1. Обзор
Распределение данных и моделирование данных в базе данных Cassandra NoSQL отличаются от традиционных реляционных баз данных.
В этой статье мы узнаем, как ключ раздела, составной ключ и ключ кластеризации образуют первичный ключ. Мы также увидим, чем они отличаются. В результате мы коснемся архитектуры распределения данных и темы моделирования данных в Cassandra.
2. Архитектура Apache Cassandra
Apache Cassandra — это распределенная база данных NoSQL с открытым исходным кодом, созданная для обеспечения высокой доступности и линейной масштабируемости без ущерба для производительности.
Вот схема архитектуры высокого уровня Cassandra :
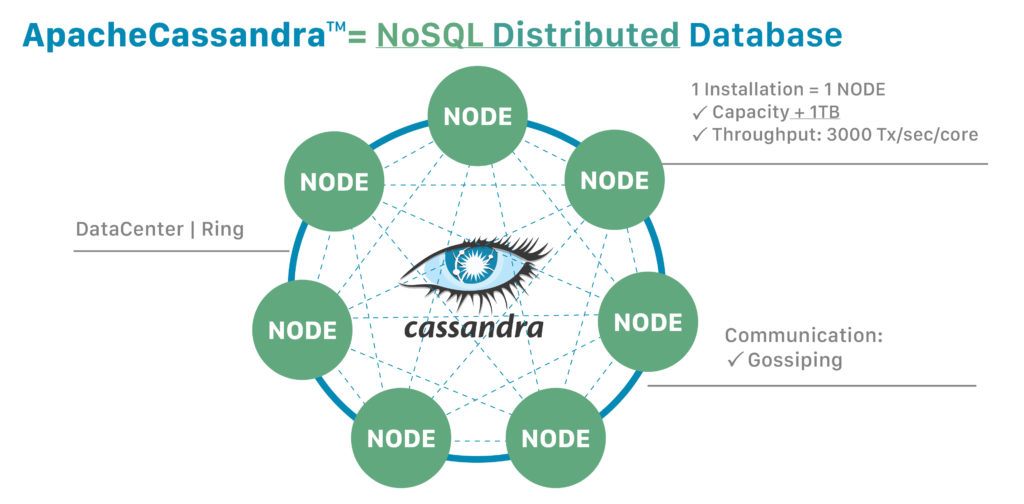
В Cassandra данные распределяются по кластеру. Кроме того, кластер может состоять из кольца узлов, расположенных в стойках, установленных в центрах обработки данных в разных географических регионах.
На более детальном уровне виртуальные узлы, известные как виртуальные узлы, назначают право собственности на данные физической машине. Vnodes позволяют каждому узлу владеть несколькими небольшими диапазонами разделов, используя технику, называемую согласованным хешированием , для распределения данных.
Разделитель — это функция, которая хэширует ключ раздела для создания токена. Это значение токена представляет строку и используется для идентификации диапазона секций, которому она принадлежит в узле.
Однако клиент Cassandra видит кластер как единую базу данных и взаимодействует с ней с помощью библиотеки драйверов Cassandra.
3. Моделирование данных Кассандры
Как правило, моделирование данных — это процесс анализа требований к приложению, определения сущностей и их взаимосвязей, организации данных и т. д. В реляционном моделировании данных запросы часто отходят на второй план во всем процессе моделирования данных.
Однако в Cassandra запросы на доступ к данным управляют моделированием данных . Запросы, в свою очередь, управляются рабочими процессами приложения.
Кроме того, в моделях данных Cassandra нет соединений таблиц, что означает, что все нужные данные в запросе должны поступать из одной таблицы. В результате данные в таблице имеют денормализованный формат.
Затем, на этапе логического моделирования данных, мы указываем фактическую схему базы данных, определяя пространства ключей, таблицы и даже столбцы таблиц . Затем, на этапе моделирования физических данных, мы используем язык запросов Cassandra (CQL) для создания физических пространств ключей — таблиц со всеми типами данных в кластере.
4. Первичный ключ
То, как первичные ключи работают в Cassandra, является важной концепцией для понимания.
Первичный ключ в Cassandra состоит из одного или нескольких ключей разделов и нуля или нескольких компонентов ключей кластеризации . Порядок этих компонентов всегда ставит сначала ключ раздела, а затем ключ кластеризации.
Помимо уникальности данных, ключевой компонент первичного ключа играет дополнительную важную роль в размещении данных. В результате повышается производительность операций чтения и записи данных, распределенных по нескольким узлам в кластере.
Теперь давайте рассмотрим каждый из этих компонентов первичного ключа.
4.1. Ключ раздела
Основная цель ключа секции — равномерно распределить данные по кластеру и эффективно запрашивать данные.
Ключ секции предназначен для размещения данных, помимо уникальной идентификации данных, и всегда является первым значением в определении первичного ключа.
Попробуем разобраться на примере — простая таблица, содержащая логи приложений с одним первичным ключом:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY (app_name)
);
Вот некоторые примеры данных в приведенной выше таблице:

Как мы узнали ранее, Cassandra использует согласованный метод хеширования для генерации хеш-значения ключа раздела ( app_name ) и присвоения данных строки диапазону раздела внутри узла.
Давайте посмотрим на возможное хранение данных:

На приведенной выше диаграмме показан возможный сценарий, в котором хеш-значения app1 , app2 и app3 приводят к тому, что каждая строка хранится в трех разных узлах — Node1 , Node2 и Node3 соответственно.
Все журналы app1 отправляются на Node1 , журналы app2 — на Node2 , а журналы app3 — на Node3 .
Запрос на выборку данных без ключа секции в предложении where приводит к неэффективному полному сканированию кластера.
С другой стороны, с ключом раздела в предложении where Cassandra использует метод согласованного хеширования для идентификации точного узла и точного диапазона раздела внутри узла в кластере. В результате запрос выборки данных выполняется быстро и эффективно:
select * application_logs where app_name = 'app1';
4.2. Составной ключ раздела
Если нам нужно объединить несколько значений столбца для формирования одного ключа секции, мы используем составной ключ секции.
Здесь снова целью составного ключа секции является размещение данных в дополнение к уникальной идентификации данных. В результате хранение и поиск данных становятся эффективными.
Вот пример определения таблицы, в котором столбцы app_name и env объединены для формирования составного ключа раздела:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env))
);
В приведенном выше определении важно отметить внутреннюю скобку вокруг app_name и определения первичного ключа env . Эта внутренняя скобка указывает, что app_name и env являются частью ключа раздела и не являются ключами кластеризации.
Если мы опустим внутреннюю скобку и оставим только одну скобку, тогда app_name станет ключом раздела, а env станет компонентом ключа кластеризации .
Вот пример данных для приведенной выше таблицы:

Давайте посмотрим на возможное распределение данных приведенного выше примера данных. Обратите внимание: Cassandra генерирует хеш-значение для комбинации столбцов app_name и env :

Как мы видим выше, возможный сценарий, в котором хэш-значение app1:prod, app1:dev, app1:qa приводит к тому, что эти три строки хранятся в трех отдельных узлах — Node1 , Node2 и Node3 соответственно.
Все журналы app1 из среды prod отправляются на Node1 , а журналы app1 из среды dev — на Node2 , а журналы app1 из среды qa — на Node3 .
Самое главное, чтобы эффективно извлекать данные, предложение where в запросе на выборку должно содержать все ключи составного раздела в том же порядке, что и в определении первичного ключа :
select * application_logs where app_name = 'app1' and env = 'prod';
4.3. Ключ кластеризации
Как мы упоминали выше, секционирование — это процесс определения диапазона секций внутри узла, в который помещаются данные. Напротив, кластеризация — это процесс механизма хранения для сортировки данных в разделе, основанный на столбцах, определенных как ключи кластеризации .
Более того, идентификация ключевых столбцов кластеризации должна быть выполнена заранее — это потому, что наш выбор ключевых столбцов кластеризации зависит от того, как мы хотим использовать данные в нашем приложении.
Все данные в разделе хранятся в непрерывном хранилище, отсортированном по ключевым столбцам кластеризации. В результате извлечение нужных отсортированных данных очень эффективно.
Давайте посмотрим на пример определения таблицы, в котором есть ключи кластеризации вместе с ключами составного раздела:
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name, env), hostname, log_datetime)
);
И давайте посмотрим некоторые примеры данных:

Как видно из приведенного выше определения таблицы, мы включили имя хоста и log_datetime в качестве ключевых столбцов кластеризации. Предполагая, что все журналы из среды app1 и prod хранятся в Node1 , механизм хранения Cassandra лексически сортирует эти журналы по имени хоста и log_datetime в разделе.
По умолчанию механизм хранения Cassandra сортирует данные в порядке возрастания ключевых столбцов кластеризации, но мы можем управлять порядком сортировки столбцов кластеризации, используя предложение WITH CLUSTERING ORDER BY в определении таблицы :
CREATE TABLE application_logs (
id INT,
app_name VARCHAR,
hostname VARCHAR,
log_datetime TIMESTAMP,
env VARCHAR,
log_level VARCHAR,
log_message TEXT,
PRIMARY KEY ((app_name,env), hostname, log_datetime)
)
WITH CLUSTERING ORDER BY (hostname ASC, log_datetime DESC);
В соответствии с приведенным выше определением, внутри раздела механизм хранения Cassandra будет хранить все журналы в порядке лексического возрастания имени хоста , но в порядке убывания log_datetime в каждой группе имен хостов .
Теперь давайте рассмотрим пример запроса на выборку данных с кластеризацией столбцов в предложении where :
select * application_logs
where
app_name = 'app1' and env = 'prod'
and hostname = 'host1' and log_datetime > '2021-08-13T00:00:00';
Здесь важно отметить, что предложение where должно содержать столбцы в том же порядке, что и в предложении первичного ключа.
5. Вывод
В этой статье мы узнали, что Cassandra использует ключ секции или составной ключ секции для определения размещения данных в кластере. Ключ кластеризации обеспечивает порядок сортировки данных, хранящихся в разделе. Все эти ключи также однозначно идентифицируют данные.
Мы также затронули тему архитектуры Cassandra и моделирования данных.
Для получения дополнительной информации о Cassandra посетите документацию DataStax и Apache Cassandra .