1. Введение
В этом руководстве мы рассмотрим, как развернуть бессерверную рабочую нагрузку на платформе Kubernetes. Мы будем использовать Knative в качестве основы для выполнения этой задачи. В процессе мы также узнаем о преимуществах использования Knative в качестве фреймворка для наших бессерверных приложений .
2. Кубернетес и Кнатив
Разработка бессерверного приложения без вспомогательных инструментов — это не весело! Помните, как сочетание Docker и Kubernetes изменило управление облачными приложениями, созданными с помощью архитектуры микросервисов. Конечно, мы можем извлечь выгоду из фреймворков и инструментов и в бессерверном пространстве. Что ж, нет никаких причин, по которым Kubernetes не может нам здесь помочь.
2.1. Kubernetes для бессерверных решений
Kubernetes , получивший диплом CNCF, стал одним из лидеров в области организации контейнерных рабочих нагрузок . Это позволяет нам автоматизировать развертывание, масштабирование и управление приложениями, упакованными в образы OCI , с помощью популярных инструментов, таких как Docker или Buildah :
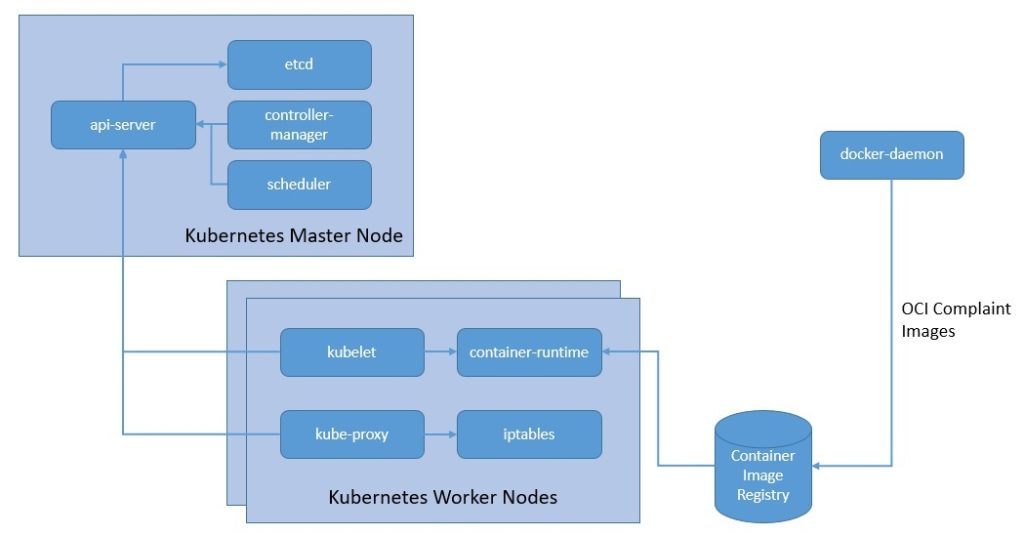
К очевидным преимуществам относится оптимальное использование ресурсов. Но разве это не та же самая цель, которую мы преследовали и с бессерверными технологиями?
Ну, конечно, есть много совпадений с точки зрения того, чего мы намерены достичь с помощью службы оркестрации контейнеров и бессерверной службы. Но, несмотря на то, что Kubernetes предоставляет нам замечательный инструмент для автоматизации многих вещей, мы по-прежнему несем ответственность за его настройку и управление . Serverless стремится избавиться даже от этого.
Но мы, безусловно, можем использовать платформу Kubernetes для запуска бессерверной среды. В этом есть ряд преимуществ. Во-первых, это помогает нам уйти от конкретных SDK и API-интерфейсов, привязывающих нас к конкретному поставщику облачных услуг. Базовая платформа Kubernetes помогает нам относительно легко переносить наше бессерверное приложение от одного поставщика облачных услуг к другому.
Кроме того, мы получаем выгоду от стандартной бессерверной среды для создания наших приложений . Помните о преимуществах Ruby on Rails и опоздания, Spring Boot! Один из первых таких фреймворков вышел из AWS и прославился как бессерверный . Это веб-фреймворк с открытым исходным кодом, написанный на Node.js, который может помочь нам развернуть наше бессерверное приложение у нескольких поставщиков услуг FaaS.
