1. Обзор
В этой статье мы собираемся продемонстрировать использование конвейеров на примере непрерывной доставки с использованием Jenkins .
Мы собираемся создать простой, но довольно полезный конвейер для нашего примера проекта:
- Сборник
- Простой статический анализ (параллельно с компиляцией)
- Модульные тесты
- Интеграционные тесты (параллельно с модульными тестами)
- Развертывание
2. Настройка Дженкинса
Прежде всего, нам нужно скачать последнюю стабильную версию Jenkins (2.73.3 на момент написания этой статьи).
Давайте перейдем в папку, где находится наш файл, и запустим его с помощью команды java -jar jenkins.war . Имейте в виду, что мы не можем использовать Jenkins без начальной настройки пользователей.
После разблокировки Jenkins с использованием исходного пароля, сгенерированного администратором, мы должны заполнить информацию о профиле первого пользователя-администратора и обязательно установить все рекомендуемые плагины.
Теперь у нас есть новая установка Jenkins, готовая к использованию.
Все доступные версии Jenkins можно найти здесь .
3. Трубопроводы
Jenkins 2 поставляется с отличной функцией под названием Pipelines , которая очень расширяема, когда нам нужно определить среду непрерывной интеграции для проекта.
Конвейер — это еще один способ определения некоторых шагов Jenkins с помощью кода и автоматизации процесса развертывания программного обеспечения.
Он использует предметно-ориентированный язык (DSL) с двумя разными синтаксисами:
- Декларативный конвейер
- Сценарий конвейера
В наших примерах мы будем использовать Scripted Pipeline , который следует более императивной модели программирования, созданной с помощью Groovy .
Давайте рассмотрим некоторые характеристики плагина Pipeline :
- конвейеры записываются в текстовый файл и обрабатываются как код; это означает, что их можно добавить в систему управления версиями и изменить позже.
- они останутся после рестартов сервера Jenkins
- мы можем опционально приостановить конвейеры
- они поддерживают сложные требования, такие как параллельное выполнение работы
- Плагин Pipeline также может быть расширен или интегрирован с другими плагинами.
Другими словами, настройка проекта Pipeline означает написание сценария, который будет последовательно применять некоторые шаги процесса, который мы хотим выполнить.
Чтобы начать использовать конвейеры, нам нужно установить плагин Pipeline , который позволяет создавать простые и сложные автоматизации.
При желании мы также можем иметь представление этапа конвейера , чтобы при запуске сборки мы видели все этапы, которые мы настроили.
4. Краткий пример
В нашем примере мы будем использовать небольшое приложение Spring Boot. Затем мы создадим конвейер, который клонирует проект, создает его и запускает несколько тестов, а затем запускает приложение.
Давайте установим плагины Checkstyle , Static Analysis Collector и JUnit , которые соответственно полезны для сбора результатов Checkstyle , построения комбинированного графа анализа тестовых отчетов и иллюстрации успешно выполненных и неудачных тестов.
Во-первых, давайте разберемся, зачем нужен Checkstyle: это инструмент разработки, который помогает программистам писать лучший Java-код в соответствии с общепринятыми и хорошо известными стандартами.
Сборщик статического анализа — это надстройка, которая собирает различные результаты анализа и распечатывает результаты в виде комбинированного графика тенденций. Кроме того, подключаемый модуль предоставляет отчеты о работоспособности и обеспечивает стабильность сборки на основе этих сгруппированных результатов.
Наконец, подключаемый модуль JUnit предоставляет средство публикации, которое использует XML-отчеты о тестировании, созданные во время сборки, и выводит подробную и содержательную информацию, касающуюся тестов проекта.
