1. Обзор
В этой статье мы обсудим транзакции только для чтения. Мы поговорим об их назначении и способах их использования, а также проверим некоторые их нюансы, связанные с производительностью и оптимизацией. Для простоты мы сосредоточимся на движке MySQL InnoDB . Но имейте в виду, что некоторая описанная информация может меняться в зависимости от базы данных/механизма хранения.
2. Что такое транзакция?
Транзакция — это атомарная операция, состоящая из одного или нескольких операторов . Это атомарно, потому что все операторы в этой операции либо завершаются успешно (фиксируются), либо терпят неудачу (откатываются), что означает все или ничего. Буква «A» в свойствах ACID представляет атомарность транзакций.
Еще одна важная вещь, которую нужно понять, это то, что все операторы в движке InnoDB становятся транзакциями, если не явно, то неявно . Такую концепцию становится намного сложнее понять, когда мы добавим параллелизм к уравнению. Затем нам нужно прояснить другое свойство ACID, «I» изоляции.
Понимание свойства уровня изоляции необходимо для того, чтобы мы могли рассуждать о компромиссах между производительностью и гарантиями согласованности . Однако, прежде чем вдаваться в подробности об уровне изоляции, помните, что, поскольку все операторы в InnoDB являются транзакциями, их можно зафиксировать или отменить. Если транзакция не указана, база данных создает ее, и на основе свойства autocommit она может быть зафиксирована или нет.
2.1. Уровни изоляции
В этой статье мы будем использовать значение по умолчанию для MySQL — Repeatable read . Он обеспечивает согласованное чтение в рамках одной и той же транзакции, а это означает, что при первом чтении будет создан моментальный снимок (момент времени), а все последующие чтения будут согласованными по отношению друг к другу. Мы можем обратиться к официальной документации MySQL для получения дополнительной информации об этом. Конечно, хранение таких снимков имеет свои последствия, но гарантирует хороший уровень согласованности.
Разные базы данных могут иметь другие имена или параметры уровня изоляции, но, скорее всего, они будут схожими.
3. Зачем и где использовать транзакцию?
Теперь, когда мы лучше понимаем, что такое транзакция и ее различные свойства, давайте поговорим о транзакциях только для чтения. Как объяснялось ранее, в механизме InnoDB все операторы являются транзакциями, и поэтому они могут включать такие вещи, как блокировка и моментальные снимки. Однако мы видим, что некоторые накладные расходы, связанные с координацией транзакций, такие как маркировка строк идентификаторами транзакций и другими внутренними структурами, могут быть не нужны для простых запросов . Вот где в игру вступают транзакции только для чтения.
Мы можем явно определить транзакцию только для чтения, используя синтаксис START TRANSACTION READ ONLY . MySQL также пытается автоматически обнаруживать переходы только для чтения. Но дальнейшие оптимизации могут быть применены при явном объявлении. Интенсивные чтения приложений могут использовать эту оптимизацию и экономить ресурсы в нашем кластере базы данных .
3.1. Приложение против базы данных
Нам нужно знать, что работа со слоями персистентности в нашем приложении может включать множество уровней абстракций. У каждого из этих слоев своя ответственность. Однако для упрощения предположим, что в конечном итоге эти уровни влияют либо на то, как наше приложение взаимодействует с базой данных, либо на то, как база данных обрабатывает данные.
