1. Обзор
В этом руководстве рассматриваются пулы потоков в Java. Мы начнем с различных реализаций в стандартной библиотеке Java, а затем рассмотрим библиотеку Google Guava.
2. Пул потоков
В Java потоки сопоставляются с потоками системного уровня, которые являются ресурсами операционной системы. Если мы будем бесконтрольно создавать потоки, у нас могут быстро закончиться эти ресурсы.
Операционная система также выполняет переключение контекста между потоками — для имитации параллелизма. Упрощенно говоря, чем больше потоков мы создаем, тем меньше времени каждый поток тратит на реальную работу.
Шаблон пула потоков помогает экономить ресурсы в многопоточном приложении и сдерживать параллелизм в определенных предопределенных пределах.
Когда мы используем пул потоков, мы пишем наш параллельный код в виде параллельных задач и отправляем их на выполнение экземпляру пула потоков. Этот экземпляр управляет несколькими повторно используемыми потоками для выполнения этих задач.
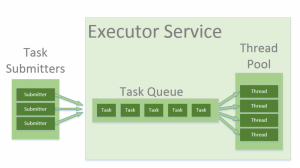
Шаблон позволяет нам контролировать количество потоков, создаваемых приложением, и их жизненный цикл. Мы также можем планировать выполнение задач и держать входящие задачи в очереди.
3. Пулы потоков в Java
3.1. Executors , Executor и ExecutorService
Вспомогательный класс Executors содержит несколько методов для создания предварительно настроенных экземпляров пула потоков. Эти классы - хорошее место для начала. Мы можем использовать их, если нам не нужно применять какую-либо тонкую настройку.
Мы используем интерфейсы Executor и ExecutorService для работы с различными реализациями пула потоков в Java. Обычно мы должны отделять наш код от фактической реализации пула потоков и использовать эти интерфейсы во всем нашем приложении.
3.1.1. Исполнитель
Интерфейс Executor имеет единственный метод execute для отправки экземпляров Runnable на выполнение.
Давайте рассмотрим быстрый пример того, как использовать Executors API для получения экземпляра Executor , поддерживаемого одним пулом потоков и неограниченной очередью для последовательного выполнения задач.
Здесь мы запускаем единственную задачу, которая просто печатает «Hello World » на экране. Мы отправим задачу как лямбда (функция Java 8), которая предполагается как Runnable :
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Hello World"));
3.1.2. ИсполнительСервис
Интерфейс ExecutorService содержит большое количество методов для управления ходом выполнения задач и управления завершением службы. Используя этот интерфейс, мы можем отправлять задачи на выполнение, а также контролировать их выполнение с помощью возвращаемого экземпляра Future .
Теперь мы создадим ExecutorService , отправим задачу, а затем используем возвращенный метод get Future , чтобы дождаться завершения отправленной задачи и возврата значения: ``
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> "Hello World");
// some operations
String result = future.get();
Конечно, в реальном сценарии мы обычно не хотим вызывать future.get() сразу, а откладываем вызов до тех пор, пока нам действительно не понадобится значение вычисления.
Здесь мы перегружаем метод submit , чтобы он принимал Runnable или Callable . Оба они являются функциональными интерфейсами, и мы можем передавать их как лямбды (начиная с Java 8).
Единственный метод Runnable не генерирует исключение и не возвращает значение. Интерфейс Callable может быть более удобным, поскольку он позволяет нам генерировать исключение и возвращать значение.
Наконец, чтобы позволить компилятору определить тип Callable , просто верните значение из лямбда-выражения.
Дополнительные примеры использования интерфейса ExecutorService и фьючерсов см. в A Guide to the Java ExecutorService .
3.2. ThreadPoolExecutor
ThreadPoolExecutor — это расширяемая реализация пула потоков с множеством параметров и ловушек для тонкой настройки.
Основные параметры конфигурации, которые мы здесь обсудим, — это corePoolSize , maxPoolSize и keepAliveTime .
Пул состоит из фиксированного количества основных потоков, которые все время хранятся внутри. Он также состоит из некоторых избыточных потоков, которые могут быть порождены, а затем прекращены, когда они больше не нужны.
