1. Введение
В этом руководстве мы рассмотрим параллелизм в реактивных программах, написанных с помощью Spring WebFlux .
Мы начнем с обсуждения параллелизма в отношении реактивного программирования. После этого мы рассмотрим, как Spring WebFlux предлагает абстракции параллелизма для различных библиотек реактивного сервера.
2. Мотивация реактивного программирования
Типичное веб-приложение состоит из нескольких сложных взаимодействующих частей . Многие из этих взаимодействий носят блокирующий характер , например те, которые связаны с обращением к базе данных для выборки или обновления данных. Однако несколько других являются независимыми и могут выполняться одновременно, возможно, параллельно.
Например, два пользовательских запроса к веб-серверу могут обрабатываться разными потоками. На многоядерной платформе это дает очевидное преимущество с точки зрения общего времени отклика. Следовательно, эта модель параллелизма известна как модель потока на запрос :
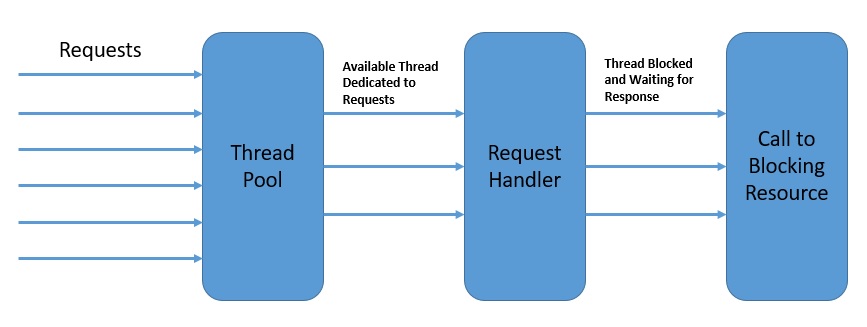
На приведенной выше диаграмме каждый поток обрабатывает один запрос за раз.
Хотя параллелизм на основе потоков решает часть проблемы для нас, он никак не устраняет тот факт, что большинство наших взаимодействий в одном потоке по-прежнему блокируются . Более того, нативные потоки, которые мы используем для достижения параллелизма в Java, требуют значительных затрат с точки зрения переключения контекста.
Между тем, поскольку веб-приложения сталкиваются со все большим количеством запросов, модель « поток на запрос» начинает не оправдывать ожиданий .
Следовательно, нам нужна модель параллелизма, которая может помочь нам обрабатывать все больше запросов с относительно меньшим количеством потоков . Это одна из основных причин принятия реактивного программирования .
3. Параллелизм в реактивном программировании
Реактивное программирование помогает нам структурировать программу с точки зрения потоков данных и распространения изменений через них . Следовательно, в полностью неблокирующей среде это может позволить нам достичь более высокой параллелизма с лучшим использованием ресурсов.
Однако является ли реактивное программирование полным отходом от параллелизма на основе потоков? Несмотря на то, что это сильное заявление, реактивное программирование, безусловно, имеет совершенно другой подход к использованию потоков для достижения параллелизма . Итак, фундаментальное отличие реактивного программирования — асинхронность.
Другими словами, поток программы из последовательности синхронных операций превращается в асинхронный поток событий.
Например, в реактивной модели вызов чтения базы данных не блокирует вызывающий поток во время выборки данных. Вызов немедленно возвращает издателя, на которого могут подписаться другие . Подписчик может обработать событие после того, как оно произошло, и даже сам может генерировать события:
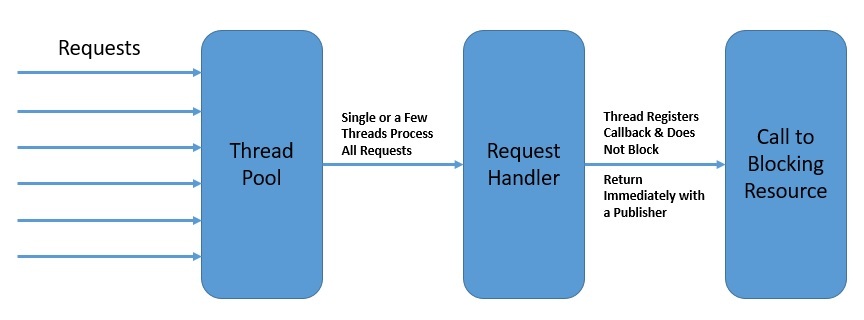
Прежде всего, реактивное программирование не акцентирует внимание на том, какие события потоков должны генерироваться и потребляться. Упор делается, скорее, на структурирование программы как асинхронного потока событий .
