1. Введение
В этом руководстве мы рассмотрим основные концепции разделения ответственности командных запросов (CQRS) и шаблонов проектирования Event Sourcing.
Хотя шаблоны часто называют взаимодополняющими, мы попытаемся понять их по отдельности и, наконец, посмотрим, как они дополняют друг друга. Существует несколько инструментов и фреймворков, таких как Axon , которые помогают использовать эти шаблоны, но мы создадим простое приложение на Java, чтобы понять основы.
2. Основные понятия
Сначала мы поймем эти шаблоны теоретически, прежде чем пытаться их реализовать. Кроме того, поскольку они достаточно хорошо представляют собой отдельные паттерны, мы постараемся понять их, не смешивая их.
Обратите внимание, что эти шаблоны часто используются вместе в корпоративном приложении. В этом отношении они также выигрывают от нескольких других шаблонов архитектуры предприятия. Мы обсудим некоторые из них по ходу дела.
2.1. Поиск событий
Event Sourcing дает нам новый способ сохранения состояния приложения в виде упорядоченной последовательности событий . Мы можем выборочно запрашивать эти события и реконструировать состояние приложения в любой момент времени. Конечно, чтобы это работало, нам нужно перерисовывать каждое изменение состояния приложения как событие:
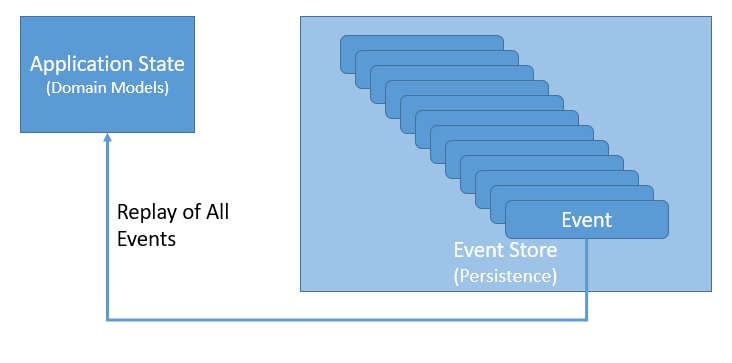
Эти события здесь являются фактами, которые произошли и не могут быть изменены — другими словами, они должны быть неизменными. Воссоздание состояния приложения — это просто воспроизведение всех событий.
Обратите внимание, что это также открывает возможность выборочного воспроизведения событий, воспроизведения некоторых событий в обратном порядке и многого другого. Как следствие, мы можем рассматривать само состояние приложения как второстепенного гражданина, а журнал событий — как наш основной источник правды.
2.2. CQRS
Проще говоря, CQRS предназначен для разделения команд и запросов в архитектуре приложения . CQRS основан на принципе разделения команд и запросов (CQS), предложенном Бертраном Мейером. CQS предлагает разделить операции над объектами домена на две отдельные категории: запросы и команды:
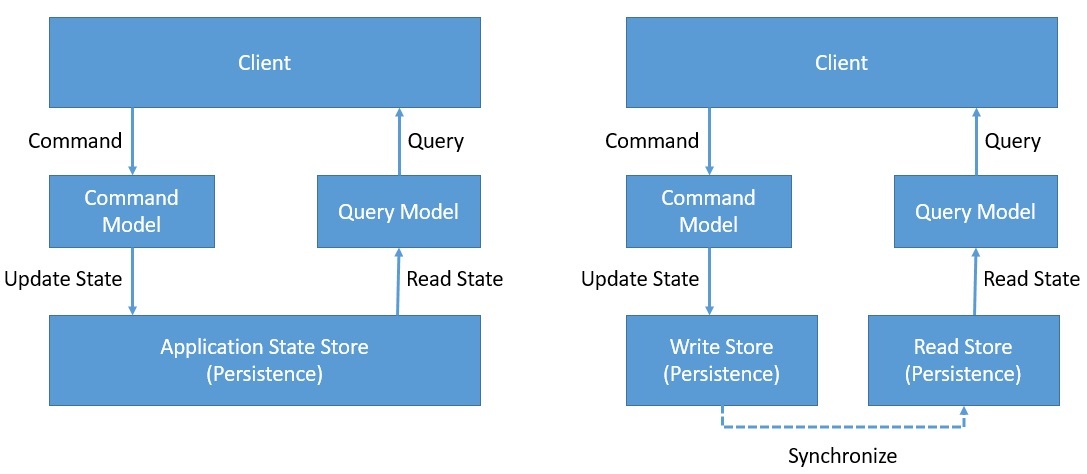
Запросы возвращают результат и не изменяют наблюдаемое состояние системы. Команды изменяют состояние системы, но не обязательно возвращают значение .