Мы также настроим Checkstyle в pom.xml нашего приложения :
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>2.17</version>
</plugin>
5. Создание сценария конвейера
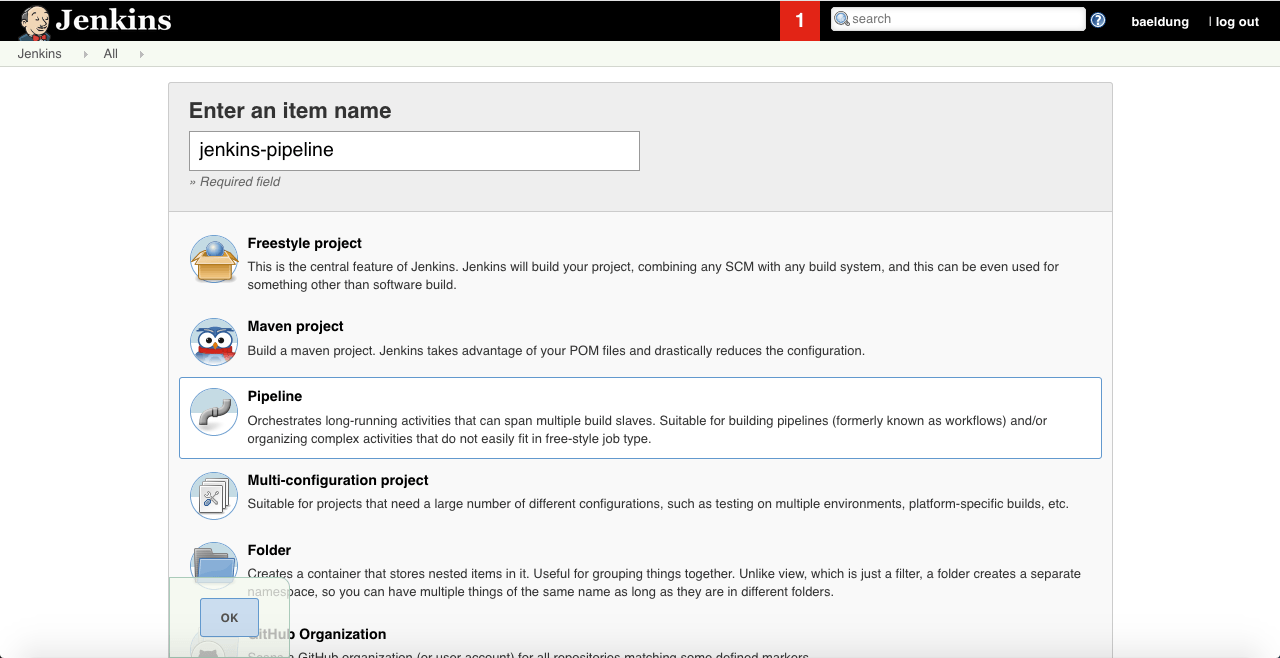
Во-первых, нам нужно создать новую работу Дженкинса. Давайте обязательно выберем Pipeline в качестве типа, прежде чем нажимать кнопку OK, как показано на этом снимке экрана:
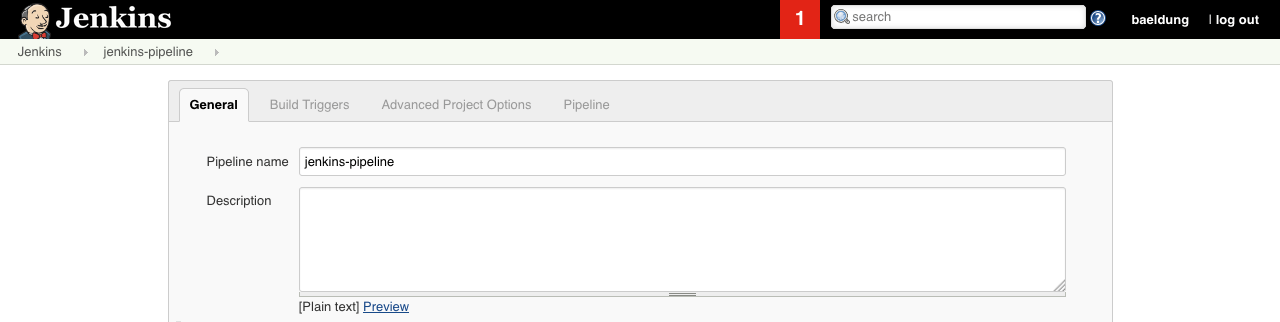
Следующий экран позволяет нам заполнить более подробную информацию о различных этапах нашей работы Jenkins, например, описание , триггеры , некоторые дополнительные параметры проекта:
Давайте погрузимся в основную и самую важную часть такого рода работы, щелкнув вкладку Pipeline .