2.2. Введение в Кнатив
Knative — это, по сути , проект с открытым исходным кодом, который добавляет компоненты для развертывания, запуска и управления бессерверными приложениями в Kubernetes . Мы можем упаковать наши сервисы или функции в образ контейнера и передать его Knative. Затем Knative запускает контейнер для конкретной службы только тогда, когда это необходимо.
Базовая архитектура Knative состоит из двух широких компонентов: Serving и Eventing, которые работают в базовой инфраструктуре Kubernetes.
Knative Serving позволяет нам развертывать контейнеры, которые могут автоматически масштабироваться по мере необходимости. Он построен на основе Kubernetes и Istio путем развертывания набора объектов в виде пользовательских определений ресурсов (CRD):
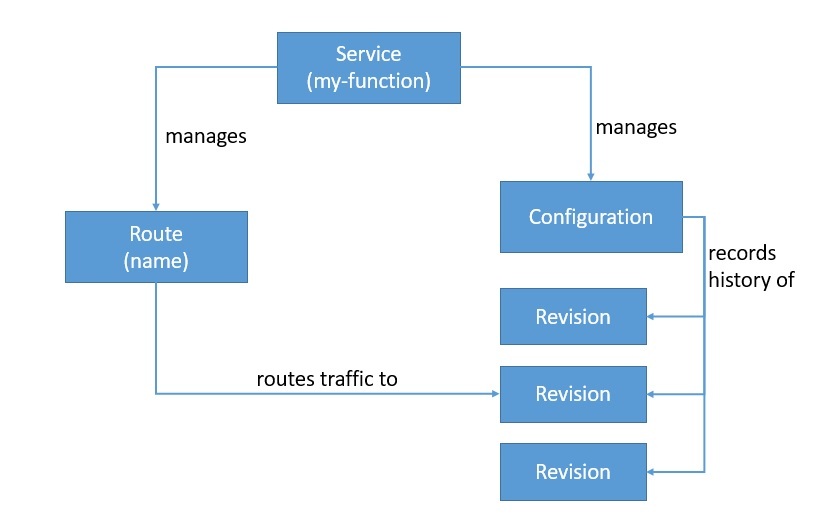
Knative Serving в основном состоит из четырех таких объектов: Service, Route, Configuration и Revision . Объект Service управляет всем жизненным циклом нашей рабочей нагрузки и автоматически создает другие объекты, такие как Route и Configuration. Каждый раз, когда мы обновляем Сервис, создается новая Редакция. Мы можем определить службу для маршрутизации трафика к последней или любой другой версии.
Knative Eventing предоставляет инфраструктуру для получения и создания событий для приложения. Это помогает сочетать управляемую событиями архитектуру с бессерверным приложением:
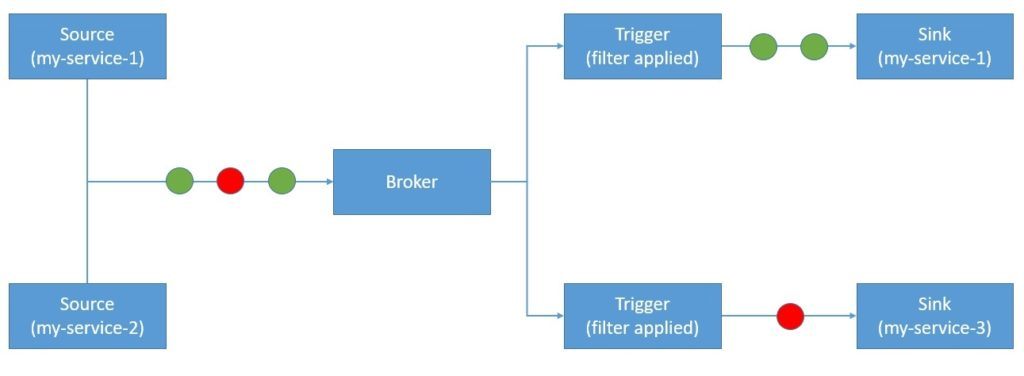
Knative Eventing работает с пользовательскими ресурсами, такими как Source, Broker, Trigger и Sink . Затем мы можем фильтровать и пересылать события подписчику с помощью Trigger. Служба — это компонент, который отправляет события Брокеру. Брокер здесь действует как центр событий. Мы можем фильтровать эти события на основе любого атрибута с помощью триггера и направлять их к приемнику.