Мы достигаем этого за счет четкого разделения команд и запросов в модели предметной области. Мы можем сделать еще один шаг вперед, разделив хранилище данных на сторону записи и чтения, конечно же, внедрив механизм для их синхронизации.
3. Простое приложение
Мы начнем с описания простого приложения на Java, которое строит модель предметной области.
Приложение будет предлагать операции CRUD для модели предметной области, а также будет обеспечивать постоянство для объектов предметной области. CRUD означает создание, чтение, обновление и удаление, которые являются основными операциями, которые мы можем выполнять с объектом домена.
Мы будем использовать это же приложение для представления Event Sourcing и CQRS в следующих разделах.
При этом в нашем примере мы будем использовать некоторые концепции доменно-ориентированного проектирования (DDD) .
DDD предназначен для анализа и проектирования программного обеспечения, основанного на комплексных знаниях предметной области . Он основан на идее, что программные системы должны основываться на хорошо разработанной модели предметной области. DDD был впервые предложен Эриком Эвансом как каталог шаблонов. Мы будем использовать некоторые из этих шаблонов для построения нашего примера.
3.1. Обзор приложения
Создание профиля пользователя и управление им является типичным требованием во многих приложениях. Мы определим простую модель предметной области, фиксирующую профиль пользователя вместе с постоянством:
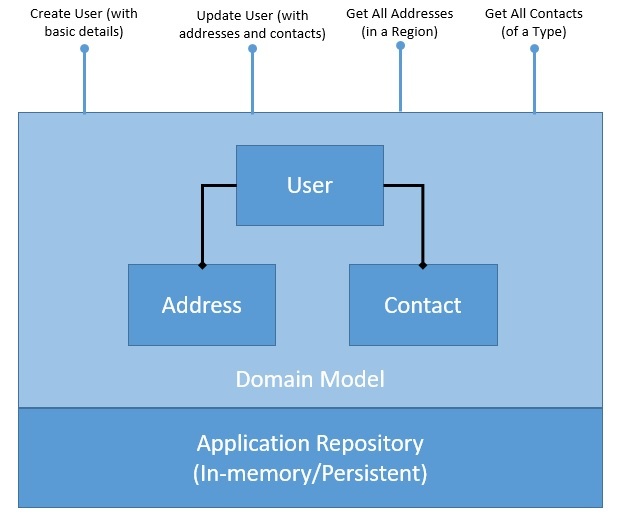
Как мы видим, наша модель предметной области нормализована и предоставляет несколько операций CRUD. Эти операции предназначены только для демонстрации и могут быть простыми или сложными в зависимости от требований . Более того, репозиторий персистентности здесь может быть в памяти или вместо этого использовать базу данных.
3.2. Реализация приложения
Во-первых, нам нужно создать классы Java, представляющие нашу модель предметной области. Это довольно простая модель предметной области, и она может даже не требовать сложности шаблонов проектирования, таких как Event Sourcing и CQRS. Тем не менее, мы сохраним это простым, чтобы сосредоточиться на понимании основ:
public class User {
private String userid;
private String firstName;
private String lastName;
private Set<Contact> contacts;
private Set<Address> addresses;
// getters and setters
}
public class Contact {
private String type;
private String detail;
// getters and setters
}
public class Address {
private String city;
private String state;
private String postcode;
// getters and setters
}
Кроме того, мы определим простой репозиторий в памяти для сохранения состояния нашего приложения. Конечно, это не добавляет никакой ценности, но достаточно для нашей демонстрации позже:
public class UserRepository {
private Map<String, User> store = new HashMap<>();
}
Теперь мы определим службу для предоставления типичных операций CRUD в нашей модели предметной области:
public class UserService {
private UserRepository repository;
public UserService(UserRepository repository) {
this.repository = repository;
}
public void createUser(String userId, String firstName, String lastName) {
User user = new User(userId, firstName, lastName);
repository.addUser(userId, user);
}
public void updateUser(String userId, Set<Contact> contacts, Set<Address> addresses) {
User user = repository.getUser(userId);
user.setContacts(contacts);
user.setAddresses(addresses);
repository.addUser(userId, user);
}
public Set<Contact> getContactByType(String userId, String contactType) {
User user = repository.getUser(userId);
Set<Contact> contacts = user.getContacts();
return contacts.stream()
.filter(c -> c.getType().equals(contactType))
.collect(Collectors.toSet());
}
public Set<Address> getAddressByRegion(String userId, String state) {
User user = repository.getUser(userId);
Set<Address> addresses = user.getAddresses();
return addresses.stream()
.filter(a -> a.getState().equals(state))
.collect(Collectors.toSet());
}
}
Это в значительной степени то, что нам нужно сделать, чтобы настроить наше простое приложение. Это далеко не готовый к производству код, но он раскрывает некоторые важные моменты , которые мы собираемся обсудить позже в этом руководстве.
