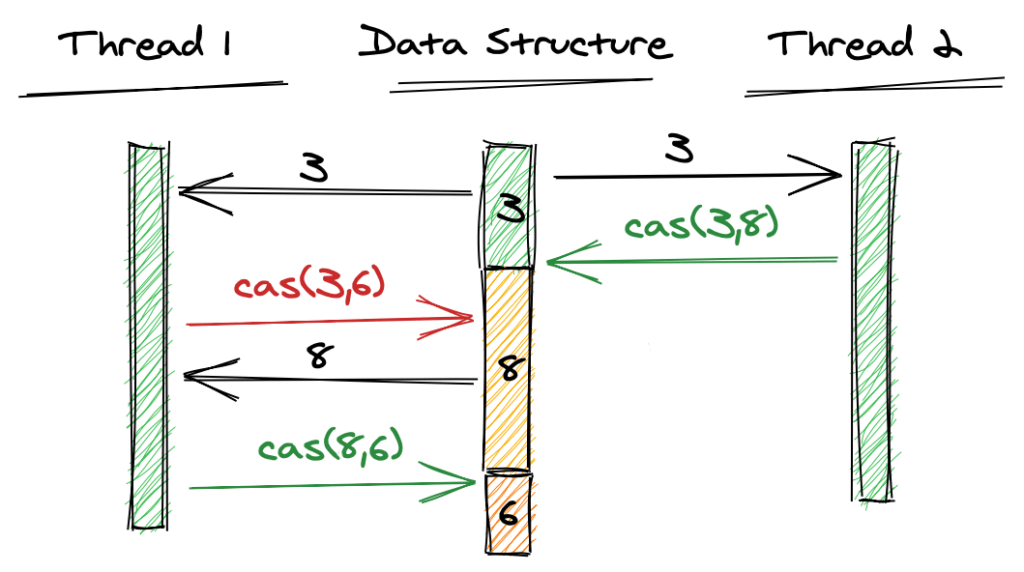
Здесь оба потока получают значение 3 из основной памяти. Поток 2 завершается успешно (зеленый) и обновляет переменную до 8. Поскольку первый CAS потока 1 ожидает, что значение будет равно 3, CAS терпит неудачу (красный). Таким образом, поток 1 снова получает значение, и второй CAS завершается успешно.
Здесь важно то, что CAS не блокирует структуру данных, а возвращает true , если обновление прошло успешно, иначе возвращает false .
В следующем фрагменте кода показано, как работает CAS:
volatile int value;
boolean cas(int expectedValue, int newValue) {
if(value == expectedValue) {
value = newValue;
return true;
}
return false;
}
Мы обновляем значение новым значением только в том случае, если оно все еще имеет ожидаемое значение, в противном случае оно возвращает false . В следующем фрагменте кода показано, как можно вызвать CAS:
void testCas() {
int v = value;
int x = v + 1;
while(!cas(v, x)) {
v = value;
x = v + 1;
}
}
Мы пытаемся обновить наше значение до тех пор, пока операция CAS не завершится успешно, то есть не вернет true .
Однако возможно, что поток застревает в режиме голодания . Это может произойти, если другие потоки одновременно выполняют CAS для одной и той же переменной, поэтому операция никогда не будет успешной для конкретного потока (или для ее успешного выполнения потребуется неоправданно много времени). Тем не менее, если сравнение и подкачка не удалась, мы знаем, что успешно завершился другой поток, таким образом, мы также обеспечиваем глобальный прогресс, как это требуется для свободы блокировки.
Важно отметить, что аппаратное обеспечение должно поддерживать compare-and-swap , чтобы сделать его действительно атомарной операцией без использования блокировки.
Java предоставляет реализацию сравнения и замены в классе sun.misc.Unsafe . Однако в большинстве случаев мы должны использовать не этот класс напрямую, а атомарные переменные .
Кроме того, сравнение и замена не устраняют проблему ABA. Мы рассмотрим это в следующем разделе.
4.2. Load-Link/Store-Conditional
Альтернативой сравнению и обмену является load-link/store-conditional . Давайте сначала вернемся к сравнению и обмену . Как мы видели ранее, CAS обновляет значение только в том случае, если значение в основной памяти остается тем значением, которое мы ожидаем.
Однако CAS также успешно работает, если значение изменилось, а тем временем вернулось к своему предыдущему значению.