Конечно, не все приложения имеют все эти слои, но это хорошее обобщение. Короче говоря, если у нас есть приложение Spring, эти слои служат для:
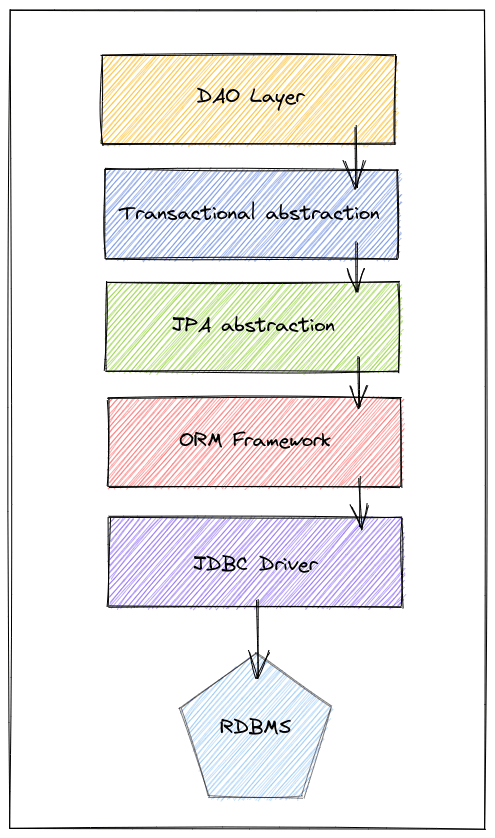
- DAO : действует как мост между бизнес-логикой и нюансами сохраняемости .
- Транзакционная абстракция: заботится о сложности транзакций на уровне приложения (начало, фиксация, откат).
- Абстракция JPA : спецификация Java, которая предлагает стандартный API между поставщиками.
- ORM Framework: фактическая реализация JPA (например, Hibernate).
- JDBC : отвечает за фактическое взаимодействие с базой данных.
Главный вывод заключается в том, что многие из этих факторов могут влиять на поведение наших транзакций. Тем не менее, давайте сосредоточимся на конкретной группе свойств, которая напрямую влияет на это поведение. Обычно клиенты могут определять эти свойства на глобальном уровне или на уровне сеанса . Список всех свойств обширен, поэтому мы обсудим только два из них, которые являются ключевыми. Однако мы уже должны быть с ними знакомы.
3.2. Управление транзакциями
Драйвер JDBC запускает транзакцию со стороны приложения путем отключения свойства autocommit . Это эквивалент оператора BEGIN TRANSACTION , и с этого момента все следующие операторы должны быть зафиксированы или отменены, чтобы завершить транзакцию.
Это свойство, определенное на глобальном уровне, указывает базе данных обрабатывать все входящие запросы как транзакции, выполняемые вручную, и требует от пользователя фиксации или отката. Однако это больше недействительно, если пользователь переопределяет это определение на уровне сеанса. В результате многие драйверы отключают это свойство по умолчанию, чтобы гарантировать согласованное поведение и убедиться, что приложение имеет над ним контроль.
Затем мы можем использовать свойство транзакции , чтобы определить, разрешены операции записи или нет . Но есть одно предостережение: даже в транзакции только для чтения можно манипулировать таблицами, созданными с помощью ключевого слова TEMPORARY . Это свойство также имеет глобальную область действия и область действия сеанса, хотя обычно мы работаем с этим и другими свойствами на уровне сеанса в наших приложениях.
Предостережение заключается в том, что при использовании пулов соединений из-за характера открытия соединений и их повторного использования. Платформы или библиотеки, работающие с транзакциями и соединениями, должны убедиться, что сеансы находятся в чистом состоянии, прежде чем начинать новую транзакцию.
По этой причине можно выполнить несколько операторов, чтобы отменить все оставшиеся ожидающие изменения и правильно настроить сеанс.
Мы уже видели, что приложения с интенсивным чтением могут использовать транзакции только для чтения для оптимизации и экономии ресурсов в нашем кластере базы данных. Но многие разработчики также забывают, что переключение между настройками также вызывает обращения к базе данных, что влияет на пропускную способность соединений.
В MySQL мы можем определить эти свойства на глобальном уровне следующим образом:
SET GLOBAL TRANSACTION READ WRITE;
SET autocommit = 0;
/* transaction */
commit;
Или мы можем установить свойства на уровне сеанса:
SET SESSION TRANSACTION READ ONLY;
SET autocommit = 1;
/* transaction */
3.3. Подсказки
В случае транзакций, которые выполняют только один запрос, включение `` свойства autocommit может избавить нас от повторных обращений . Если это наиболее распространенная причина в нашем приложении, использование отдельного источника данных, установленного как доступного только для чтения, и включение автоматической фиксации по умолчанию будет работать еще лучше.