Издатель и подписчик здесь не обязательно должны быть частью одного и того же потока. Это помогает нам лучше использовать доступные потоки и, следовательно, повысить общий параллелизм.
4. Цикл событий
Существует несколько моделей программирования, описывающих реактивный подход к параллелизму .
В этом разделе мы рассмотрим некоторые из них, чтобы понять, как реактивное программирование обеспечивает более высокий параллелизм с меньшим количеством потоков.
Одной из таких моделей реактивного асинхронного программирования для серверов является модель цикла событий `` :
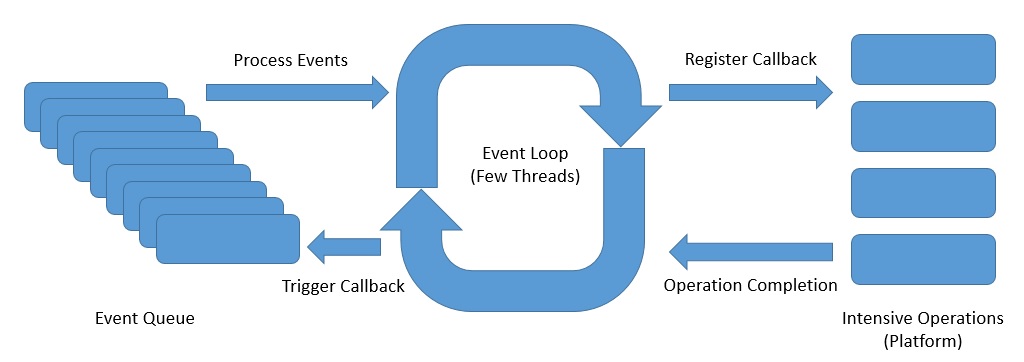
Выше показан абстрактный дизайн цикла событий , в котором представлены идеи реактивного асинхронного программирования:
- Цикл
событийвыполняется непрерывно в одном потоке , хотя у нас может быть столькоциклов событий,сколько доступно ядер. - Цикл
событийпоследовательно обрабатывает события изочереди событийи возвращается сразу после регистрацииобратного вызованаплатформе . - Платформа может инициировать завершение операции
,такой как вызов базы данных или вызов внешней службы. - Цикл
событийможет инициироватьобратный вызовв уведомлении озавершении операциии отправить результат исходному вызывающему абоненту.
Модель цикла событий реализована на ряде платформ, включая Node.js , Netty и Ngnix . Они предлагают гораздо лучшую масштабируемость, чем традиционные платформы, такие как Apache HTTP Server , Tomcat или JBoss .
5. Реактивное программирование с Spring WebFlux
Теперь у нас достаточно информации о реактивном программировании и его модели параллелизма, чтобы исследовать эту тему в Spring WebFlux.
WebFlux это ** Веб-фреймворк Spring ** с реактивным стеком , добавленный в версии 5.0.
Давайте рассмотрим серверный стек Spring WebFlux, чтобы понять, как он дополняет традиционный веб-стек в Spring:
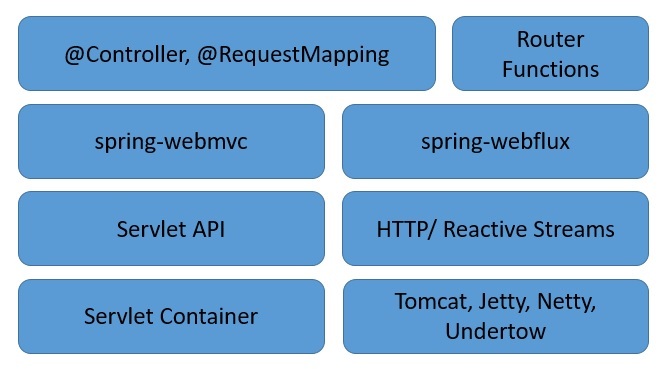
Как мы видим, Spring WebFlux работает параллельно с традиционным веб-фреймворком Spring и не обязательно заменяет его .
Здесь следует отметить несколько важных моментов:
- Spring WebFlux расширяет традиционную модель программирования на основе аннотаций функциональной маршрутизацией.
- Кроме того, он адаптирует базовые среды выполнения HTTP к
API Reactive Streams,делая среды выполнения совместимыми. - Следовательно, он может поддерживать широкий спектр реактивных сред выполнения, включая контейнеры Servlet 3.1+, такие как Tomcat, Reactor, Netty или Undertow.