Параметр corePoolSize — это количество основных потоков, которые будут созданы и сохранены в пуле. При поступлении новой задачи, если все основные потоки заняты и внутренняя очередь заполнена, пул может увеличиться до maxPoolSize .
Параметр keepAliveTime — это интервал времени, в течение которого избыточные потоки (экземпляры которых превышают corePoolSize ) могут существовать в состоянии простоя. По умолчанию ThreadPoolExecutor рассматривает для удаления только неосновные потоки. Чтобы применить ту же политику удаления к основным потокам, мы можем использовать метод allowCoreThreadTimeOut(true) .
Эти параметры охватывают широкий спектр вариантов использования, но наиболее типичные конфигурации предопределены в статических методах Executors .
3.2.1. новыйFixedThreadPool
Давайте посмотрим на пример. Метод newFixedThreadPool создает ThreadPoolExecutor с одинаковыми значениями параметров corePoolSize и maxPoolSize и нулевым значением keepAliveTime . Это означает, что количество потоков в этом пуле потоков всегда одинаково:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(2);
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(2, executor.getPoolSize());
assertEquals(1, executor.getQueue().size());
Здесь мы создаем экземпляр ThreadPoolExecutor с фиксированным количеством потоков, равным 2. Это означает, что если количество одновременно выполняющихся задач всегда меньше или равно двум, они выполняются сразу. В противном случае некоторые из этих задач могут быть поставлены в очередь для ожидания своей очереди.
Мы создали три задачи Callable , которые имитируют тяжелую работу, засыпая на 1000 миллисекунд. Первые две задачи будут запущены одновременно, а третьей придется ждать в очереди. Мы можем проверить это, вызвав методы getPoolSize() и getQueue().size() сразу после отправки задач.
3.2.2. Executors.newCachedThreadPool()
Мы можем создать еще один предварительно настроенный ThreadPoolExecutor с помощью метода Executors.newCachedThreadPool() . Этот метод вообще не получает количество потоков. Мы устанавливаем для corePoolSize значение 0, а для maxPoolSize — значение Integer. MAX_VALUE. Наконец, keepAliveTime составляет 60 секунд:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newCachedThreadPool();
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(3, executor.getPoolSize());
assertEquals(0, executor.getQueue().size());
Эти значения параметров означают, что пул кэшированных потоков может неограниченно увеличиваться для размещения любого количества отправленных задач. Но когда потоки больше не нужны, они будут утилизированы через 60 секунд бездействия. Типичный случай использования — это когда у нас есть много краткосрочных задач в нашем приложении.
Размер очереди всегда будет равен нулю, поскольку внутри используется экземпляр SynchronousQueue . В SynchronousQueue пары операций вставки и удаления всегда выполняются одновременно. Таким образом, очередь на самом деле никогда ничего не содержит.
3.2.3. Executors.newSingleThreadExecutor()
API Executors.newSingleThreadExecutor() создает еще одну типичную форму ThreadPoolExecutor , содержащую один поток. Однопоточный исполнитель идеально подходит для создания цикла событий. Параметры corePoolSize и maxPoolSize равны 1, а keepAliveTime — 0.
Задачи в приведенном выше примере будут выполняться последовательно, поэтому после завершения задачи значение флага будет равно 2:
AtomicInteger counter = new AtomicInteger();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> {
counter.set(1);
});
executor.submit(() -> {
counter.compareAndSet(1, 2);
});
Кроме того, этот ThreadPoolExecutor украшен неизменяемой оболочкой, поэтому его нельзя перенастроить после создания. Обратите внимание, что это также причина, по которой мы не можем привести его к ThreadPoolExecutor .
3.3. Запланированный поток пула исполнителей
ScheduledThreadPoolExecutor расширяет класс ThreadPoolExecutor , а также реализует интерфейс ScheduledExecutorService с несколькими дополнительными методами:
Метод scheduleпозволяет нам запускать задачу один раз после указанной задержки.Метод scheduleAtFixedRateпозволяет нам запускать задачу после указанной начальной задержки, а затем запускать ее повторно с определенным периодом. Аргументпериода— это время, измеренное между моментами запуска задач , поэтому скорость выполнения является фиксированной.Метод scheduleWithFixedDelayпохож наscheduleAtFixedRateтем, что он многократно запускает заданную задачу, но указанная задержка измеряется между окончанием предыдущей задачи и началом следующей. Скорость выполнения может варьироваться в зависимости от времени, необходимого для выполнения той или иной задачи.