Knative Eventing использует запросы HTTP POST для отправки и получения событий, соответствующих CloudEvents . CloudEvents — это, по сути, спецификация для описания данных событий стандартным способом. Цель состоит в том, чтобы упростить объявление событий и их доставку между службами и платформами. Это проект рабочей группы CNCF Serverless.
3. Установка и настройка
Как мы видели ранее, Knative в основном представляет собой набор компонентов, таких как Serving и Eventing, которые работают на сервисной сетке, такой как Istio, и кластере оркестровки рабочих нагрузок, таком как Kubernetes. Кроме того, есть утилиты командной строки, которые мы должны установить для простоты работы. Следовательно, есть несколько зависимостей, которые нам нужно проверить, прежде чем мы сможем продолжить установку Knative.
3.1. Установка необходимых компонентов
Существует несколько вариантов установки Kubernetes, и в этом руководстве мы не будем вдаваться в подробности. Например, Docker Desktop позволяет включить очень простой кластер Kubernetes, который выполняет большинство задач. Однако один из простых подходов — использовать Kubernetes в Docker (вид) для запуска локального кластера Kubernetes с узлами-контейнерами Docker.
На машинах под управлением Windows самый простой способ установить kind — использовать пакет Chocolatey :
choco install kind
Один из удобных способов работы с кластером Kubernetes — использование инструмента командной строки kubectl . Опять же, мы можем установить kubectl с помощью пакета Chocolaty :
choco install kubernetes-cli
Наконец, Knative также поставляется с инструментом командной строки под названием kn . Knative CLI предоставляет быстрый и простой интерфейс для создания ресурсов Knative. Это также помогает в сложных задачах, таких как автомасштабирование и разделение трафика.
Самый простой способ установить Knative CLI на компьютер с Windows — загрузить совместимый двоичный файл с официальной страницы выпуска . Затем мы можем просто начать использовать двоичный файл из командной строки.
3.2. Установка Кнатива
После того, как у нас есть все необходимые условия, мы можем приступить к установке компонентов Knative. Ранее мы уже видели, что компоненты Knative — это не что иное, как набор CRD, которые мы развертываем в базовом кластере Kubernetes . Это может быть немного сложно сделать индивидуально, даже с помощью утилиты командной строки.
К счастью, для среды разработки у нас есть плагин быстрого запуска. Этот плагин может установить локальный кластер Knative на Kind с помощью клиента Knative. Как и прежде, самый простой способ установить этот плагин для быстрого запуска на компьютере с Windows — загрузить двоичный файл с их официальной страницы выпуска .
Плагин быстрого запуска делает несколько вещей, чтобы мы были готовы к работе ! Во-первых, это гарантирует, что мы установили Kind. Затем он создает кластер с именем knative . Кроме того, он устанавливает Knative Serving с Kourier в качестве сетевого уровня по умолчанию и nio.io в качестве DNS. Наконец, он устанавливает Knative Eventing и создает в памяти реализацию брокера и канала.
Наконец, чтобы убедиться, что подключаемый модуль быстрого запуска был установлен правильно, мы можем запросить кластеры Kind и убедиться, что у нас есть кластер с именем knative .
4. Практика с Knative
Теперь мы прошли достаточно теории, чтобы попробовать некоторые функции, предоставляемые Knative, на практике. Для начала нам нужна контейнерная рабочая нагрузка. Создание простого приложения Spring Boot на Java и его контейнеризация с использованием Docker стали довольно тривиальными задачами. Мы не будем вдаваться в подробности этого.
Интересно, что Knative не ограничивает нас в том, как мы разрабатываем наше приложение. Итак, мы можем использовать любой из наших любимых веб-фреймворков, как и раньше. Более того, мы можем развернуть на Knative различные типы рабочей нагрузки, от полноразмерного приложения до небольшой функции. Конечно, преимущество безсерверных вычислений заключается в создании небольших автономных функций.