Теперь, если транзакции имеют больше запросов, мы должны использовать явную транзакцию только для чтения. Создание источника данных, доступного только для чтения, также может помочь сократить круговые пути, избегая переключения между транзакциями записи и только чтения. Но, если у нас смешанные рабочие нагрузки, сложность управления новым источником данных может себя не оправдать .
Другим важным моментом при работе с транзакцией с несколькими операторами является рассмотрение поведения, определяемого уровнем изоляции, поскольку это может изменить результат нашей транзакции и, возможно, повлиять на производительность. Для простоты в наших примерах мы будем рассматривать только значение по умолчанию (повторяемое чтение).
4. Применение на практике
Теперь, со стороны приложения, мы попытаемся понять, как работать с этими свойствами и какие слои могут получить доступ к такому поведению. Но, опять же, ясно, что есть много разных способов сделать это, и в зависимости от фреймворка это может измениться. Поэтому, взяв в качестве примера JPA и Spring, мы можем хорошо понять, как это будет выглядеть и в других ситуациях.
4.1. JPA
Давайте посмотрим, как мы можем эффективно определить транзакцию только для чтения в нашем приложении, используя JPA/Hibernate:
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("jpa-unit");
EntityManager entityManager = entityManagerFactory.createEntityManager();
entityManager.unwrap(Session.class).setDefaultReadOnly(true);
entityManager.getTransaction().begin();
entityManager.find(Book.class, id);
entityManager.getTransaction().commit();
Важно отметить, что в JPA нет стандартного способа определить транзакцию только для чтения . По этой причине нам нужно было получить реальный сеанс Hibernate, чтобы определить его как доступный только для чтения.
4.2. JPA+Весна
При использовании системы управления транзакциями Spring все становится еще проще, как мы видим далее:
@Transactional(readOnly = true)
public Book getBookById(long id) {
return entityManagerFactory.createEntityManager().find(Book.class, id);
}
Делая это, Spring берет на себя ответственность за открытие, закрытие и определение режима транзакции. Однако даже это иногда не нужно, так как при использовании Spring Data JPA у нас уже есть готовая такая конфигурация.
Базовый класс репозитория Spring JPA помечает все методы как транзакции только для чтения. Добавляя эту аннотацию на уровне класса, можно изменить поведение методов, просто добавив @Transactional на уровне метода.
Наконец, также можно определить соединение только для чтения и изменить свойство autocommit при настройке нашего источника данных. Как мы видели, это может еще больше повысить производительность приложения, если нам нужны только чтения. Источник данных содержит следующие конфигурации:
@Bean
public DataSource readOnlyDataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost/foreach?useUnicode=true&characterEncoding=UTF-8");
config.setUsername("foreach");
config.setPassword("foreach");
config.setReadOnly(true);
config.setAutoCommit(true);
return new HikariDataSource(config);
}
Однако это имеет смысл только в сценариях, где преобладающей характеристикой нашего приложения являются ресурсы с одним запросом. Кроме того, при использовании Spring Data JPA необходимо отключить транзакции по умолчанию, созданные Spring. Поэтому нам нужно только настроить свойство enableDefaultTransactions на false :
@Configuration
@EnableJpaRepositories(enableDefaultTransactions = false)
@EnableTransactionManagement
public class Config {
//Definition of data sources and other persistence related beans
}
С этого момента у нас есть полный контроль и ответственность за добавление @Transactional(readOnly=true) при необходимости. Тем не менее, это не относится к большинству приложений, поэтому нам не следует изменять эти конфигурации, если мы не уверены, что наше приложение получит от них пользу.
4.3. Операторы маршрутизации
В более реальном сценарии у нас могло бы быть два источника данных, один для записи и один для чтения . Затем нам нужно будет определить, какой источник данных использовать на уровне компонентов. Этот подход более эффективно обрабатывает соединения для чтения и предотвращает использование ненужных команд для обеспечения чистоты сеанса и соответствующей настройки .