Изображение ниже иллюстрирует эту ситуацию:
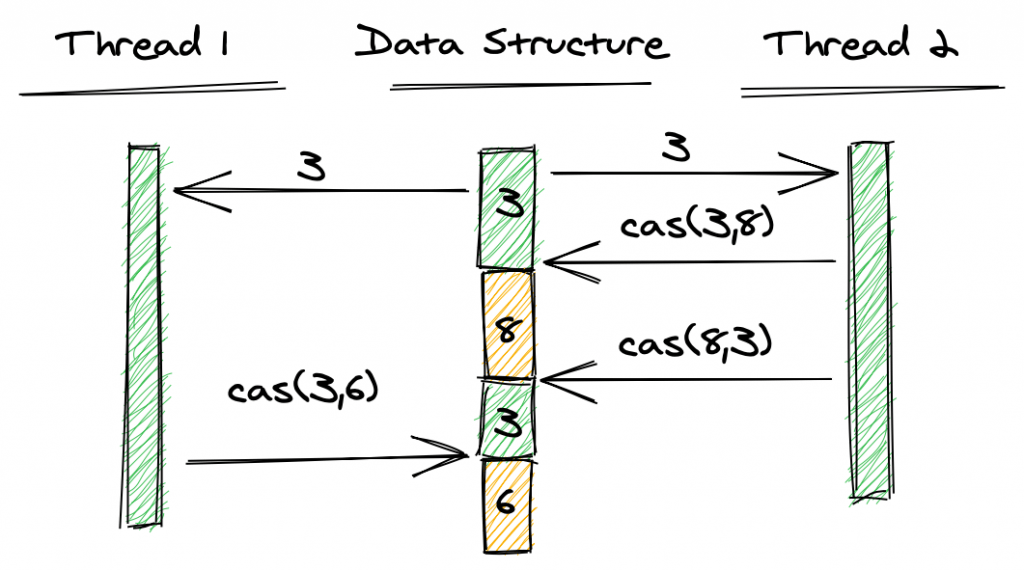
И поток 1, и поток 2 считывают значение переменной, равное 3. Затем поток 2 выполняет CAS, которому удается установить переменную на 8. Затем снова поток 2 выполняет CAS, чтобы установить переменную обратно на 3, что тоже удается. Наконец, поток 1 выполняет CAS, ожидая значение 3, и также преуспевает, несмотря на то, что значение нашей переменной было изменено дважды между ними.
Это называется проблемой АВА. Конечно, такое поведение может не быть проблемой в зависимости от варианта использования. Однако это может быть нежелательно для других. Java предоставляет реализацию load-link/store- conditional с классом AtomicStampedReference .
4.3. Получить и добавить
Другая альтернатива — выборка и добавление . Эта операция увеличивает переменную в основной памяти на заданное значение. Опять же, важным моментом является то, что операция происходит атомарно, что означает, что никакие другие потоки не могут вмешиваться .
Java предоставляет реализацию выборки и добавления в своих атомарных классах. Примеры: AtomicInteger.incrementAndGet() , который увеличивает значение и возвращает новое значение; и AtomicInteger.getAndIncrement() , который возвращает старое значение, а затем увеличивает значение.
5. Доступ к связанной очереди из нескольких потоков
Чтобы лучше понять проблему одновременного обращения двух (или более) потоков к очереди, давайте рассмотрим связанную очередь и два потока, пытающихся одновременно добавить элемент.
Очередь, которую мы рассмотрим, представляет собой двусвязную очередь FIFO, в которую мы добавляем новые элементы после последнего элемента (L), а переменная tail указывает на этот последний элемент:
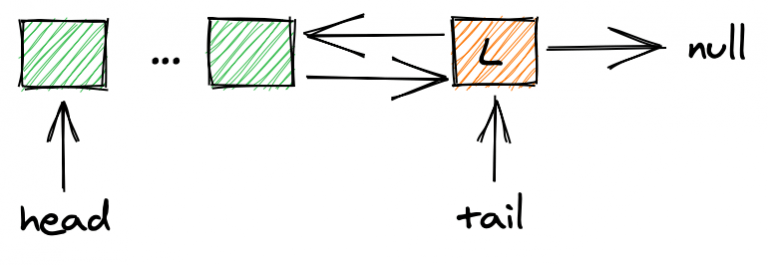
Чтобы добавить новый элемент, потоки должны выполнить три шага: 1) создать новые элементы (N и M), установив указатель на следующий элемент равным null ; 2) ссылка на предыдущий элемент указывает на L, а ссылка на следующий элемент L указывает на N (M соответственно). 3) Иметь точку хвоста на N (M соответственно):