Обычно мы используем метод Executors.newScheduledThreadPool() для создания ScheduledThreadPoolExecutor с заданным corePoolSize , неограниченным maxPoolSize и нулевым keepAliveTime .
Вот как запланировать выполнение задачи через 500 миллисекунд:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.schedule(() -> {
System.out.println("Hello World");
}, 500, TimeUnit.MILLISECONDS);
В следующем коде показано, как запустить задачу после задержки в 500 миллисекунд, а затем повторять ее каждые 100 миллисекунд. После планирования задачи мы ждем, пока она не сработает три раза, используя блокировку CountDownLatch . Затем мы отменяем его с помощью метода Future.cancel() :
CountDownLatch lock = new CountDownLatch(3);
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
ScheduledFuture<?> future = executor.scheduleAtFixedRate(() -> {
System.out.println("Hello World");
lock.countDown();
}, 500, 100, TimeUnit.MILLISECONDS);
lock.await(1000, TimeUnit.MILLISECONDS);
future.cancel(true);
3.4. ForkJoinPool
ForkJoinPool — это центральная часть инфраструктуры fork/join , представленной в Java 7. Она решает распространенную проблему порождения нескольких задач в рекурсивных алгоритмах. Мы быстро исчерпаем потоки, используя простой ThreadPoolExecutor , так как для каждой задачи или подзадачи требуется свой собственный поток.
Во фреймворке fork/join любая задача может порождать ( fork ) несколько подзадач и ждать их завершения, используя метод соединения . Преимущество фреймворка fork/join заключается в том, что он не создает новый поток для каждой задачи или подзадачи , а вместо этого реализует алгоритм кражи работы. Этот фреймворк подробно описан в нашем Руководстве по фреймворку Fork/Join в Java .
Давайте рассмотрим простой пример использования ForkJoinPool для обхода дерева узлов и вычисления суммы всех конечных значений. Вот простая реализация дерева, состоящего из узла, значения int и набора дочерних узлов:
static class TreeNode {
int value;
Set<TreeNode> children;
TreeNode(int value, TreeNode... children) {
this.value = value;
this.children = Sets.newHashSet(children);
}
}
Теперь, если мы хотим суммировать все значения в дереве параллельно, нам нужно реализовать интерфейс RecursiveTask<Integer> . Каждая задача получает свой собственный узел и добавляет его значение к сумме значений своих дочерних элементов . Для вычисления суммы дочерних значений реализация задачи делает следующее:
- транслирует
детскийнабор - сопоставляет этот поток, создавая новую
задачу CountingTaskдля каждого элемента - запускает каждую подзадачу, разветвляя ее
- собирает результаты, вызывая метод
соединениядля каждой разветвленной задачи - суммирует результаты с помощью
коллектораCollectors.summingInt
public static class CountingTask extends RecursiveTask<Integer> {
private final TreeNode node;
public CountingTask(TreeNode node) {
this.node = node;
}
@Override
protected Integer compute() {
return node.value + node.children.stream()
.map(childNode -> new CountingTask(childNode).fork())
.collect(Collectors.summingInt(ForkJoinTask::join));
}
}
Код для запуска вычислений на реальном дереве очень прост:
TreeNode tree = new TreeNode(5,
new TreeNode(3), new TreeNode(2,
new TreeNode(2), new TreeNode(8)));
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
int sum = forkJoinPool.invoke(new CountingTask(tree));
4. Реализация пула потоков в Guava
Guava — это популярная библиотека утилит Google. Он имеет много полезных классов параллелизма, в том числе несколько удобных реализаций ExecutorService . Реализующие классы недоступны для прямого создания экземпляров или создания подклассов, поэтому единственной точкой входа для создания их экземпляров является вспомогательный класс MoreExecutors .
