1. Обзор
В этом руководстве мы поймем, как использовать Apache Spark MLlib для разработки продуктов машинного обучения. Мы разработаем простой продукт машинного обучения с помощью Spark MLlib, чтобы продемонстрировать основные концепции.
2. Краткое введение в машинное обучение
Машинное обучение является частью более широкой концепции, известной как искусственный интеллект . Машинное обучение относится к изучению статистических моделей для решения конкретных задач с помощью шаблонов и выводов. Эти модели «обучаются» для конкретной задачи с помощью обучающих данных, взятых из проблемного пространства.
Мы увидим, что именно влечет за собой это определение, когда возьмем наш пример.
2.1. Категории машинного обучения
Мы можем разделить машинное обучение на контролируемые и неконтролируемые категории в зависимости от подхода. Есть и другие категории, но мы остановимся на этих двух:
Обучение под наблюдением работает с набором данных, который содержит как входные данные, так и желаемый результат — например, набор данных, содержащий различные характеристики недвижимости и ожидаемый доход от аренды. Обучение под наблюдением далее делится на две широкие подкатегории, называемые классификацией и регрессией:
Алгоритмы классификации связаны с категориальным выводом, например, занято ли свойство или нет.
Алгоритмы регрессии связаны с непрерывным выходным диапазоном, таким как значение свойства.
С другой стороны, неконтролируемое обучение работает с набором данных, которые имеют только входные значения . Он работает, пытаясь определить внутреннюю структуру входных данных. Например, поиск различных типов потребителей с помощью набора данных об их потребительском поведении.
2.2. Рабочий процесс машинного обучения
Машинное обучение — действительно междисциплинарная область исследований. Это требует знаний в области бизнеса, статистики, вероятности, линейной алгебры и программирования. Поскольку это явно может стать ошеломляющим, лучше подходить к этому упорядоченно , что мы обычно называем рабочим процессом машинного обучения:
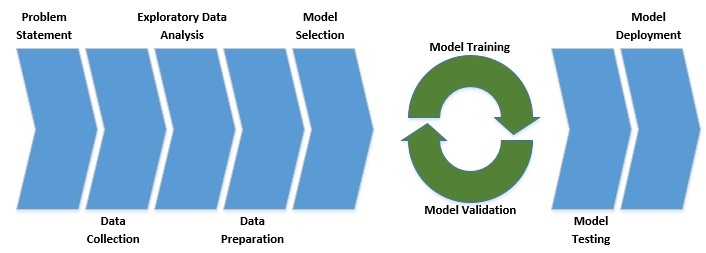
Как мы видим, каждый проект машинного обучения должен начинаться с четко определенной постановки задачи. За этим следует ряд шагов, связанных с данными, которые потенциально могут решить проблему.
Затем мы обычно выбираем модель с учетом характера проблемы. Затем следует серия обучения и проверки модели, известная как тонкая настройка модели. Наконец, мы тестируем модель на ранее неизвестных данных и развертываем ее в рабочей среде, если она удовлетворительна.
3. Что такое Spark MLlib ?
Spark MLlib — это модуль поверх Spark Core, который предоставляет примитивы машинного обучения в виде API. Машинное обучение обычно имеет дело с большим объемом данных для обучения модели.
Базовая вычислительная среда от Spark — огромное преимущество. Кроме того, MLlib предоставляет большинство популярных алгоритмов машинного обучения и статистики. Это значительно упрощает задачу работы над крупномасштабным проектом машинного обучения.
4. Машинное обучение с MLlib
Теперь у нас достаточно информации о машинном обучении и о том, как MLlib может помочь в этом начинании. Давайте начнем с нашего базового примера реализации проекта машинного обучения с помощью Spark MLlib.
Если вспомнить из нашего обсуждения рабочего процесса машинного обучения, мы должны начать с постановки задачи, а затем перейти к данным. К счастью для нас, мы выберем «привет, мир» машинного обучения, Iris Dataset . Это многомерный размеченный набор данных, состоящий из длины и ширины чашелистиков и лепестков разных видов ирисов.
Это ставит перед нашей задачей цель: можем ли мы предсказать вид ириса по длине и ширине его чашелистика и лепестка ?