3.3. Проблемы в этом приложении
Прежде чем мы продолжим обсуждение источников событий и CQRS, стоит обсудить проблемы с текущим решением. В конце концов, мы будем решать одни и те же проблемы, применяя эти шаблоны!
Из многих проблем, которые мы можем здесь заметить, мы просто хотели бы сосредоточиться на двух из них:
Модель домена: операции чтения и записи выполняются в одной и той же модели домена. Хотя это не проблема для такой простой модели предметной области, она может ухудшиться по мере усложнения модели предметной области. Возможно, нам потребуется оптимизировать нашу модель предметной области и базовое хранилище для них, чтобы они соответствовали индивидуальным потребностям операций чтения и записи.Постоянство: сохраняемость, которую мы имеем для наших объектов предметной области, хранит только последнее состояние модели предметной области. Хотя этого достаточно для большинства ситуаций, это усложняет некоторые задачи. Например, если нам нужно выполнить исторический аудит того, как объект предметной области изменил состояние, здесь это невозможно . Для этого нам нужно дополнить наше решение некоторыми журналами аудита.
4. Знакомство с CQRS
Мы начнем решать первую проблему, которую обсуждали в предыдущем разделе, с введения шаблона CQRS в наше приложение. В рамках этого мы разделим модель предметной области и ее постоянство для обработки операций записи и чтения . Давайте посмотрим, как шаблон CQRS реструктурирует наше приложение:
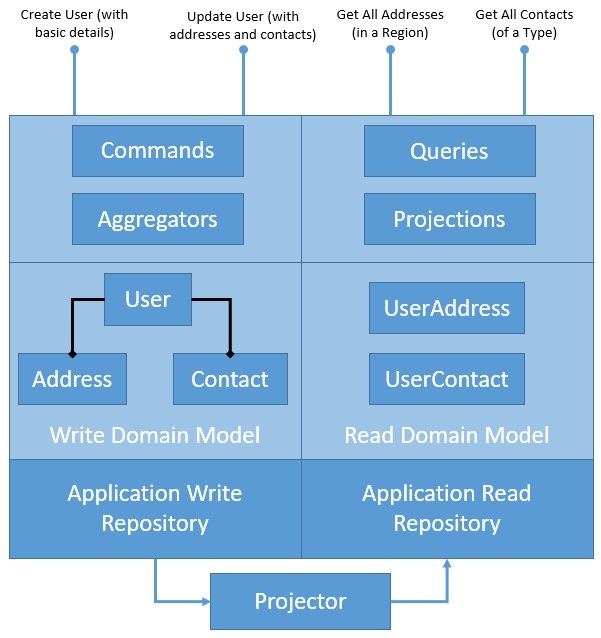
На приведенной здесь диаграмме показано, как мы намерены четко разделить архитектуру нашего приложения на стороны записи и чтения. Тем не менее, мы ввели здесь довольно много новых компонентов, которые мы должны лучше понять. Обратите внимание, что они не имеют строгого отношения к CQRS, но CQRS извлекают из них большую пользу:
Агрегат/Агрегатор:
Агрегат — это шаблон, описанный в доменно-управляемом проектировании (DDD), который логически группирует различные сущности, связывая сущности с корнем агрегата . Совокупный шаблон обеспечивает согласованность транзакций между сущностями.