4.1. Добавление гуавы в качестве зависимости от Maven
Мы добавляем следующую зависимость в наш файл pom Maven, чтобы включить библиотеку Guava в наш проект. Найдите последнюю версию библиотеки Guava в центральном репозитории Maven:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
4.2. Прямой исполнитель и служба прямого исполнителя
Иногда мы хотим запустить задачу либо в текущем потоке, либо в пуле потоков, в зависимости от некоторых условий. Мы бы предпочли использовать один интерфейс Executor и просто переключать реализацию. Хотя не так сложно придумать реализацию Executor или ExecutorService , которая запускает задачи в текущем потоке, для этого все равно потребуется написать некоторый шаблонный код.
К счастью, Guava предоставляет нам предопределенные экземпляры.
Вот пример , демонстрирующий выполнение задачи в том же потоке. Хотя предоставленная задача приостанавливается на 500 миллисекунд, она блокирует текущий поток , и результат доступен сразу после завершения вызова execute :
Executor executor = MoreExecutors.directExecutor();
AtomicBoolean executed = new AtomicBoolean();
executor.execute(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
executed.set(true);
});
assertTrue(executed.get());
Экземпляр, возвращаемый методом directExecutor() , на самом деле является статическим синглтоном, поэтому использование этого метода вообще не создает никаких накладных расходов на создание объекта.
Мы должны предпочесть этот метод MoreExecutors.newDirectExecutorService() , потому что этот API создает полноценную реализацию службы-исполнителя при каждом вызове.
4.3. Выход из служб Executor
Другая распространенная проблема — завершение работы виртуальной машины , когда пул потоков все еще выполняет свои задачи. Даже при наличии механизма отмены нет гарантии, что задачи будут вести себя корректно и прекратят свою работу при закрытии службы-исполнителя. Это может привести к зависанию JVM на неопределенный срок, пока задачи продолжают выполнять свою работу.
Чтобы решить эту проблему, Guava представляет семейство сервисов-исполнителей. Они основаны на потоках демона, которые завершаются вместе с JVM.
Эти службы также добавляют перехватчик выключения с помощью метода Runtime.getRuntime().addShutdownHook() и предотвращают завершение работы виртуальной машины в течение настроенного периода времени, прежде чем отказаться от зависших задач.
В следующем примере мы отправляем задачу, содержащую бесконечный цикл, но используем завершающую службу исполнителя с настроенным временем 100 миллисекунд для ожидания задач после завершения работы виртуальной машины.
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(5);
ExecutorService executorService =
MoreExecutors.getExitingExecutorService(executor,
100, TimeUnit.MILLISECONDS);
executorService.submit(() -> {
while (true) {
}
});
Без exitingExecutorService эта задача приведет к зависанию виртуальной машины на неопределенный срок.
4.4. Слушающие декораторы
Декораторы прослушивания позволяют нам обернуть ExecutorService и получать экземпляры ListenableFuture при отправке задачи вместо простых экземпляров Future . Интерфейс ListenableFuture расширяет Future и имеет один дополнительный метод addListener . Этот метод позволяет добавить прослушиватель, который вызывается после завершения в будущем.
Мы редко будем использовать метод ListenableFuture.addListener() напрямую. Но это важно для большинства вспомогательных методов служебного класса Futures .
Например, с помощью метода Futures.allAsList() мы можем объединить несколько экземпляров ListenableFuture в один ListenableFuture , который завершается после успешного завершения всех объединенных фьючерсов:
ExecutorService executorService = Executors.newCachedThreadPool();
ListeningExecutorService listeningExecutorService =
MoreExecutors.listeningDecorator(executorService);
ListenableFuture<String> future1 =
listeningExecutorService.submit(() -> "Hello");
ListenableFuture<String> future2 =
listeningExecutorService.submit(() -> "World");
String greeting = Futures.allAsList(future1, future2).get()
.stream()
.collect(Collectors.joining(" "));
assertEquals("Hello World", greeting);
5. Вывод
В этой статье мы обсудили шаблон пула потоков и его реализации в стандартной библиотеке Java и в библиотеке Google Guava.
Исходный код статьи доступен на GitHub .