Затем для определения выберите сценарий конвейера и установите флажок « Использовать песочницу Groovy».
Вот рабочий скрипт для среды Unix:
node {
stage 'Clone the project'
git 'https://github.com/foreach/tutorials.git'
dir('spring-jenkins-pipeline') {
stage("Compilation and Analysis") {
parallel 'Compilation': {
sh "./mvnw clean install -DskipTests"
}, 'Static Analysis': {
stage("Checkstyle") {
sh "./mvnw checkstyle:checkstyle"
step([$class: 'CheckStylePublisher',
canRunOnFailed: true,
defaultEncoding: '',
healthy: '100',
pattern: '**/target/checkstyle-result.xml',
unHealthy: '90',
useStableBuildAsReference: true
])
}
}
}
stage("Tests and Deployment") {
parallel 'Unit tests': {
stage("Runing unit tests") {
try {
sh "./mvnw test -Punit"
} catch(err) {
step([$class: 'JUnitResultArchiver', testResults:
'**/target/surefire-reports/TEST-*UnitTest.xml'])
throw err
}
step([$class: 'JUnitResultArchiver', testResults:
'**/target/surefire-reports/TEST-*UnitTest.xml'])
}
}, 'Integration tests': {
stage("Runing integration tests") {
try {
sh "./mvnw test -Pintegration"
} catch(err) {
step([$class: 'JUnitResultArchiver', testResults:
'**/target/surefire-reports/TEST-'
+ '*IntegrationTest.xml'])
throw err
}
step([$class: 'JUnitResultArchiver', testResults:
'**/target/surefire-reports/TEST-'
+ '*IntegrationTest.xml'])
}
}
stage("Staging") {
sh "pid=\$(lsof -i:8989 -t); kill -TERM \$pid "
+ "|| kill -KILL \$pid"
withEnv(['JENKINS_NODE_COOKIE=dontkill']) {
sh 'nohup ./mvnw spring-boot:run -Dserver.port=8989 &'
}
}
}
}
}
Сначала клонируем репозиторий с GitHub, затем меняем директорию на наш проект, который называется spring-jenkins-pipeline.
Далее компилируем проект и параллельно применяем анализ Checkstyle .
Следующий шаг представляет собой параллельное выполнение модульных и интеграционных тестов, а затем развертывание приложения.
Параллелизм используется для оптимизации конвейера и ускорения выполнения задания. В Jenkins рекомендуется одновременно выполнять несколько независимых действий, которые могут занять много времени.
Например, в реальном проекте у нас обычно есть много модульных и интеграционных тестов, которые могут занять больше времени.
Обратите внимание, что если какой-либо тест завершился неудачно, BUILD также будет помечен как FAILED, и развертывание не произойдет.
Кроме того, мы используем JENKINS_NODE_COOKIE , чтобы предотвратить немедленное закрытие нашего приложения, когда конвейер достигает конца.
Чтобы увидеть более общий скрипт, работающий на других разных системах, загляните в репозиторий GitHub .
6. Аналитический отчет
После создания задания мы сохраним наш сценарий и нажмем « Создать сейчас » в домашней странице проекта на панели инструментов Jenkins.