CQRS естественным образом выигрывает от агрегированного шаблона, который группирует модель домена записи, обеспечивая транзакционные гарантии. Агрегаты обычно хранят кэшированное состояние для повышения производительности, но могут прекрасно работать и без него.
Проекция/проектор:
Проекция — еще один важный паттерн, который приносит большую пользу CQRS. Проекция по существу означает представление объектов предметной области в различных формах и структурах .
Эти проекции исходных данных доступны только для чтения и оптимизированы для обеспечения расширенных возможностей чтения. Мы можем снова решить кэшировать проекции для повышения производительности, но это не обязательно.
4.1. Реализация стороны записи приложения
Давайте сначала реализуем сторону записи приложения.
Мы начнем с определения необходимых команд. Команда — это намерение изменить состояние модели предметной области . Удастся это или нет, зависит от бизнес-правил, которые мы настроим.
Давайте посмотрим наши команды:
public class CreateUserCommand {
private String userId;
private String firstName;
private String lastName;
}
public class UpdateUserCommand {
private String userId;
private Set<Address> addresses;
private Set<Contact> contacts;
}
Это довольно простые классы, которые содержат данные, которые мы собираемся изменить.
Затем мы определяем агрегат, отвечающий за получение команд и их обработку. Агрегаты могут принять или отклонить команду:
public class UserAggregate {
private UserWriteRepository writeRepository;
public UserAggregate(UserWriteRepository repository) {
this.writeRepository = repository;
}
public User handleCreateUserCommand(CreateUserCommand command) {
User user = new User(command.getUserId(), command.getFirstName(), command.getLastName());
writeRepository.addUser(user.getUserid(), user);
return user;
}
public User handleUpdateUserCommand(UpdateUserCommand command) {
User user = writeRepository.getUser(command.getUserId());
user.setAddresses(command.getAddresses());
user.setContacts(command.getContacts());
writeRepository.addUser(user.getUserid(), user);
return user;
}
}
Агрегат использует репозиторий для получения текущего состояния и сохранения любых изменений в нем. Более того, он может сохранять текущее состояние локально, чтобы избежать затрат на обращение в репозиторий туда и обратно при обработке каждой команды.
Наконец, нам нужен репозиторий для хранения состояния модели предметной области. Обычно это база данных или другое долговременное хранилище, но здесь мы просто заменим их структурой данных в памяти:
public class UserWriteRepository {
private Map<String, User> store = new HashMap<>();
// accessors and mutators
}
На этом завершается сторона записи нашего приложения.
4.2. Реализация стороны чтения приложения
Давайте теперь переключимся на сторону чтения приложения. Мы начнем с определения стороны чтения модели предметной области:
public class UserAddress {
private Map<String, Set<Address>> addressByRegion = new HashMap<>();
}
public class UserContact {
private Map<String, Set<Contact>> contactByType = new HashMap<>();
}
Если мы вспомним наши операции чтения, нетрудно увидеть, что эти классы идеально подходят для их обработки. В этом прелесть создания модели предметной области, основанной на имеющихся у нас запросах.
Далее мы определим репозиторий для чтения. Опять же, мы просто будем использовать структуру данных в памяти, хотя это будет более надежное хранилище данных в реальных приложениях:
public class UserReadRepository {
private Map<String, UserAddress> userAddress = new HashMap<>();
private Map<String, UserContact> userContact = new HashMap<>();
// accessors and mutators
}
Теперь мы определим необходимые запросы, которые мы должны поддерживать. Запрос — это намерение получить данные — он не обязательно может привести к данным.
Давайте посмотрим наши запросы:
public class ContactByTypeQuery {
private String userId;
private String contactType;
}
public class AddressByRegionQuery {
private String userId;
private String state;
}
Опять же, это простые классы Java, содержащие данные для определения запроса.
Теперь нам нужна проекция, которая может обрабатывать эти запросы:
public class UserProjection {
private UserReadRepository readRepository;
public UserProjection(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public Set<Contact> handle(ContactByTypeQuery query) {
UserContact userContact = readRepository.getUserContact(query.getUserId());
return userContact.getContactByType()
.get(query.getContactType());
}
public Set<Address> handle(AddressByRegionQuery query) {
UserAddress userAddress = readRepository.getUserAddress(query.getUserId());
return userAddress.getAddressByRegion()
.get(query.getState());
}
}
Проекция здесь использует репозиторий чтения, который мы определили ранее, для обработки запросов, которые у нас есть. Это в значительной степени завершает чтение нашего приложения.