- Наконец, он включает в себя
WebClient, реактивный и неблокирующий клиент для HTTP-запросов, предлагающий функциональные и плавные API.
6. Модель потоков в поддерживаемых средах выполнения
Как мы обсуждали ранее, реактивные программы, как правило, работают всего с несколькими потоками и максимально используют их. Однако количество и характер потоков зависят от фактической среды выполнения Reactive Stream API, которую мы выбираем.
Чтобы уточнить, Spring WebFlux может адаптироваться к различным средам выполнения с помощью общего API, предоставляемого HttpHandler . Этот API представляет собой простой контракт только с одним методом, который обеспечивает абстракцию над различными серверными API, такими как Reactor Netty, Servlet 3.1 API или API Undertow.
Давайте теперь разберемся с потоковой моделью, реализованной в некоторых из них.
Хотя Netty является сервером по умолчанию в приложении WebFlux, достаточно объявить правильную зависимость для переключения на любой другой поддерживаемый сервер :
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-reactor-netty</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>
Хотя потоки, созданные в виртуальной машине Java, можно наблюдать несколькими способами, довольно легко просто извлечь их из самого класса Thread :
Thread.getAllStackTraces()
.keySet()
.stream()
.collect(Collectors.toList());
6.1. Реактор Нетти
Как мы уже говорили, Reactor Netty является встроенным сервером по умолчанию в стартере Spring Boot WebFlux. Давайте попробуем увидеть потоки, которые Netty создает по умолчанию. Следовательно, в начале мы не будем добавлять какие-либо другие зависимости или использовать WebClient. Итак, если мы запустим приложение Spring WebFlux, созданное с помощью его стартера SpringBoot, мы можем ожидать увидеть некоторые потоки, которые оно создает по умолчанию:
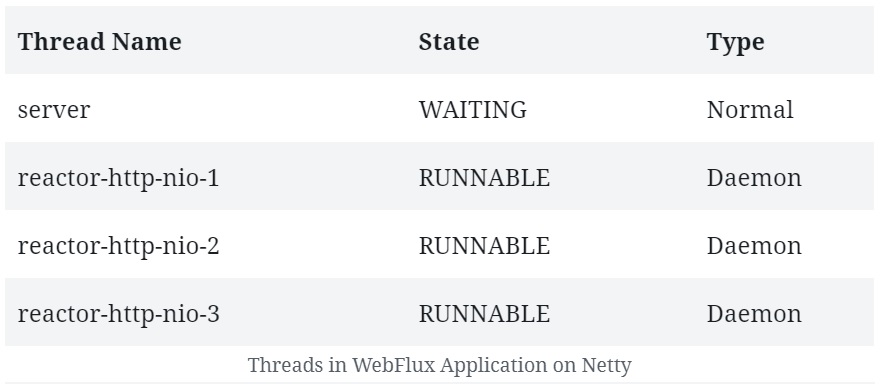
Обратите внимание, что помимо обычного потока для сервера, Netty порождает кучу рабочих потоков для обработки запросов . Обычно это не более чем доступные ядра ЦП. Это результат работы четырехъядерной машины. Мы также увидим кучу вспомогательных потоков, типичных для среды JVM, но здесь они не важны.
Netty использует модель цикла событий для обеспечения высокомасштабируемого параллелизма реактивным асинхронным способом. Давайте посмотрим, как Netty реализует цикл обработки событий , используя Java NIO для обеспечения этой масштабируемости :
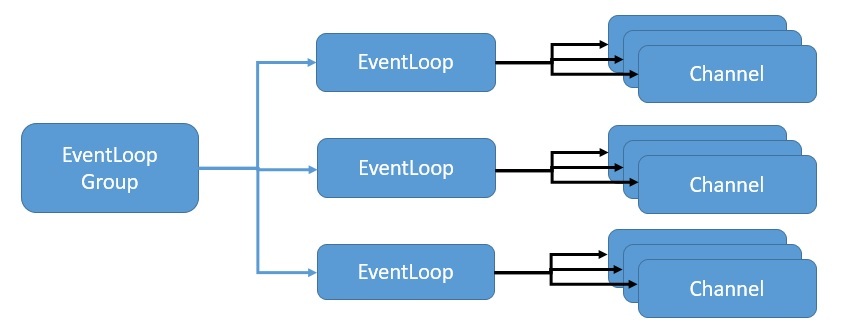
Здесь EventLoopGroup управляет одним или несколькими EventLoop , которые должны работать непрерывно . Следовательно, не рекомендуется создавать больше EventLoop, чем количество доступных ядер.