После того, как наша рабочая нагрузка будет контейнеризирована, мы можем в первую очередь использовать два подхода для ее развертывания в Knative. Поскольку вся рабочая нагрузка в конечном итоге развертывается как ресурс Kubernetes, мы можем просто создать файл YAML с определением ресурса и использовать kubectl для развертывания этого ресурса. В качестве альтернативы мы можем использовать Knative CLI для развертывания нашей рабочей нагрузки, не вдаваясь в эти подробности.
4.1. Развертывание с Knative Serving
Во- первых, мы начнем с Knative Serving . Мы поймем, как развернуть нашу рабочую нагрузку в бессерверной среде, предоставляемой Knative Serving. Как мы видели ранее, Service — это объект Knative Serving, отвечающий за управление всем жизненным циклом нашего приложения . Следовательно, мы начнем с описания этого объекта как файла YAML для нашего приложения:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: my-service
spec:
template:
metadata:
name: my-service-v1
spec:
containers:
- image: <location_of_container_image_in_a_registry>
ports:
- containerPort: 8080
Это довольно простое определение ресурса, в котором упоминается расположение образа контейнера нашего приложения, доступного в доступном реестре. Единственное, что здесь важно отметить, это значение, которое мы указали для spec.template.metadata.name . Это в основном используется для названия ревизии, которое может пригодиться для ее идентификации позже .
Развернуть этот ресурс довольно просто с помощью интерфейса командной строки Kubernetes. Мы можем использовать следующую команду, предполагая, что мы назвали наш файл YAML как my-service.yaml :
kubectl apply -f my-service.yaml
Когда мы развертываем этот ресурс, Knative выполняет ряд действий от нашего имени для управления нашим приложением . Для начала он создает новую неизменяемую ревизию для этой версии приложения. Затем он выполняет сетевое программирование для создания маршрута, входа, службы и балансировщика нагрузки для приложения. Наконец, он масштабирует модули приложений вверх и вниз в соответствии с требованиями.
Если создание файла YAML кажется немного неуклюжим, мы также можем использовать Knative CLI для достижения того же результата:
kn service create hello \
--image <location_of_container_image_in_a_registry> \
--port 8080 \
--revision-name=my-service-v1
Это гораздо более простой подход, в результате которого для нашего приложения развертывается тот же ресурс. Более того, Knative предпринимает те же необходимые шаги, чтобы сделать наше приложение доступным в соответствии со спросом.
4.2. Разделение трафика с помощью Knative Serving
Автоматическое масштабирование бессерверной рабочей нагрузки вверх и вниз — не единственное преимущество использования Kantive Serving. Он поставляется с множеством других мощных функций, которые еще больше упрощают управление бессерверными приложениями . Невозможно полностью осветить это в рамках ограниченного объема этого руководства. Однако одной из таких функций является разделение трафика, на котором мы сосредоточимся в этом разделе.
Если вспомнить понятие Revision в Knative Serving, то стоит отметить, что по умолчанию Knative направляет весь трафик на последнюю Revision. Но поскольку у нас по-прежнему доступны все предыдущие версии, вполне возможно направить часть или весь трафик на более старую версию.
Все, что нам нужно сделать для этого, — изменить тот же файл YAML, в котором было описание нашего Сервиса:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: my-service
spec:
template:
metadata:
name: my-service-v2
spec:
containers:
- image: <location_of_container_image_in_a_registry>
ports:
- containerPort: 8080
traffic:
- latestRevision: true
percent: 50
- revisionName: my-service-v1
percent: 50
Как мы видим, мы добавили новый раздел, описывающий разделение трафика между Ревизиями. Мы просим Knative направить половину трафика на новую версию, а другую — на предыдущую версию . После развертывания этого ресурса мы можем проверить разделение, перечислив все ревизии:
kn revisions list
Хотя Knative упрощает разделение трафика, для чего мы можем его использовать? Ну, может быть несколько вариантов использования этой функции. Например, если мы хотим использовать такую модель развертывания, как сине-зеленая или канареечная, разделение трафика в Knative может оказаться очень кстати. Если мы хотим принять меры по укреплению доверия, такие как A/B-тестирование, мы снова можем положиться на эту функцию.