4.3. Синхронизация чтения и записи данных
Одна часть этой головоломки до сих пор не решена: нет ничего, что синхронизировало бы наши репозитории записи и чтения .
Здесь нам понадобится нечто, известное как проектор. У проектора есть логика для проецирования модели домена записи в модель домена чтения .
Есть гораздо более сложные способы справиться с этим, но мы будем делать это относительно просто:
public class UserProjector {
UserReadRepository readRepository = new UserReadRepository();
public UserProjector(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public void project(User user) {
UserContact userContact = Optional.ofNullable(
readRepository.getUserContact(user.getUserid()))
.orElse(new UserContact());
Map<String, Set<Contact>> contactByType = new HashMap<>();
for (Contact contact : user.getContacts()) {
Set<Contact> contacts = Optional.ofNullable(
contactByType.get(contact.getType()))
.orElse(new HashSet<>());
contacts.add(contact);
contactByType.put(contact.getType(), contacts);
}
userContact.setContactByType(contactByType);
readRepository.addUserContact(user.getUserid(), userContact);
UserAddress userAddress = Optional.ofNullable(
readRepository.getUserAddress(user.getUserid()))
.orElse(new UserAddress());
Map<String, Set<Address>> addressByRegion = new HashMap<>();
for (Address address : user.getAddresses()) {
Set<Address> addresses = Optional.ofNullable(
addressByRegion.get(address.getState()))
.orElse(new HashSet<>());
addresses.add(address);
addressByRegion.put(address.getState(), addresses);
}
userAddress.setAddressByRegion(addressByRegion);
readRepository.addUserAddress(user.getUserid(), userAddress);
}
}
Это довольно грубый способ сделать это, но он дает нам достаточно информации о том, что необходимо для работы CQRS. Более того, нет необходимости размещать репозитории для чтения и записи в разных физических хранилищах. Распределенная система имеет свою долю проблем!
Обратите внимание, что неудобно проецировать текущее состояние домена записи на разные модели домена чтения . Пример, который мы здесь взяли, довольно прост, поэтому мы не видим проблемы.
Однако по мере того, как модели записи и чтения становятся все более сложными, проектировать будет все труднее. Мы можем решить эту проблему с помощью проекции на основе событий вместо проекции на основе состояния с помощью Event Sourcing. Мы увидим, как этого добиться позже в этом уроке.
4.4. Преимущества и недостатки CQRS
Мы обсудили шаблон CQRS и узнали, как внедрить его в типичное приложение. Мы категорически пытались решить проблему, связанную с жесткостью модели предметной области при обработке как чтения, так и записи.
Давайте теперь обсудим некоторые другие преимущества, которые CQRS привносит в архитектуру приложения:
- CQRS предоставляет нам удобный способ выбора отдельных моделей предметной области, подходящих для операций записи и чтения; нам не нужно создавать сложную модель предметной области, поддерживающую оба
- Это помогает нам выбирать репозитории, которые индивидуально подходят для обработки сложных операций чтения и записи, таких как высокая пропускная способность для записи и низкая задержка для чтения.
- Он естественным образом дополняет модели программирования на основе событий в распределенной архитектуре, обеспечивая разделение задач, а также более простые модели предметной области.
Однако это не приходит бесплатно. Как видно из этого простого примера, CQRS существенно усложняет архитектуру. Это может не подходить или не стоит боли во многих сценариях:
- Только сложная модель предметной области может извлечь выгоду из дополнительной сложности этого шаблона; простая модель предметной области может обойтись без всего этого
- Естественно , в некоторой степени приводит к дублированию кода , что является приемлемым злом по сравнению с выгодой, к которой оно нас приводит; однако рекомендуется индивидуальное суждение
- Отдельные репозитории приводят к проблемам непротиворечивости , и трудно всегда поддерживать идеальную синхронизацию репозиториев для записи и чтения; нам часто приходится довольствоваться конечной последовательностью
5. Знакомство с источниками событий
Далее мы рассмотрим вторую проблему, которую мы обсуждали в нашем простом приложении. Если мы помним, это было связано с нашим постоянным хранилищем.