4.1. Установка зависимостей
Во-первых, мы должны определить следующую зависимость в Maven для извлечения соответствующих библиотек:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>
И нам нужно инициализировать SparkContext для работы с Spark API:
SparkConf conf = new SparkConf()
.setAppName("Main")
.setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(conf);
4.2. Загрузка данных
Прежде всего, мы должны загрузить данные, которые доступны в виде текстового файла в формате CSV. Затем мы должны загрузить эти данные в Spark:
String dataFile = "data\\iris.data";
JavaRDD<String> data = sc.textFile(dataFile);
Spark MLlib предлагает несколько типов данных, как локальных, так и распределенных, для представления входных данных и соответствующих меток. Самый простой из типов данных — это Vector :
JavaRDD<Vector> inputData = data
.map(line -> {
String[] parts = line.split(",");
double[] v = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
v[i] = Double.parseDouble(parts[i]);
}
return Vectors.dense(v);
});
Обратите внимание, что мы включили сюда только входные функции, в основном для статистического анализа.
Обучающий пример обычно состоит из нескольких входных функций и метки, представленной классом LabeledPoint :
Map<String, Integer> map = new HashMap<>();
map.put("Iris-setosa", 0);
map.put("Iris-versicolor", 1);
map.put("Iris-virginica", 2);
JavaRDD<LabeledPoint> labeledData = data
.map(line -> {
String[] parts = line.split(",");
double[] v = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
v[i] = Double.parseDouble(parts[i]);
}
return new LabeledPoint(map.get(parts[parts.length - 1]), Vectors.dense(v));
});
Наша выходная метка в наборе данных является текстовой, обозначающей вид Iris. Чтобы передать это в модель машинного обучения, мы должны преобразовать это в числовые значения.
4.3. Исследовательский анализ данных
Исследовательский анализ данных включает в себя анализ имеющихся данных. Теперь алгоритмы машинного обучения чувствительны к качеству данных , поэтому более качественные данные имеют лучшие перспективы для достижения желаемого результата.
Типичные цели анализа включают удаление аномалий и обнаружение закономерностей. Это даже используется на критических этапах разработки функций, чтобы получить полезные функции из доступных данных.
Наш набор данных в этом примере небольшой и хорошо сформированный. Следовательно, нам не нужно заниматься большим анализом данных. Однако Spark MLlib оснащен API-интерфейсами, позволяющими получить полное представление.
Начнем с простого статистического анализа:
MultivariateStatisticalSummary summary = Statistics.colStats(inputData.rdd());
System.out.println("Summary Mean:");
System.out.println(summary.mean());
System.out.println("Summary Variance:");
System.out.println(summary.variance());
System.out.println("Summary Non-zero:");
System.out.println(summary.numNonzeros());
Здесь мы наблюдаем среднее значение и дисперсию имеющихся у нас признаков. Это полезно для определения необходимости нормализации признаков. Полезно иметь все функции в одном масштабе . Мы также принимаем к сведению ненулевые значения, которые могут отрицательно сказаться на производительности модели.
Вот вывод для наших входных данных:
Summary Mean:
[5.843333333333332,3.0540000000000003,3.7586666666666666,1.1986666666666668]
Summary Variance:
[0.6856935123042509,0.18800402684563744,3.113179418344516,0.5824143176733783]
Summary Non-zero:
[150.0,150.0,150.0,150.0]
Другой важной метрикой для анализа является корреляция между функциями во входных данных:
Matrix correlMatrix = Statistics.corr(inputData.rdd(), "pearson");
System.out.println("Correlation Matrix:");
System.out.println(correlMatrix.toString());
Высокая корреляция между любыми двумя функциями предполагает, что они не добавляют никакой дополнительной ценности, и одну из них можно отбросить. Вот как соотносятся наши функции:
Correlation Matrix:
1.0 -0.10936924995064387 0.8717541573048727 0.8179536333691672
-0.10936924995064387 1.0 -0.4205160964011671 -0.3565440896138163
0.8717541573048727 -0.4205160964011671 1.0 0.9627570970509661
0.8179536333691672 -0.3565440896138163 0.9627570970509661 1.0
4.4. Разделение данных
Если мы вспомним наше обсуждение рабочего процесса машинного обучения, он включает в себя несколько итераций обучения и проверки модели с последующим окончательным тестированием.