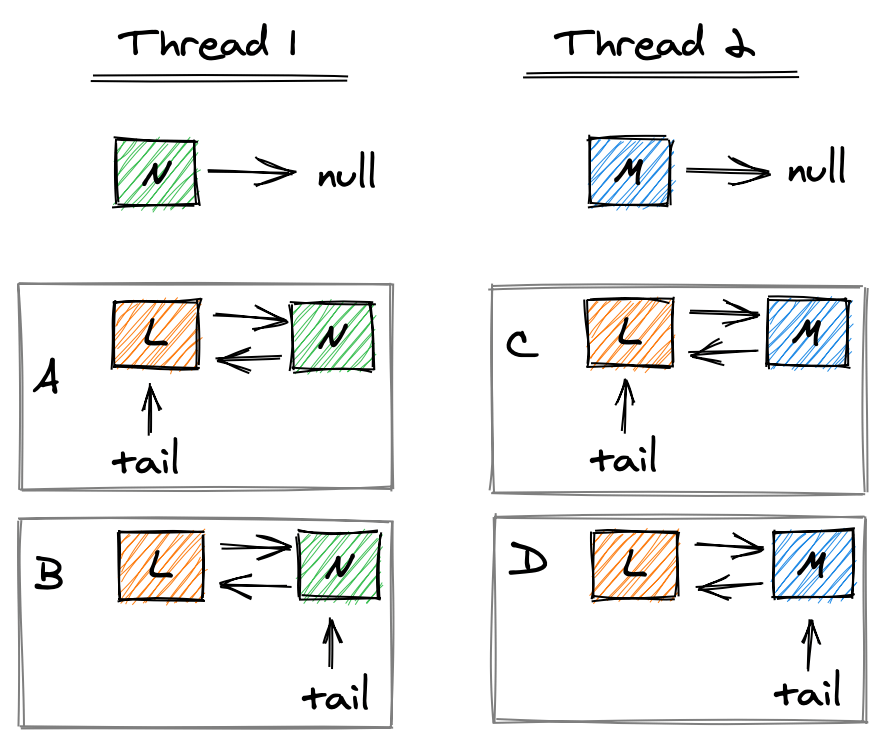
Что может пойти не так, если два потока выполняют эти шаги одновременно? Если шаги на картинке выше выполняются в порядке ABCD или ACBD, L, а также tail , будут указывать на M. N останется отключенным от очереди.
Если шаги выполняются в порядке ACDB, хвост будет указывать на N, а L — на M, что вызовет несогласованность в очереди:
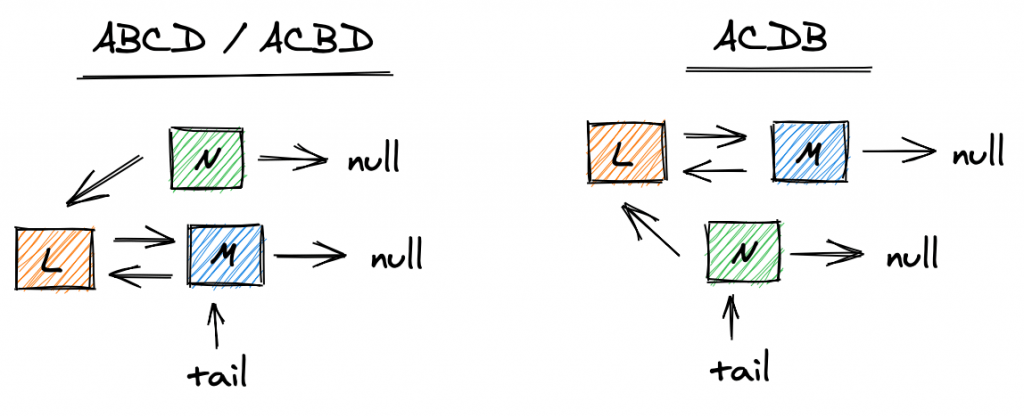
Конечно, одним из способов решения этой проблемы является блокировка очереди одним потоком. Решение, которое мы рассмотрим в следующей главе, решит проблему с помощью операции без блокировки с использованием операции CAS, которую мы видели ранее.
6. Неблокирующая очередь в Java
Давайте рассмотрим базовую незаблокированную очередь в Java. Во-первых, давайте посмотрим на члены класса и конструктор:
public class NonBlockingQueue<T> {
private final AtomicReference<Node<T>> head, tail;
private final AtomicInteger size;
public NonBlockingQueue() {
head = new AtomicReference<>(null);
tail = new AtomicReference<>(null);
size = new AtomicInteger();
size.set(0);
}
}
Важной частью является объявление головной и хвостовой ссылок как AtomicReference , что гарантирует, что любое обновление этих ссылок является атомарной операцией . Этот тип данных в Java реализует необходимую операцию сравнения и замены .
Далее давайте посмотрим на реализацию класса Node:
private class Node<T> {
private volatile T value;
private volatile Node<T> next;
private volatile Node<T> previous;
public Node(T value) {
this.value = value;
this.next = null;
}
// getters and setters
}
Здесь важно объявить ссылки на предыдущий и следующий узлы как volatile . Это гарантирует, что мы всегда обновляем эти ссылки в основной памяти (таким образом, они видны всем потокам). То же самое для фактического значения узла.