Группа EventLoopGroup дополнительно назначает EventLoop каждому вновь созданному каналу . Таким образом, в течение всего времени существования Channel все операции выполняются одним и тем же потоком.
6.2. Апач Томкэт
Spring WebFlux также поддерживается в традиционном контейнере сервлетов, таком как Apache Tomcat .
WebFlux опирается на API Servlet 3.1 с неблокирующим вводом-выводом . Хотя он использует Servlet API за низкоуровневым адаптером, Servlet API недоступен для прямого использования.
Давайте посмотрим, какие потоки мы ожидаем в приложении WebFlux, работающем на Tomcat:
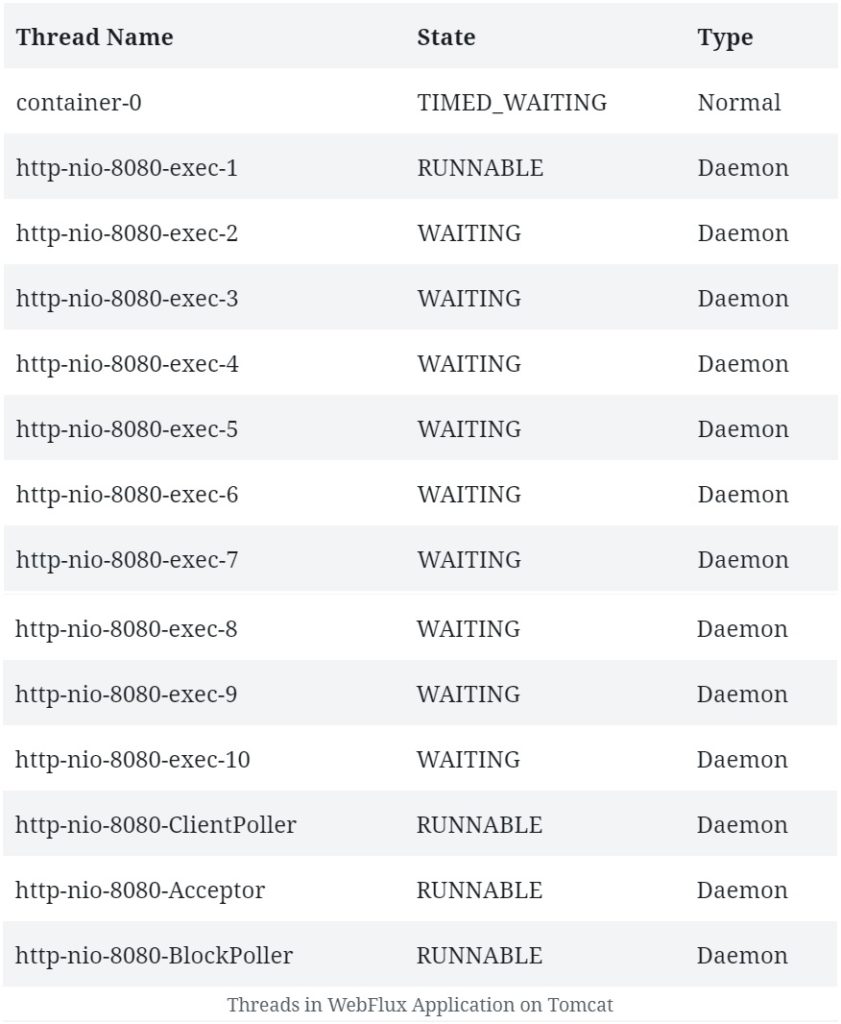
Количество и тип потоков, которые мы видим здесь, сильно отличаются от того, что мы наблюдали ранее.
Начнем с того, что Tomcat начинает работу с большим количеством рабочих потоков, которое по умолчанию равно десяти . Конечно, мы также увидим некоторые служебные потоки, типичные для JVM и контейнера Catalina, которые мы можем проигнорировать в этом обсуждении.
Давайте разберемся в архитектуре Tomcat с Java NIO, чтобы соотнести ее с потоками, которые мы видели выше.
Tomcat 5 и более поздних версий поддерживает NIO в своем компоненте Connector, который в первую очередь отвечает за получение запросов .
Другой компонент Tomcat — это компонент Container, отвечающий за функции управления контейнером.