Чтобы это произошло, мы должны разделить наши обучающие данные на обучающие, проверочные и тестовые наборы . Для простоты мы пропустим часть проверки. Итак, давайте разделим наши данные на обучающую и тестовую выборки:
JavaRDD<LabeledPoint>[] splits = parsedData.randomSplit(new double[] { 0.8, 0.2 }, 11L);
JavaRDD<LabeledPoint> trainingData = splits[0];
JavaRDD<LabeledPoint> testData = splits[1];
4.5. Обучение модели
Итак, мы достигли этапа, когда мы проанализировали и подготовили наш набор данных. Все, что осталось, это загрузить это в модель и начать волшебство! Что ж, легче сказать, чем сделать. Нам нужно выбрать подходящий алгоритм для нашей задачи — вспомните различные категории машинного обучения, о которых мы говорили ранее.
Нетрудно понять, что наша проблема подпадает под классификацию в рамках контролируемой категории . В настоящее время существует довольно много алгоритмов, доступных для использования в этой категории.
Самый простой из них — логистическая регрессия (пусть нас не смущает слово регрессия, это все-таки алгоритм классификации):
LogisticRegressionModel model = new LogisticRegressionWithLBFGS()
.setNumClasses(3)
.run(trainingData.rdd());
Здесь мы используем трехклассовый классификатор на основе BFGS с ограниченной памятью. Детали этого алгоритма выходят за рамки этого руководства, но это один из наиболее широко используемых алгоритмов.
4.6. Оценка модели
Помните, что обучение модели включает в себя несколько итераций, но для простоты мы использовали здесь только один проход. Теперь, когда мы обучили нашу модель, пришло время проверить это на тестовом наборе данных:
JavaPairRDD<Object, Object> predictionAndLabels = testData
.mapToPair(p -> new Tuple2<>(model.predict(p.features()), p.label()));
MulticlassMetrics metrics = new MulticlassMetrics(predictionAndLabels.rdd());
double accuracy = metrics.accuracy();
System.out.println("Model Accuracy on Test Data: " + accuracy);
Теперь, как мы можем измерить эффективность модели? Есть несколько метрик, которые мы можем использовать, но одна из самых простых — это Accuracy . Проще говоря, точность — это отношение правильного количества прогнозов к общему количеству прогнозов. Вот чего мы можем достичь за один запуск нашей модели:
Model Accuracy on Test Data: 0.9310344827586207
Обратите внимание, что это будет немного отличаться от запуска к запуску из-за стохастической природы алгоритма.
Однако точность не является очень эффективным показателем в некоторых проблемных областях. Другими более сложными показателями являются Precision and Recall (F1 Score), ROC Curve и Confusion Matrix .
4.7. Сохранение и загрузка модели
Наконец, нам часто нужно сохранить обученную модель в файловой системе и загрузить ее для прогнозирования производственных данных. Это тривиально в Spark:
model.save(sc, "model\\logistic-regression");
LogisticRegressionModel sameModel = LogisticRegressionModel
.load(sc, "model\\logistic-regression");
Vector newData = Vectors.dense(new double[]{1,1,1,1});
double prediction = sameModel.predict(newData);
System.out.println("Model Prediction on New Data = " + prediction);
Итак, мы сохраняем модель в файловую систему и загружаем ее обратно. После загрузки модель можно сразу же использовать для прогнозирования вывода новых данных. Вот пример прогноза для случайных новых данных:
Model Prediction on New Data = 2.0
5. За пределами примитивного примера
Хотя пример, который мы рассмотрели, в целом охватывает рабочий процесс проекта машинного обучения, он оставляет много тонких и важных моментов. Хотя здесь невозможно обсудить их подробно, мы, безусловно, можем рассмотреть некоторые важные из них.
Spark MLlib через свои API-интерфейсы имеет обширную поддержку во всех этих областях.
5.1. Выбор модели
Выбор модели часто является одной из сложных и ответственных задач. Обучение модели — это сложный процесс, и гораздо лучше проводить его на модели, которая, как мы уверены, даст желаемые результаты.
