1. Обзор
В этом кратком руководстве мы рассмотрим, как отправлять данные JMX с нашего сервера Tomcat в Elastic Stack (ранее известный как ELK).
Мы обсудим, как настроить Logstash для чтения данных из JMX и отправки их в Elasticsearch.
2. Установите эластичный стек
Во-первых, нам нужно установить стек Elastic ( Elasticsearch — Logstash — Kibana )
Затем, чтобы убедиться, что все подключено и работает правильно, мы отправим данные JMX в Logstash и визуализируем их в Kibana.
2.1. Тестовый Логсташ
Сначала мы перейдем в каталог установки Logstash, который зависит от операционной системы (в нашем случае Ubuntu):
cd /opt/logstash
Мы можем установить простую конфигурацию для Logstash из командной строки:
bin/logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["localhost:9200"] } }'
Затем мы можем просто ввести некоторые образцы данных в консоль и использовать команду CTRL-D, чтобы закрыть конвейер, когда мы закончим.
2.2. Протестировать Elasticsearch
После добавления демонстрационных данных в Elasticsearch должен быть доступен индекс Logstash, который мы можем проверить следующим образом:
curl -X GET 'http://localhost:9200/_cat/indices'
Пример вывода:
yellow open logstash-2017.11.10 5 1 3531 0 506.3kb 506.3kb
yellow open .kibana 1 1 3 0 9.5kb 9.5kb
yellow open logstash-2017.11.11 5 1 8671 0 1.4mb 1.4mb
2.3. Тест Кибана
Kibana по умолчанию работает на порту 5601 — мы можем получить доступ к домашней странице по адресу:
http://localhost:5601/app/kibana
У нас должна быть возможность создать новый индекс с шаблоном « logstash-* » — и увидеть там наши образцы данных.
3. Настройте Tomcat
Далее нам нужно включить JMX, добавив в CATALINA_OPTS следующее :
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=9000
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
Обратите внимание, что:
- Вы можете настроить
CATALINA_OPTS, изменивsetenv.sh - Для пользователей Ubuntu
setenv.shможно найти в «/usr/share/tomcat8/bin».
4. Подключите JMX и Logstash
Теперь давайте подключим наши метрики JMX к Logstash, для чего нам понадобится установленный плагин ввода JMX (подробнее об этом позже).
4.1. Настройка метрик JMX
Во-первых, нам нужно настроить метрики JMX, которые мы хотим сохранить; мы предоставим конфигурацию в формате JSON.
Вот наш jmx_config.json :
{
"host" : "localhost",
"port" : 9000,
"alias" : "reddit.jmx.elasticsearch",
"queries" : [
{
"object_name" : "java.lang:type=Memory",
"object_alias" : "Memory"
}, {
"object_name" : "java.lang:type=Threading",
"object_alias" : "Threading"
}, {
"object_name" : "java.lang:type=Runtime",
"attributes" : [ "Uptime", "StartTime" ],
"object_alias" : "Runtime"
}]
}
Обратите внимание, что:
- Мы использовали тот же порт для JMX от
CATALINA_OPTS. - Мы можем предоставить столько файлов конфигурации, сколько захотим, но нам нужно, чтобы они находились в одном каталоге (в нашем случае мы сохранили
jmx_config.jsonв '/monitor/jmx/')
4.2. Плагин ввода JMX
Затем давайте установим плагин ввода JMX, выполнив следующую команду в каталоге установки Logstash:
bin/logstash-plugin install logstash-input-jmx
Затем нам нужно создать файл конфигурации Logstash ( jmx.conf ), где входными данными являются метрики JMX, а выходные данные направляются в Elasticsearch:
input {
jmx {
path => "/monitor/jmx"
polling_frequency => 60
type => "jmx"
nb_thread => 3
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
Наконец, нам нужно запустить Logstash и указать наш файл конфигурации:
bin/logstash -f jmx.conf
Обратите внимание, что наш файл конфигурации Logstash jmx.conf сохраняется в домашнем каталоге Logstash (в нашем случае /opt/logstash )
5. Визуализируйте метрики JMX
Наконец, давайте создадим простую визуализацию данных наших метрик JMX на Kibana. Мы создадим простую диаграмму — для мониторинга использования динамической памяти.