Мы представим Event Sourcing для решения этой проблемы. Event Sourcing кардинально меняет наши представления о хранилище состояний приложений .
Посмотрим, как это изменит наш репозиторий:
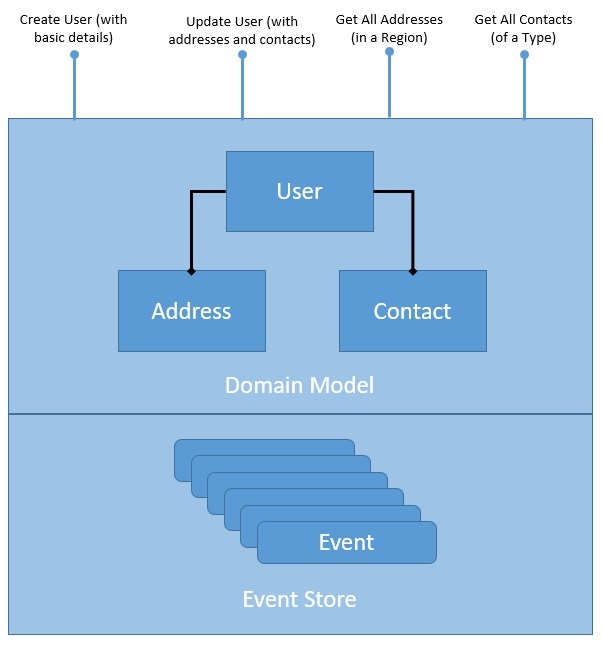
Здесь мы структурировали наш репозиторий для хранения упорядоченного списка событий предметной области . Каждое изменение объекта домена считается событием. Насколько крупным или детальным должно быть событие, зависит от дизайна предметной области. Здесь важно учитывать, что события имеют временной порядок и неизменны.
5.1. Реализация событий и хранилища событий
Основными объектами в приложениях, управляемых событиями, являются события, и источник событий ничем не отличается. Как мы видели ранее, события представляют собой конкретное изменение состояния модели предметной области в определенный момент времени . Итак, мы начнем с определения базового события для нашего простого приложения:
public abstract class Event {
public final UUID id = UUID.randomUUID();
public final Date created = new Date();
}
Это просто гарантирует, что каждое событие, которое мы генерируем в нашем приложении, получает уникальную идентификацию и отметку времени создания. Это необходимо для их дальнейшей обработки.
Конечно, может быть несколько других атрибутов, которые могут нас заинтересовать, например, атрибут для установления происхождения события.
Далее, давайте создадим некоторые специфичные для предметной области события, наследующие это базовое событие:
public class UserCreatedEvent extends Event {
private String userId;
private String firstName;
private String lastName;
}
public class UserContactAddedEvent extends Event {
private String contactType;
private String contactDetails;
}
public class UserContactRemovedEvent extends Event {
private String contactType;
private String contactDetails;
}
public class UserAddressAddedEvent extends Event {
private String city;
private String state;
private String postCode;
}
public class UserAddressRemovedEvent extends Event {
private String city;
private String state;
private String postCode;
}
Это простые POJO на Java, содержащие детали события предметной области. Однако здесь важно отметить детализацию событий.
Мы могли бы создать одно событие для обновлений пользователей, но вместо этого решили создать отдельные события для добавления и удаления адреса и контакта. Выбор сопоставляется с тем, что делает работу с моделью предметной области более эффективной.
Теперь, естественно, нам нужен репозиторий для хранения событий нашего домена:
public class EventStore {
private Map<String, List<Event>> store = new HashMap<>();
}
Это простая структура данных в памяти для хранения событий предметной области. На самом деле существует несколько решений, специально созданных для обработки данных о событиях, таких как Apache Druid . Существует множество распределенных хранилищ данных общего назначения, способных обрабатывать источники событий, включая Kafka и Cassandra .
5.2. Генерация и потребление событий
Итак, теперь наш сервис, который обрабатывал все CRUD-операции, изменится. Теперь вместо обновления состояния движущегося домена будут добавляться события домена. Он также будет использовать те же события домена для ответа на запросы.