Вот обзор сборок:
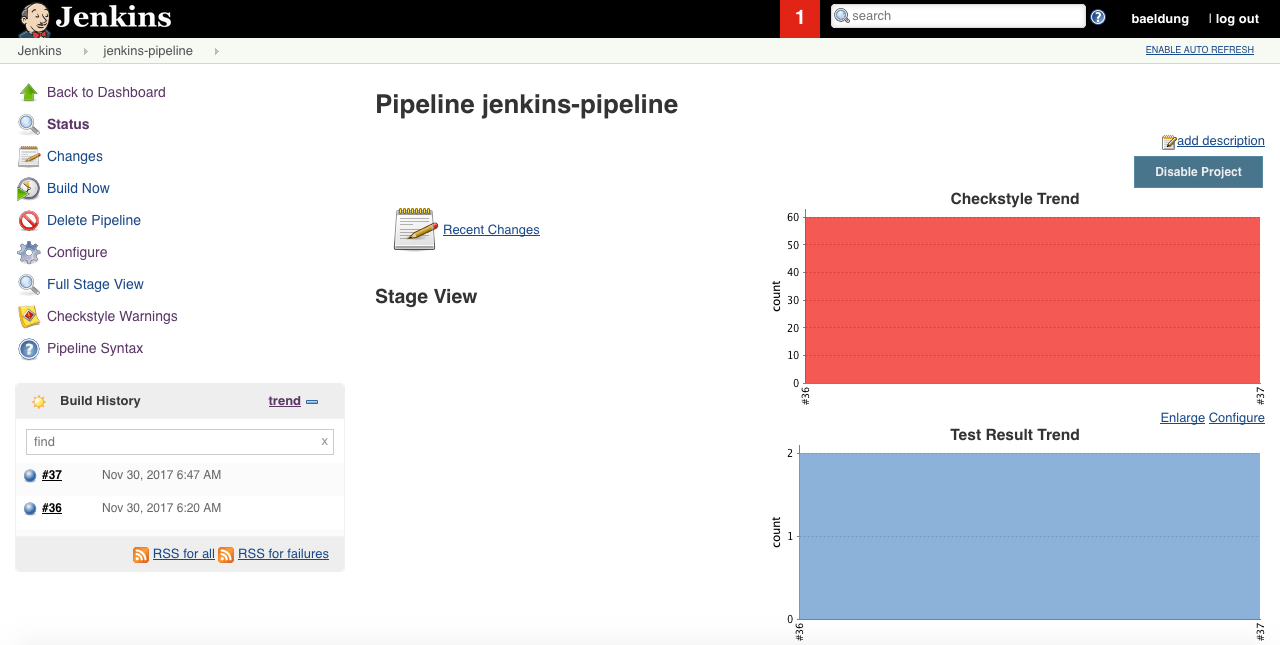
Чуть ниже мы найдем представление этапа конвейера с результатом каждого этапа:
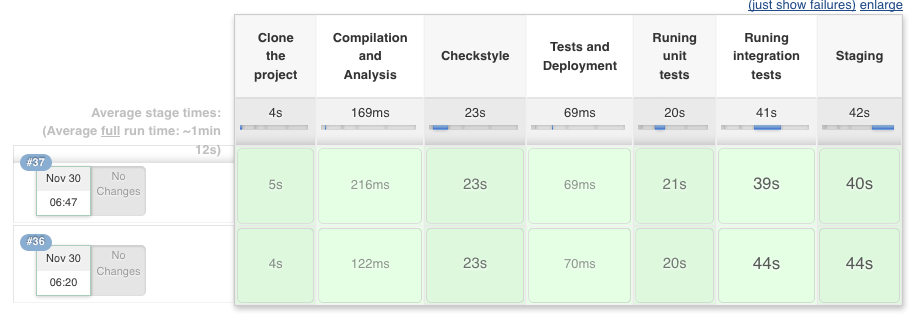
Каждый вывод доступен при наведении указателя мыши на ячейку этапа и нажатии кнопки « Журналы» , чтобы просмотреть сообщения журнала, напечатанные на этом шаге.
Мы также можем найти более подробную информацию об анализе кода. Щелкнем по нужной сборке в истории сборок в правом меню и нажмем Checkstyle Warnings.