Здесь нас интересует модель потоков, которую компонент Connector реализует для поддержки NIO. Он состоит из Acceptor , Poller и Worker как часть модуля NioEndpoint :
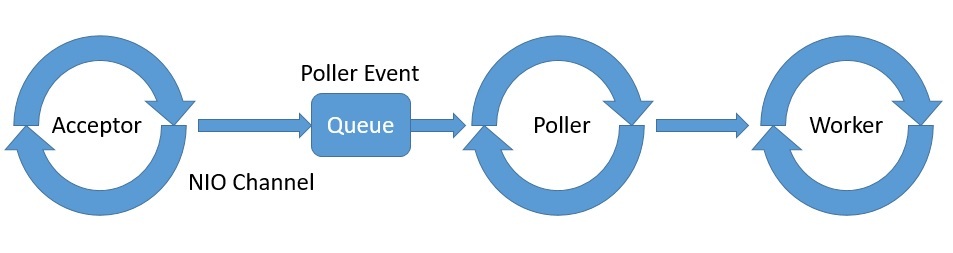
Tomcat порождает один или несколько потоков для Acceptor , Poller и Worker с обычно пулом потоков, выделенным для Worker .
Хотя подробное обсуждение архитектуры Tomcat выходит за рамки этого руководства, теперь у нас должно быть достаточно информации, чтобы понять потоки, которые мы видели ранее.
7. Потоковая модель в WebClient
WebClient — это реактивный HTTP-клиент, входящий в состав Spring WebFlux . Мы можем использовать его в любое время, когда нам требуется связь на основе REST, которая позволяет нам создавать сквозные реактивные приложения .
Как мы видели ранее, реактивные приложения работают всего с несколькими потоками, поэтому у какой-либо части приложения нет возможности заблокировать поток. Следовательно, WebClient играет жизненно важную роль, помогая нам реализовать потенциал WebFlux.
7.1. Использование веб-клиента
Использование WebClient также довольно просто. Нам не нужно включать какие-либо конкретные зависимости, так как это часть Spring WebFlux .
Давайте создадим простую конечную точку REST, которая возвращает Mono :
@GetMapping("/index")
public Mono<String> getIndex() {
return Mono.just("Hello World!");
}
Затем мы будем использовать WebClient для вызова этой конечной точки REST и реактивного использования данных:
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.doOnNext(s -> printThreads());
Здесь мы также печатаем потоки, созданные с помощью метода, который мы обсуждали ранее.
7.2. Понимание потоковой модели
Итак, как работает модель потоков в случае WebClient ?
Что ж, неудивительно, что WebClient также реализует параллелизм, используя модель цикла событий . Конечно, он полагается на базовую среду выполнения для обеспечения необходимой инфраструктуры.
Если мы запускаем WebClient на Reactor Netty, он разделяет цикл обработки событий, который Netty использует для сервера . Следовательно, в этом случае мы можем не заметить большой разницы в создаваемых потоках.
Однако WebClient также поддерживается в контейнере Servlet 3.1+, таком как Jetty, но способ его работы там другой .
Если мы сравним потоки, созданные в приложении WebFlux, работающем с Jetty , с WebClient и без него , мы заметим несколько дополнительных потоков.
Здесь WebClient должен создать свой цикл обработки событий . Итак, мы можем видеть фиксированное количество потоков обработки, которые создает этот цикл событий:
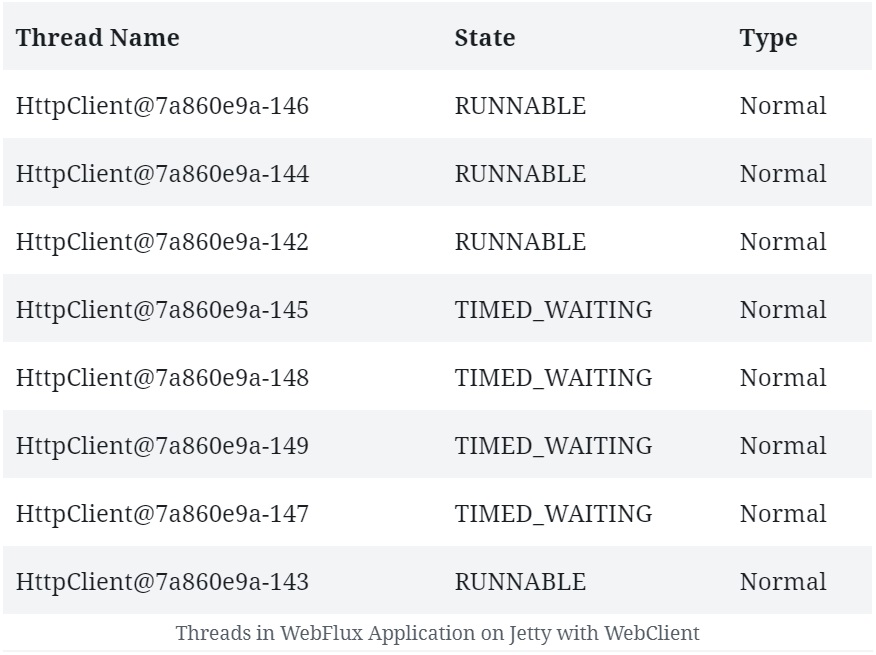
В некоторых случаях наличие отдельного пула потоков для клиента и сервера может обеспечить лучшую производительность . Хотя это не поведение по умолчанию для Netty, всегда можно объявить выделенный пул потоков для WebClient , если это необходимо.