Хотя природа проблемы может помочь нам определить категорию алгоритма машинного обучения для выбора, это не полностью выполненная работа. В рамках такой категории, как классификация, как мы видели ранее, часто существует множество возможных различных алгоритмов и их вариаций на выбор .
Часто лучшим способом действий является быстрое создание прототипа на гораздо меньшем наборе данных . Такая библиотека, как Spark MLlib, значительно упрощает работу по быстрому прототипированию.
5.2. Настройка гиперпараметров модели
Типичная модель состоит из функций, параметров и гиперпараметров. Функции — это то, что мы вводим в модель в качестве входных данных. Параметры модели — это переменные, которые модель изучает в процессе обучения. В зависимости от модели существуют определенные дополнительные параметры, которые мы должны установить на основе опыта и итеративно корректировать . Они называются гиперпараметрами модели.
Например, скорость обучения является типичным гиперпараметром в алгоритмах на основе градиентного спуска. Скорость обучения определяет, насколько быстро параметры настраиваются во время тренировочных циклов. Это должно быть правильно установлено, чтобы модель могла эффективно обучаться в разумном темпе.
Хотя мы можем начать с начального значения таких гиперпараметров на основе опыта, мы должны выполнить проверку модели и итеративно вручную настроить их.
5.3. Производительность модели
Статистическая модель во время обучения склонна к переоснащению и недообучению, что приводит к снижению производительности модели . Недообучение относится к случаю, когда модель недостаточно выбирает общие детали из данных. С другой стороны, переоснащение происходит, когда модель также начинает улавливать шум из данных.
Существует несколько способов избежать проблем недообучения и переобучения, которые часто используются в комбинации. Например, для противодействия переобучению наиболее часто используемые методы включают перекрестную проверку и регуляризацию . Точно так же, чтобы улучшить недообучение, мы можем увеличить сложность модели и увеличить время обучения.
Spark MLlib имеет фантастическую поддержку большинства из этих методов, таких как регуляризация и перекрестная проверка. Фактически, большинство алгоритмов поддерживают их по умолчанию.
6. Искра MLlib в сравнении
Хотя Spark MLlib — довольно мощная библиотека для проектов машинного обучения, она, безусловно, не единственная для этой работы. Существует довольно много библиотек, доступных на разных языках программирования с различной поддержкой. Мы рассмотрим некоторые из популярных здесь.
6.1. Тензорфлоу/Керас
Tensorflow — это библиотека с открытым исходным кодом для потоков данных и дифференцируемого программирования, широко используемая для приложений машинного обучения . Вместе с высокоуровневой абстракцией Keras это предпочтительный инструмент для машинного обучения. В основном они написаны на Python и C++ и в основном используются в Python. В отличие от Spark MLlib, в нем нет полиглота.
6.2. Теано
Theano — это еще одна библиотека с открытым исходным кодом на основе Python для управления математическими выражениями и их оценки — например, матричных выражений, которые обычно используются в алгоритмах машинного обучения. В отличие от Spark MLlib, Theano снова в основном используется в Python. Однако Keras можно использовать вместе с серверной частью Theano.
6.3. ЧНТК
Microsoft Cognitive Toolkit (CNTK) — это платформа глубокого обучения, написанная на C++, которая описывает этапы вычислений с помощью ориентированного графа . Его можно использовать как в программах на Python, так и в C++, и в основном он используется при разработке нейронных сетей. Существует серверная часть Keras, основанная на CNTK, доступная для использования, которая обеспечивает знакомую интуитивно понятную абстракцию.
7. Заключение
Подводя итог, в этом уроке мы рассмотрели основы машинного обучения, включая различные категории и рабочий процесс. Мы рассмотрели основы Spark MLlib как доступной нам библиотеки машинного обучения.
Кроме того, мы разработали простое приложение для машинного обучения на основе доступного набора данных. В нашем примере мы реализовали некоторые из наиболее распространенных шагов рабочего процесса машинного обучения.
Мы также рассмотрели некоторые дополнительные шаги в типичном проекте машинного обучения и то, как Spark MLlib может помочь в этом. Наконец, мы увидели несколько альтернативных библиотек машинного обучения, доступных для использования.
Как всегда, код можно найти на GitHub .