Здесь мы видим 60 предупреждений с высоким приоритетом, которые можно просмотреть, нажав:
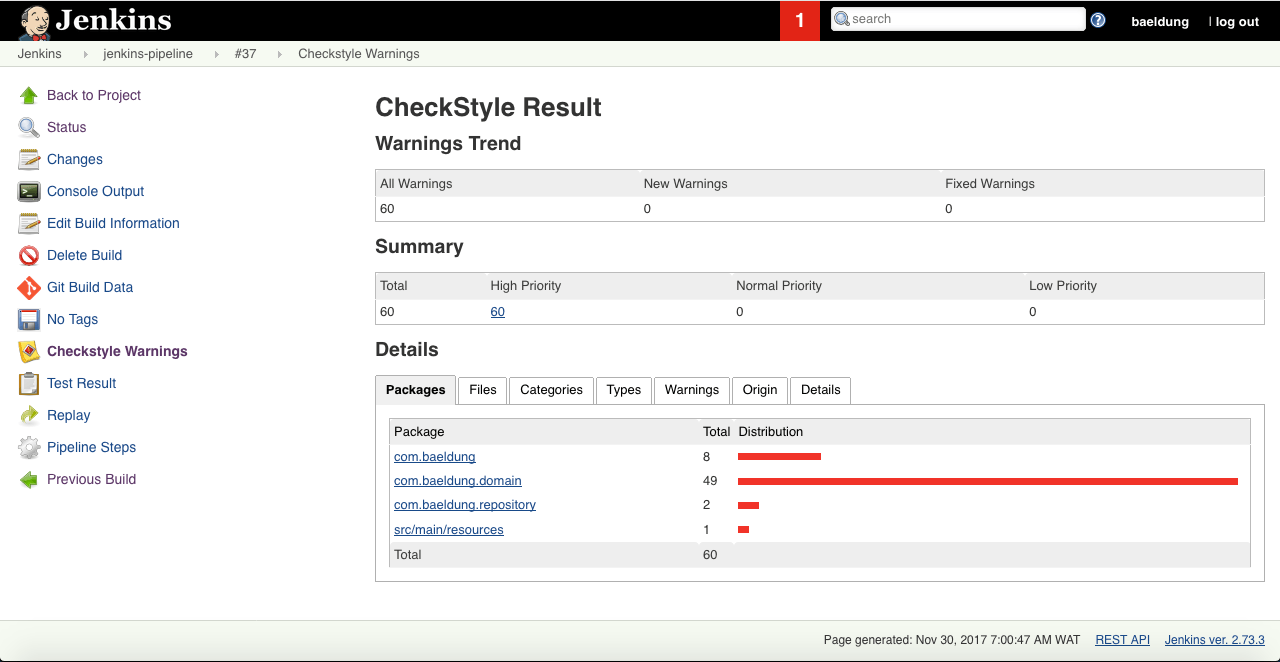
На вкладке « Подробности » отображаются фрагменты информации, которые выделяют предупреждения и позволяют разработчику понять их причины.
Точно так же полный отчет о тестировании доступен по ссылке Test Result . Давайте посмотрим на результаты пакета com.foreach :
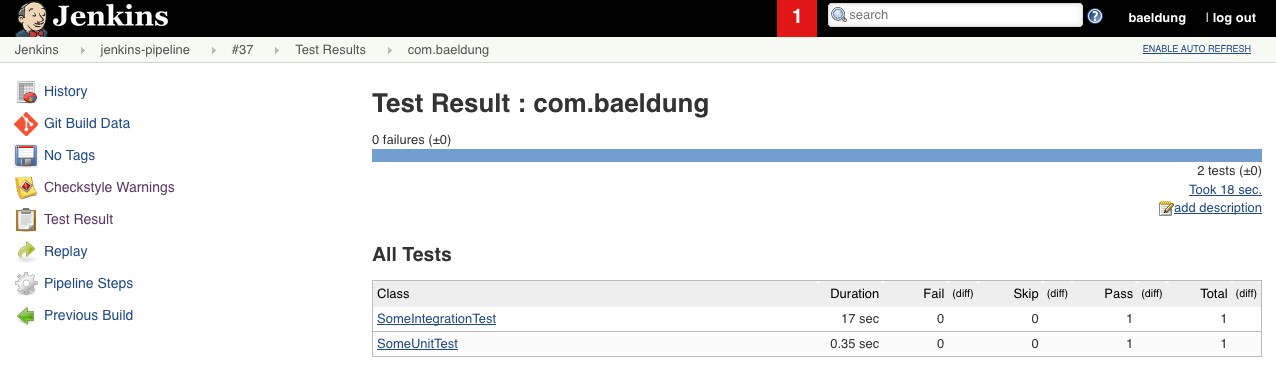
Здесь мы можем видеть каждый тестовый файл с его продолжительностью и статусом.
7. Заключение
В этой статье мы настроим простую среду непрерывной доставки для запуска и отображения статического анализа кода и отчета о тестировании в Jenkins через задание Pipeline .
Как всегда, исходный код этой статьи можно найти на GitHub .