6.1. Добавить без блокировки ``
Наша операция добавления без блокировки гарантирует, что мы добавим новый элемент в конец и не будем отключены от очереди, даже если несколько потоков захотят добавить новый элемент одновременно:
public void add(T element) {
if (element == null) {
throw new NullPointerException();
}
Node<T> node = new Node<>(element);
Node<T> currentTail;
do {
currentTail = tail.get();
node.setPrevious(currentTail);
} while(!tail.compareAndSet(currentTail, node));
if(node.previous != null) {
node.previous.next = node;
}
head.compareAndSet(null, node); // for inserting the first element
size.incrementAndGet();
}
Важной частью, на которую следует обратить внимание, является выделенная строка. Мы пытаемся добавить новый узел в очередь до тех пор, пока операции CAS не удастся обновить хвост, который все еще должен быть тем же хвостом, к которому мы добавили новый узел.
6.2. Получите без блокировки ``
Подобно операции добавления, операция get без блокировки гарантирует, что мы вернем последний элемент и переместим хвост в текущую позицию:
public T get() {
if(head.get() == null) {
throw new NoSuchElementException();
}
Node<T> currentHead;
Node<T> nextNode;
do {
currentHead = head.get();
nextNode = currentHead.getNext();
} while(!head.compareAndSet(currentHead, nextNode));
size.decrementAndGet();
return currentHead.getValue();
}
Опять же, важная часть, на которую следует обратить внимание, — это выделенная строка. Операция CAS гарантирует, что мы перемещаем текущую головку только в том случае, если за это время не был удален никакой другой узел.
Java уже предоставляет реализацию неблокирующей очереди ConcurrentLinkedQueue . Это реализация очереди без блокировки от М. Майкла и Л. Скотта, описанная в этой статье . Интересным примечанием здесь является то, что в документации по Java говорится, что это очередь без ожидания, хотя на самом деле она не блокируется . Документация по Java 8 правильно называет реализацию lock-free .
7. Очереди без ожидания
Как мы видели, приведенная выше реализация не требует блокировки , но не ожидания . Циклы while в методах add и get потенциально могут зацикливаться на долгое время (или, что маловероятно, навсегда), если к нашей очереди обращается много потоков.
Как мы можем достичь свободы ожидания? Реализация алгоритмов без ожидания, в общем, довольно сложна. Мы отсылаем заинтересованного читателя к этой статье , в которой подробно описывается очередь без ожидания. В этой статье давайте рассмотрим основную идею того, как мы можем подойти к реализации очереди без ожидания .
Очередь без ожидания требует, чтобы каждый поток выполнял гарантированный прогресс (после конечного числа шагов). Другими словами, циклы while в наших методах add и get должны завершиться успешно после определенного количества шагов.
Для этого мы назначаем вспомогательный поток каждому потоку. Если этому вспомогательному потоку удастся добавить элемент в очередь, он поможет другому потоку вставить свой элемент перед вставкой другого элемента.
Поскольку у вспомогательного потока есть помощник, а во всем списке потоков у каждого потока есть помощник, мы можем гарантировать, что поток завершает вставку после того, как каждый поток выполнил одну вставку. Следующий рисунок иллюстрирует эту идею:
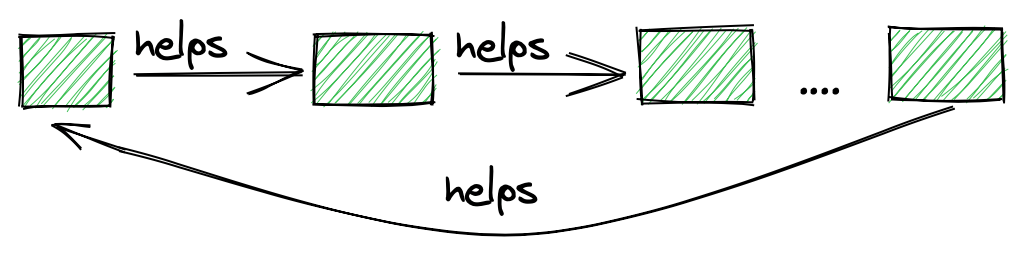
Конечно, все становится сложнее, когда мы можем динамически добавлять или удалять потоки.
8. Заключение
В этой статье мы рассмотрели основы неблокирующих структур данных. Мы объяснили различные уровни и основные операции, такие как сравнение и замена .
Затем мы рассмотрели базовую реализацию незаблокированной очереди в Java. Наконец, мы изложили идею того, как добиться свободы ожидания .
Полный исходный код всех примеров в этой статье доступен на GitHub.