Мы увидим, как это возможно, в следующем разделе.
8. Модель потоков в библиотеках доступа к данным
Как мы видели ранее, даже простое приложение обычно состоит из нескольких частей, которые нужно соединить.
Типичными примерами этих частей являются базы данных и брокеры сообщений. Существующие библиотеки для подключения ко многим из них по-прежнему блокируются, но ситуация быстро меняется.
В настоящее время существует несколько баз данных, предлагающих реактивные библиотеки для подключения . Многие из этих библиотек доступны в Spring Data , а другие мы также можем использовать напрямую.
Модель потоков, которую используют эти библиотеки, представляет для нас особый интерес.
8.1. Весенние данные MongoDB
Spring Data MongoDB обеспечивает поддержку реактивного репозитория для MongoDB, созданного поверх драйвера MongoDB Reactive Streams . В частности, этот драйвер полностью реализует API Reactive Streams для обеспечения асинхронной обработки потоков с неблокирующим противодавлением .
Настроить поддержку реактивного репозитория для MongoDB в приложении Spring Boot так же просто, как добавить зависимость:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>
Это позволит нам создать репозиторий и использовать его для выполнения некоторых основных операций с MongoDB неблокирующим образом:
public interface PersonRepository extends ReactiveMongoRepository<Person, ObjectId> {
}
.....
personRepository.findAll().doOnComplete(this::printThreads);
Итак, какие потоки мы можем ожидать, когда запустим это приложение на сервере Netty?
Что ж, неудивительно, что мы не увидим большой разницы, поскольку реактивный репозиторий Spring Data использует тот же цикл событий, что и сервер.
8.2. Реактор Кафка
Spring все еще находится в процессе создания полноценной поддержки реактивной Kafka. Однако у нас есть варианты, доступные за пределами Spring.
Reactor Kafka — это реактивный API для Kafka на основе Reactor . Reactor Kafka позволяет публиковать и использовать сообщения с помощью функциональных API, а также с неблокирующим обратным давлением .
Во-первых, нам нужно добавить необходимую зависимость в наше приложение, чтобы начать использовать Reactor Kafka:
<dependency>
<groupId>io.projectreactor.kafka</groupId>
<artifactId>reactor-kafka</artifactId>
<version>1.3.10</version>
</dependency>
Это должно позволить нам отправлять сообщения Kafka неблокирующим образом:
// producerProps: Map of Standard Kafka Producer Configurations
SenderOptions<Integer, String> senderOptions = SenderOptions.create(producerProps);
KafkaSender<Integer, String> sender = KafkaSender.create(senderOptions);
Flux<SenderRecord<Integer, String, Integer>> outboundFlux = Flux
.range(1, 10)
.map(i -> SenderRecord.create(new ProducerRecord<>("reactive-test", i, "Message_" + i), i));
sender.send(outboundFlux).subscribe();
Точно так же мы должны иметь возможность получать сообщения от Kafka также неблокирующим образом:
// consumerProps: Map of Standard Kafka Consumer Configurations
ReceiverOptions<Integer, String> receiverOptions = ReceiverOptions.create(consumerProps);
receiverOptions.subscription(Collections.singleton("reactive-test"));
KafkaReceiver<Integer, String> receiver = KafkaReceiver.create(receiverOptions);
Flux<ReceiverRecord<Integer, String>> inboundFlux = receiver.receive();
inboundFlux.doOnComplete(this::printThreads)
Это довольно просто и понятно.
Мы подписываемся на реактивный тест темы в Кафке и получаем поток сообщений.
