1. Введение
Обработка графов полезна для многих приложений от социальных сетей до рекламы. В сценарии с большими данными нам нужен инструмент для распределения этой вычислительной нагрузки.
В этом руководстве мы загрузим и изучим возможности графа с помощью Apache Spark в Java. Чтобы избежать сложных структур, мы будем использовать простой и высокоуровневый API графа Apache Spark: API GraphFrames.
2. Графики
Прежде всего, давайте определим граф и его компоненты. Граф — это структура данных, имеющая ребра и вершины. Ребра несут информацию , которая представляет отношения между вершинами.
Вершины — это точки в n - мерном пространстве, а ребра соединяют вершины в соответствии с их отношениями:
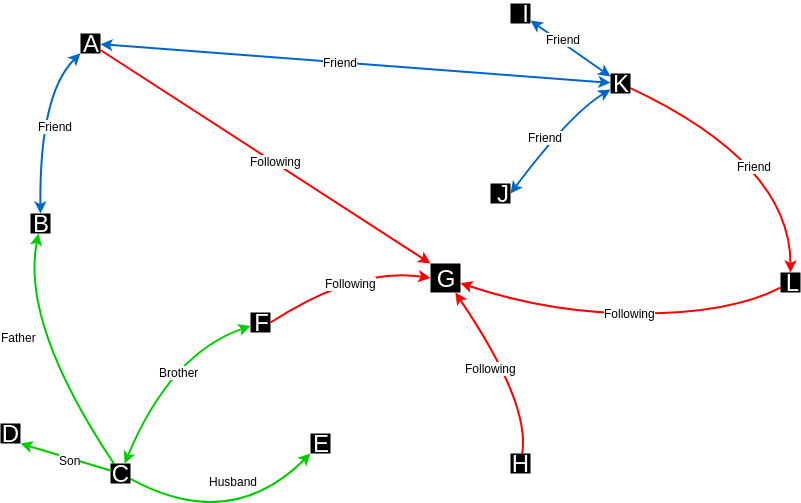
На изображении выше у нас есть пример социальной сети. Мы можем видеть вершины, представленные буквами, и ребра, несущие тип отношений между вершинами.
3. Настройка Мавена
Теперь давайте начнем проект с настройки конфигурации Maven.
Давайте добавим spark-graphx 2.11 , graphframes и spark-sql 2.11 :
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>graphframes</groupId>
<artifactId>graphframes</artifactId>
<version>0.7.0-spark2.4-s_2.11</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.4</version>
</dependency>
Эти версии артефактов поддерживают Scala 2.11.
Также бывает так, что GraphFrames нет в Maven Central. Итак, давайте также добавим необходимый репозиторий Maven:
<repositories>
<repository>
<id>SparkPackagesRepo</id>
<url>http://dl.bintray.com/spark-packages/maven</url>
</repository>
</repositories>
4. Конфигурация искры
Чтобы работать с GraphFrames, нам нужно загрузить Hadoop и определить переменную среды HADOOP_HOME .
В случае Windows в качестве операционной системы мы также загрузим соответствующий файл winutils.exe в папку HADOOP_HOME/bin .
Далее давайте начнем наш код с создания базовой конфигурации:
SparkConf sparkConf = new SparkConf()
.setAppName("SparkGraphFrames")
.setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
Нам также нужно создать SparkSession :
SparkSession session = SparkSession.builder()
.appName("SparkGraphFrameSample")
.config("spark.sql.warehouse.dir", "/file:C:/temp")
.sparkContext(javaSparkContext.sc())
.master("local[*]")
.getOrCreate();
5. Построение графика
Теперь мы готовы начать с нашего основного кода. Итак, давайте определим объекты для наших вершин и ребер и создадим экземпляр GraphFrame .
Мы будем работать над отношениями между пользователями из гипотетической социальной сети.
5.1. Данные
Во-первых, для этого примера давайте определим обе сущности как User и Relationship :
public class User {
private Long id;
private String name;
// constructor, getters and setters
}
public class Relationship implements Serializable {
private String type;
private String src;
private String dst;
private UUID id;
public Relationship(String type, String src, String dst) {
this.type = type;
this.src = src;
this.dst = dst;
this.id = UUID.randomUUID();
}
// getters and setters
}
Далее давайте определим несколько экземпляров User и Relationship :
List<User> users = new ArrayList<>();
users.add(new User(1L, "John"));
users.add(new User(2L, "Martin"));
users.add(new User(3L, "Peter"));
users.add(new User(4L, "Alicia"));
List<Relationship> relationships = new ArrayList<>();
relationships.add(new Relationship("Friend", "1", "2"));
relationships.add(new Relationship("Following", "1", "4"));
relationships.add(new Relationship("Friend", "2", "4"));
relationships.add(new Relationship("Relative", "3", "1"));
relationships.add(new Relationship("Relative", "3", "4"));
5.2. Экземпляр GraphFrame
Теперь, чтобы создать и управлять нашим графом отношений, мы создадим экземпляр GraphFrame . Конструктор GraphFrame ожидает два экземпляра Dataset<Row> , первый из которых представляет вершины, а второй — ребра:
Dataset<Row> userDataset = session.createDataFrame(users, User.class);
Dataset<Row> relationshipDataset = session.createDataFrame(relationships, Relation.class);
GraphFrame graph = new GraphFrame(userDataframe, relationshipDataframe);
Наконец, мы запишем наши вершины и ребра в консоль, чтобы увидеть, как это выглядит:
graph.vertices().show();
graph.edges().show();
+---+------+
| id| name|
+---+------+
| 1| John|
| 2|Martin|
| 3| Peter|
| 4|Alicia|
+---+------+
+---+--------------------+---+---------+
|dst| id|src| type|
+---+--------------------+---+---------+
| 2|622da83f-fb18-484...| 1| Friend|
| 4|c6dde409-c89d-490...| 1|Following|
| 4|360d06e1-4e9b-4ec...| 2| Friend|
| 1|de5e738e-c958-4e0...| 3| Relative|
| 4|d96b045a-6320-4a6...| 3| Relative|
+---+--------------------+---+---------+
6. Операторы графов
Теперь, когда у нас есть экземпляр GraphFrame , давайте посмотрим, что мы можем с ним сделать.