5.1. Создать новый поиск
Во-первых, мы создадим новый поиск, чтобы получить метрики, связанные с использованием памяти кучи:
- Нажмите на значок «Новый поиск» в строке поиска.
- Введите следующий запрос
metric_path:reddit.jmx.elasticsearch.Memory.HeapMemoryUsage.used
- нажмите Ввод
- Обязательно добавьте поля «
metric_path» и «metric_value_number» с боковой панели. - Нажмите на значок «Сохранить поиск» в строке поиска.
- Назовите поиск «используемая память».
Если какие-либо поля на боковой панели помечены как неиндексированные, перейдите на вкладку «Настройки» и обновите список полей в индексе « logstash-* ».
5.2. Создать линейную диаграмму
Далее мы создадим простую линейную диаграмму для отслеживания использования памяти кучи с течением времени:
- Перейти на вкладку «Визуализация»
- Выберите «Линейная диаграмма»
- Выберите «Из сохраненного поиска».
- Выберите поиск «использованная память», который мы создали ранее
Для оси Y обязательно выберите:
- Агрегация: Средняя
- Поле:
metric_value_number
Для оси X выберите «Гистограмма даты» — затем сохраните визуализацию.
5.3. Использовать поле сценария
Поскольку использование памяти указано в байтах, это не очень удобно для чтения. Мы можем преобразовать тип и значение метрики, добавив скриптовое поле в Kibana:
- В «Настройках» перейдите к индексам и выберите индекс «
logstash- *». - Перейдите на вкладку «Заскриптованные поля» и нажмите «Добавить заскриптованное поле».
- Название:
metric_value_formatted - Формат: байты
- Для скрипта мы будем просто использовать значение
metric_value_number:
doc['metric_value_number'].value
Теперь вы можете изменить свой поиск и визуализацию, чтобы использовать поле « metric_value_formatted » вместо « metric_value_number » — и данные будут отображаться правильно.
Вот как выглядит эта очень простая панель инструментов:
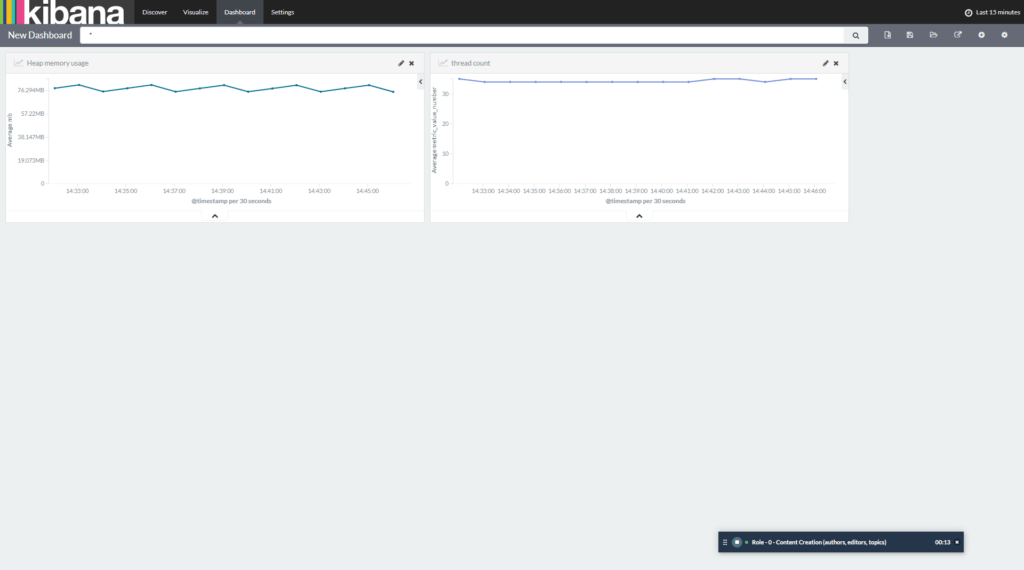
6. Заключение
И мы закончили. Как видите, конфигурация не особенно сложна, и видимость данных JMX в Kibana позволяет нам проделать много интересной работы по визуализации, чтобы создать фантастическую панель мониторинга производства.