Для нас интересны потоки, которые создаются :
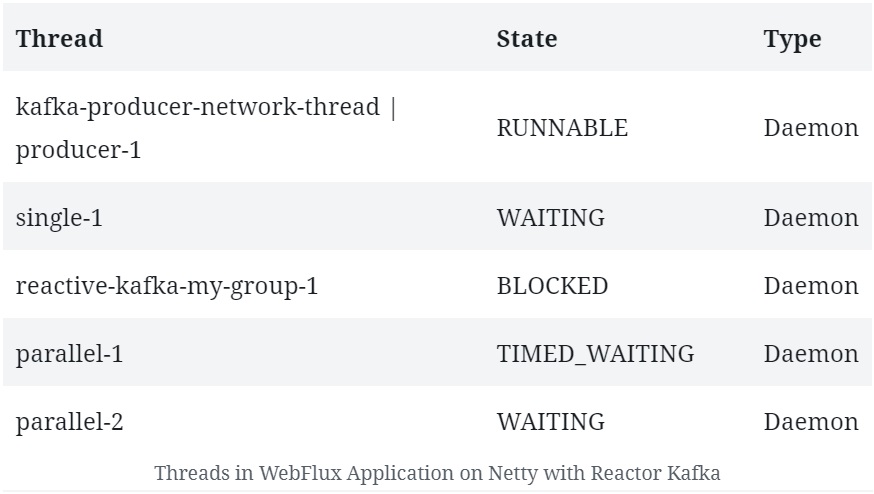
Мы видим несколько потоков, которые не типичны для сервера Netty .
Это указывает на то, что Reactor Kafka управляет собственным пулом потоков с несколькими рабочими потоками, которые участвуют исключительно в обработке сообщений Kafka. Конечно, мы увидим кучу других потоков, связанных с Netty и JVM, которые мы можем игнорировать.
Производители Kafka используют отдельный сетевой поток для отправки запросов брокеру. Далее они доставляют ответы приложению по однопоточному планировщику из пула .
С другой стороны, потребитель Kafka имеет один поток на группу потребителей, который блокирует прослушивание входящих сообщений. Затем входящие сообщения планируются для обработки в другом пуле потоков.
9. Параметры планирования в WebFlux
До сих пор мы видели, что реактивное программирование действительно сияет в полностью неблокирующей среде всего с несколькими потоками . Но это также означает, что если какая-то часть действительно блокируется, это приведет к значительному ухудшению производительности. Это связано с тем, что блокирующая операция может полностью заморозить цикл обработки событий.
Итак, как мы справляемся с длительными процессами или блокирующими операциями в реактивном программировании?
Честно говоря, лучшим вариантом было бы просто избегать их. Однако это не всегда возможно, и нам может понадобиться специальная стратегия планирования для этих частей нашего приложения .
Spring WebFlux предлагает механизм переключения обработки на другой пул потоков между цепочками потоков данных . Это может дать нам точный контроль над стратегией планирования, которую мы хотим для определенных задач. Конечно, WebFlux может предложить это на основе абстракций пула потоков, известных как планировщики, доступные в базовых реактивных библиотеках.
9.1. Реактор
В Reactor класс Scheduler определяет модель выполнения, а также место его выполнения .
Класс Schedulers предоставляет ряд контекстов выполнения, таких как немедленный , одиночный , эластичный и параллельный .
Они предоставляют различные типы пулов потоков, которые могут быть полезны для различных задач. Более того, мы всегда можем создать собственный планировщик с уже существующим ExecutorService .
В то время как планировщики предоставляют нам несколько контекстов выполнения, Reactor также предоставляет нам различные способы переключения контекста выполнения . Это методы publishOn и subscribeOn .
Мы можем использовать publishOn с планировщиком в любом месте цепочки, при этом этот планировщик влияет на все последующие операторы.
Хотя мы также можем использовать subscribeOn с планировщиком в любом месте цепочки, это повлияет только на контекст источника эмиссии.
Если мы помним, WebClient на Netty использует тот же цикл обработки событий, созданный для сервера, в качестве поведения по умолчанию. Однако у нас могут быть веские причины для создания выделенного пула потоков для WebClient.