6.1. Фильтр
GraphFrames позволяет нам фильтровать ребра и вершины по запросу.
Затем давайте отфильтруем вершины по свойству name в User :
graph.vertices().filter("name = 'Martin'").show();
В консоли видим результат:
+---+------+
| id| name|
+---+------+
| 2|Martin|
+---+------+
Кроме того, мы можем напрямую фильтровать граф, вызывая filterEdges или filterVertices :
graph.filterEdges("type = 'Friend'")
.dropIsolatedVertices().vertices().show();
Теперь, когда мы отфильтровали ребра, у нас все еще могут быть некоторые изолированные вершины. Итак, мы будем вызывать dropIsolatedVertices().
В результате у нас есть подграф, все еще экземпляр GraphFrame , только с отношениями, имеющими статус «Друг»:
+---+------+
| id| name|
+---+------+
| 1| John|
| 2|Martin|
| 4|Alicia|
+---+------+
6.2. Степени
Еще одним интересным набором функций является набор степеней операций. Эти операции возвращают количество ребер , инцидентных каждой вершине.
Операция градусов просто возвращает количество всех ребер каждой вершины. С другой стороны, inDegrees подсчитывает только входящие ребра, а outDegrees подсчитывает только исходящие ребра.
Подсчитаем входящие степени всех вершин нашего графа:
graph.inDegrees().show();
В результате у нас есть GraphFrame , который показывает количество входящих ребер в каждую вершину, исключая те, у которых их нет:
+---+--------+
| id|inDegree|
+---+--------+
| 1| 1|
| 4| 3|
| 2| 1|
+---+--------+
7. Графические алгоритмы
GraphFrames также предоставляет готовые к использованию популярные алгоритмы — давайте рассмотрим некоторые из них.
7.1. Рейтинг страницы
Алгоритм PageRank взвешивает входящие ребра в вершину и преобразует их в оценку.
Идея состоит в том, что каждое входящее ребро представляет собой подтверждение и делает вершину более значимой в данном графе.
Например, в социальной сети, если за человеком следят разные люди, он или она будет иметь высокий рейтинг.
Запустить алгоритм ранжирования страницы довольно просто:
graph.pageRank()
.maxIter(20)
.resetProbability(0.15)
.run()
.vertices()
.show();
Чтобы настроить этот алгоритм, нам просто нужно предоставить:
maxIter— количество итераций рейтинга страницы для запуска — рекомендуется 20, слишком малое количество снизит качество, а слишком большое ухудшит производительность.resetProbability— вероятность случайного сброса (альфа) — чем она ниже, тем больше будет разница в счете между победителями и проигравшими — допустимые диапазоны от 0 до 1. Обычно 0,15 — хороший показатель
Ответ представляет собой аналогичный GraphFrame, хотя на этот раз мы видим дополнительный столбец с рангом страницы для каждой вершины:
+---+------+------------------+
| id| name| pagerank|
+---+------+------------------+
| 4|Alicia|1.9393230468864597|
| 3| Peter|0.4848822786454427|
| 1| John|0.7272991738542318|
| 2|Martin| 0.848495500613866|
+---+------+------------------+
В нашем графе Алисия является наиболее релевантной вершиной, за ней следуют Мартин и Джон.
7.2. Подключенные компоненты
Алгоритм связанных компонентов находит изолированные кластеры или изолированные подграфы. Эти кластеры представляют собой наборы связанных вершин в графе, где каждая вершина достижима из любой другой вершины в том же наборе.
Мы можем вызвать алгоритм без каких-либо параметров через методconnectedComponents() :
graph.connectedComponents().run().show();
Алгоритм возвращает GraphFrame , содержащий каждую вершину и компонент, к которому она подключена:
+---+------+------------+
| id| name| component|
+---+------+------------+
| 1| John|154618822656|
| 2|Martin|154618822656|
| 3| Peter|154618822656|
| 4|Alicia|154618822656|
+---+------+------------+
Наш граф имеет только одну компоненту — это означает, что у нас нет изолированных подграфов. Компонент имеет автоматически сгенерированный идентификатор, в нашем случае это 154618822656.
Хотя у нас есть еще один столбец — идентификатор компонента — наш график остается прежним.
7.3. Подсчет треугольников
Подсчет треугольников обычно используется для обнаружения и подсчета сообщества в графе социальной сети. Треугольник представляет собой набор из трех вершин, где каждая вершина связана с двумя другими вершинами треугольника.
В сообществе социальной сети легко найти немалое количество связанных друг с другом треугольников.
Мы можем легко выполнить подсчет треугольников непосредственно из нашего экземпляра GraphFrame :
graph.triangleCount().run().show();
Алгоритм также возвращает GraphFrame с количеством треугольников, проходящих через каждую вершину.
+-----+---+------+
|count| id| name|
+-----+---+------+
| 1| 3| Peter|
| 2| 1| John|
| 2| 4|Alicia|
| 1| 2|Martin|
+-----+---+------+
8. Заключение
Apache Spark — отличный инструмент для вычисления соответствующего объема данных оптимизированным и распределенным способом. И библиотека GraphFrames позволяет нам легко распределять операции с графами по Spark .
Как всегда, полный исходный код примера доступен на GitHub .