Есть несколько способов добиться этого результата, но сначала мы создадим класс источника данных маршрутизатора:
public class RoutingDS extends AbstractRoutingDataSource {
public RoutingDS(DataSource writer, DataSource reader) {
Map<Object, Object> dataSources = new HashMap<>();
dataSources.put("writer", writer);
dataSources.put("reader", reader);
setTargetDataSources(dataSources);
}
@Override
protected Object determineCurrentLookupKey() {
return ReadOnlyContext.isReadOnly() ? "reader" : "writer";
}
}
О маршрутизации источников данных нужно знать гораздо больше . Однако, чтобы подвести итог, в нашем случае этот класс будет возвращать соответствующий источник данных, когда приложение запрашивает его. Для этого мы используем класс ReadOnlyContent , который будет содержать контекст источника данных во время выполнения:
public class ReadOnlyContext {
private static final ThreadLocal<AtomicInteger> READ_ONLY_LEVEL = ThreadLocal.withInitial(() -> new AtomicInteger(0));
//default constructor
public static boolean isReadOnly() {
return READ_ONLY_LEVEL.get()
.get() > 0;
}
public static void enter() {
READ_ONLY_LEVEL.get()
.incrementAndGet();
}
public static void exit() {
READ_ONLY_LEVEL.get()
.decrementAndGet();
}
}
Далее нам нужно определить эти источники данных и зарегистрировать их в контексте Spring. Для этого нам достаточно использовать созданный ранее класс RoutingDS :
//annotations mentioned previously
public Config {
//other beans...
@Bean
public DataSource routingDataSource() {
return new RoutingDS(
dataSource(false, false),
dataSource(true, true)
);
}
private DataSource dataSource(boolean readOnly, boolean isAutoCommit) {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost/foreach?useUnicode=true&characterEncoding=UTF-8");
config.setUsername("foreach");
config.setPassword("foreach");
config.setReadOnly(readOnly);
config.setAutoCommit(isAutoCommit);
return new HikariDataSource(config);
}
// other beans...
}
Почти готово — теперь давайте создадим аннотацию, чтобы сообщить Spring, когда нужно обернуть компонент в контекст только для чтения . Для этого воспользуемся аннотацией @ReaderDS :
@Inherited
@Retention(RetentionPolicy.RUNTIME)
public @interface ReaderDS {
}
Наконец, мы используем АОП для переноса выполнения компонента в контекст:
@Aspect
@Component
public class ReadOnlyInterception {
@Around("@annotation(com.foreach.readonlytransactions.mysql.spring.ReaderDS)")
public Object aroundMethod(ProceedingJoinPoint joinPoint) throws Throwable {
try {
ReadOnlyContext.enter();
return joinPoint.proceed();
} finally {
ReadOnlyContext.exit();
}
}
}
Обычно мы хотим добавить аннотацию на максимально возможном уровне. Тем не менее, для простоты мы добавим слой репозитория, а в компоненте всего один запрос:
public interface BookRepository extends JpaRepository<BookEntity, Long> {
@ReaderDS
@Query("Select t from BookEntity t where t.id = ?1")
BookEntity get(Long id);
}
Как мы видим, эта настройка позволяет нам более эффективно справляться с операциями только для чтения, используя все транзакции только для чтения и избегая переключения контекста сеанса . В результате это может значительно увеличить пропускную способность и скорость отклика нашего приложения.
5. Вывод
В этой статье мы рассмотрели транзакции только для чтения и их преимущества. Мы также поняли, как работает с ними движок MySQL InnoDB и как настроить основные свойства, влияющие на транзакции нашего приложения. Кроме того, мы обсудили возможности дополнительных улучшений за счет использования выделенных ресурсов, таких как выделенные источники данных. Как обычно, все примеры кода, использованные в этой статье, доступны на GitHub .