4.3. Приложение, управляемое событиями, с Knative Eventing
Далее давайте изучим Knative Eventing . Как мы видели ранее, Knative Eventing помогает нам сочетать программирование, управляемое событиями, с бессерверной архитектурой. Но почему мы должны заботиться об архитектуре, управляемой событиями? По сути, управляемая событиями архитектура — это парадигма архитектуры программного обеспечения, которая способствует созданию, обнаружению, потреблению событий и реагированию на них .
Как правило, событием является любое существенное изменение состояния. Например, когда заказ становится отправленным из принятого. Здесь производители и потребители событий полностью разделены. Теперь несвязанные компоненты в любой архитектуре имеют несколько преимуществ. Например, это значительно упрощает горизонтальное масштабирование в моделях распределенных вычислений.
Первый шаг к использованию Knative Eventing — убедиться, что у нас есть доступный брокер. Теперь, как правило, в рамках стандартной установки у нас должен быть доступный в памяти брокер в кластере . Мы можем быстро убедиться в этом, перечислив всех доступных брокеров:
kn broker list
Теперь архитектура, управляемая событиями, достаточно гибкая и может быть как простой службой, так и сложной сетью из сотен служб. Knative Eventing предоставляет базовую инфраструктуру, не накладывая никаких ограничений на то, как мы разрабатываем наши приложения.
Для этого руководства предположим, что у нас есть одна служба, которая создает и использует события. Во-первых, мы должны определить источник для наших событий. Мы можем расширить то же определение сервиса, которое мы использовали ранее, чтобы преобразовать его в Источник:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: my-service
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1"
spec:
containers:
- image: <location_of_container_image_in_a_registry>
env:
- name: BROKER_URL
value: <broker_url_as_provided_by_borker_list_command>
Единственное существенное изменение здесь заключается в том, что мы предоставляем URL-адрес брокера в качестве переменной среды. Теперь, как и раньше, мы можем использовать kubectl для развертывания этого ресурса или напрямую использовать Knative CLI.
Поскольку Knative Eventing отправляет и получает события, соответствующие CloudEvents, с помощью HTTP POST , использовать это в нашем приложении довольно просто. Мы можем просто создать полезную нагрузку события с помощью CloudEvents и использовать любую клиентскую библиотеку HTTP, чтобы отправить ее брокеру.
4.4. Фильтрация и подписка на события с помощью Knative Eventing
До сих пор мы отправляли наши события Брокеру, но что происходит после этого? Теперь нас интересует возможность фильтровать и отправлять эти события конкретным целям. Для этого мы должны определить триггер. По сути, брокеры используют триггеры для пересылки событий нужным потребителям . Теперь в процессе мы также можем фильтровать события, которые мы хотим отправить, на основе любого из атрибутов события.
Как и раньше, мы можем просто создать файл YAML с описанием нашего триггера:
apiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: my-trigger
annotations:
knative-eventing-injection: enabled
spec:
broker: <name_of_the_broker_as_provided_by_borker_list_command>
filter:
attributes:
type: <my_event_type>
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: my-service
Это довольно простой триггер, который определяет ту же службу, которую мы использовали в качестве источника и приемника событий. Интересно, что мы используем фильтр в этом триггере, чтобы отправлять подписчику только события определенного типа . Мы можем создавать гораздо более сложные фильтры.
Теперь, как и раньше, мы можем развернуть этот ресурс с помощью kubectl или использовать Knative CLI, чтобы создать его напрямую. Мы также можем создать столько триггеров, сколько хотим отправлять события разным подписчикам. Как только мы создадим этот триггер, наша служба сможет создавать события любого типа, а из них потреблять события определенного типа!
В Knative Eventing Sink может быть адресуемым или вызываемым ресурсом . Адресные ресурсы получают и подтверждают событие, доставленное по HTTP. Вызываемые ресурсы могут получать событие, доставленное по HTTP, и преобразовывать событие, при необходимости возвращая событие в ответе HTTP. Помимо Сервисов, которые мы сейчас видели, Каналы и Брокеры также могут быть приемниками.
5. Вывод
В этом руководстве мы обсудили, как мы можем использовать Kubernetes в качестве базовой инфраструктуры для размещения бессерверной среды с использованием Knative. Мы рассмотрели базовую архитектуру и компоненты Knative, то есть Knative Serving и Knative Eventing. Это дало нам возможность понять преимущества использования такой среды, как Knaitive, для создания нашего бессерверного приложения.