Давайте посмотрим, как мы можем добиться этого в Reactor, который является реактивной библиотекой по умолчанию в WebFlux:
Scheduler scheduler = Schedulers.newBoundedElastic(5, 10, "MyThreadGroup");
WebClient.create("http://localhost:8080/index").get()
.retrieve()
.bodyToMono(String.class)
.publishOn(scheduler)
.doOnNext(s -> printThreads());
Ранее мы не наблюдали никакой разницы в тредах, созданных на Netty с WebClient или без него . Однако, если мы сейчас запустим приведенный выше код, мы увидим создание нескольких новых потоков :
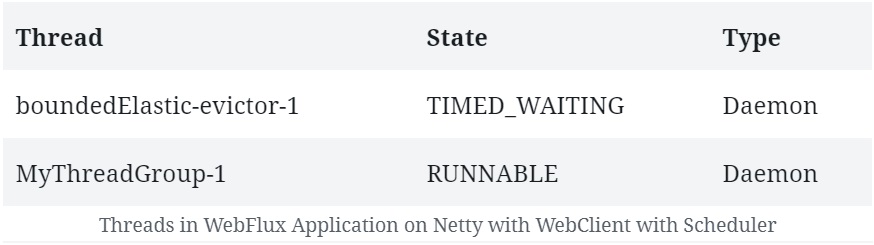
Здесь мы можем видеть потоки, созданные как часть нашего ограниченного пула эластичных потоков . Именно здесь публикуются ответы от WebClient после подписки.
Это оставляет основной пул потоков для обработки запросов сервера.
9.2. RxJava
Поведение по умолчанию в RxJava не сильно отличается от поведения Reactor .
Observable и цепочка операторов, которые мы применяем к нему, выполняют свою работу — и уведомляют наблюдателей — в том же потоке, где была вызвана подписка. Кроме того, RxJava , как и Reactor, предлагает способы введения в цепочку префиксных или пользовательских стратегий планирования.
В RxJava также есть класс Schedulers , который предлагает ряд моделей выполнения для цепочки Observable . К ним относятся новый поток , немедленный , трамплин , ввод -вывод , вычисление и тест . Конечно, это также позволяет нам определить Scheduler из Java Executor .
Более того, RxJava также предлагает два метода расширения для достижения этой цели : subscribeOn иObservOn . ``
Метод subscribeOn изменяет поведение по умолчанию, указывая другой планировщик , с которым должен работать Observable .
С другой стороны, метод visibleOn указывает другой планировщик, который Observable может использовать для отправки уведомлений наблюдателям.
Как мы уже обсуждали ранее, Spring WebFlux по умолчанию использует Reactor в качестве своей реактивной библиотеки. Но поскольку он полностью совместим с API Reactive Streams, можно переключиться на другую реализацию Reactive Streams, например RxJava (для RxJava 1.x с адаптером Reactive Streams).
Нам нужно явно добавить зависимость:
<dependency>
<groupId>io.reactivex.rxjava2</groupId>
<artifactId>rxjava</artifactId>
<version>2.2.21</version>
</dependency>
Затем мы можем начать использовать типы RxJava, такие как Observable , в нашем приложении вместе со специфическими планировщиками RxJava :
io.reactivex.Observable
.fromIterable(Arrays.asList("Tom", "Sawyer"))
.map(s -> s.toUpperCase())
.observeOn(io.reactivex.schedulers.Schedulers.trampoline())
.doOnComplete(this::printThreads);
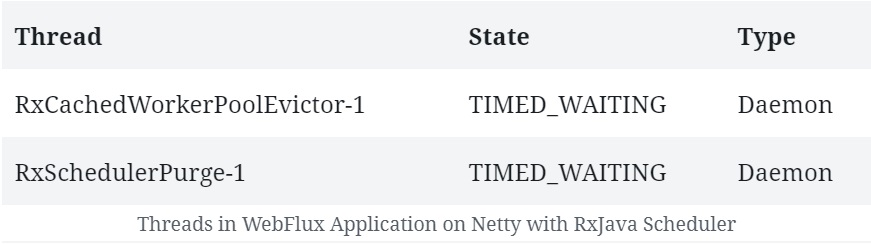
В результате, если мы запустим это приложение, помимо обычных потоков, связанных с Netty и JVM, мы должны увидеть несколько потоков, связанных с нашим планировщиком RxJava :
10. Заключение
В этой статье мы рассмотрели предпосылки реактивного программирования в контексте параллелизма.
Мы наблюдали разницу в модели параллелизма в традиционном и реактивном программировании. Это позволило нам изучить модель параллелизма в Spring WebFlux и ее использование для достижения этой модели многопоточности.
Кроме того, мы изучили модель потоков в WebFlux в сочетании с различными средами выполнения HTTP и реактивными библиотеками.
Мы также обсудили, чем отличается модель потоков при использовании WebClient или библиотеки доступа к данным.
Наконец, мы коснулись вариантов управления стратегией планирования в нашей реактивной программе в WebFlux.
Как всегда, исходный код этой статьи можно найти на GitHub .