Давайте посмотрим, как мы можем этого добиться:
public class UserService {
private EventStore repository;
public UserService(EventStore repository) {
this.repository = repository;
}
public void createUser(String userId, String firstName, String lastName) {
repository.addEvent(userId, new UserCreatedEvent(userId, firstName, lastName));
}
public void updateUser(String userId, Set<Contact> contacts, Set<Address> addresses) {
User user = UserUtility.recreateUserState(repository, userId);
user.getContacts().stream()
.filter(c -> !contacts.contains(c))
.forEach(c -> repository.addEvent(
userId, new UserContactRemovedEvent(c.getType(), c.getDetail())));
contacts.stream()
.filter(c -> !user.getContacts().contains(c))
.forEach(c -> repository.addEvent(
userId, new UserContactAddedEvent(c.getType(), c.getDetail())));
user.getAddresses().stream()
.filter(a -> !addresses.contains(a))
.forEach(a -> repository.addEvent(
userId, new UserAddressRemovedEvent(a.getCity(), a.getState(), a.getPostcode())));
addresses.stream()
.filter(a -> !user.getAddresses().contains(a))
.forEach(a -> repository.addEvent(
userId, new UserAddressAddedEvent(a.getCity(), a.getState(), a.getPostcode())));
}
public Set<Contact> getContactByType(String userId, String contactType) {
User user = UserUtility.recreateUserState(repository, userId);
return user.getContacts().stream()
.filter(c -> c.getType().equals(contactType))
.collect(Collectors.toSet());
}
public Set<Address> getAddressByRegion(String userId, String state) throws Exception {
User user = UserUtility.recreateUserState(repository, userId);
return user.getAddresses().stream()
.filter(a -> a.getState().equals(state))
.collect(Collectors.toSet());
}
}
Обратите внимание, что здесь мы генерируем несколько событий как часть обработки операции обновления пользователя. Кроме того, интересно отметить, как мы генерируем текущее состояние модели предметной области, воспроизводя все сгенерированные до сих пор события предметной области .
Конечно, в реальном приложении это неприемлемая стратегия, и нам придется поддерживать локальный кеш, чтобы каждый раз не генерировать состояние. Существуют и другие стратегии, такие как моментальные снимки и сведение в репозиторий событий, которые могут ускорить процесс.
На этом мы завершаем наши усилия по внедрению источника событий в наше простое приложение.
5.3. Преимущества и недостатки Event Sourcing
Теперь мы успешно применили альтернативный способ хранения объектов предметной области с использованием источников событий. Источник событий — это мощный шаблон, который при правильном использовании приносит много преимуществ архитектуре приложения:
- Делает операции записи намного быстрее , так как не требуется чтение, обновление и запись; write просто добавляет событие в журнал
- Устраняет объектно-реляционное сопротивление и, следовательно, необходимость в сложных инструментах сопоставления; конечно, нам еще нужно пересоздать объекты обратно
- Бывает, что в качестве побочного продукта предоставляется журнал аудита , который полностью надежен; мы можем отладить, как именно изменилось состояние модели предметной области
- Это позволяет поддерживать временные запросы и достигать путешествий во времени (состояние домена в какой-то момент в прошлом)!
- Он идеально подходит для разработки слабосвязанных компонентов в архитектуре микросервисов, которые взаимодействуют асинхронно путем обмена сообщениями.
Однако, как всегда, даже источник событий не панацея. Это заставляет нас принять совершенно другой способ хранения данных. Это может оказаться бесполезным в нескольких случаях:
- Существует связанная с этим кривая обучения и изменение мышления, необходимое для принятия источников событий; это не интуитивно, для начала
- Это затрудняет обработку типичных запросов , поскольку нам нужно воссоздать состояние, если мы не сохраняем состояние в локальном кеше.
- Хотя его можно применить к любой предметной модели, он больше подходит для модели, основанной на событиях, в архитектуре, управляемой событиями.
6. CQRS с источником событий
Теперь, когда мы увидели, как по отдельности внедрить Event Sourcing и CQRS в наше простое приложение, пришло время объединить их. Теперь должно быть достаточно интуитивно понятно, что эти шаблоны могут значительно выигрывать друг от друга . Однако в этом разделе мы сделаем это более явным.
Давайте сначала посмотрим, как архитектура приложения объединяет их:
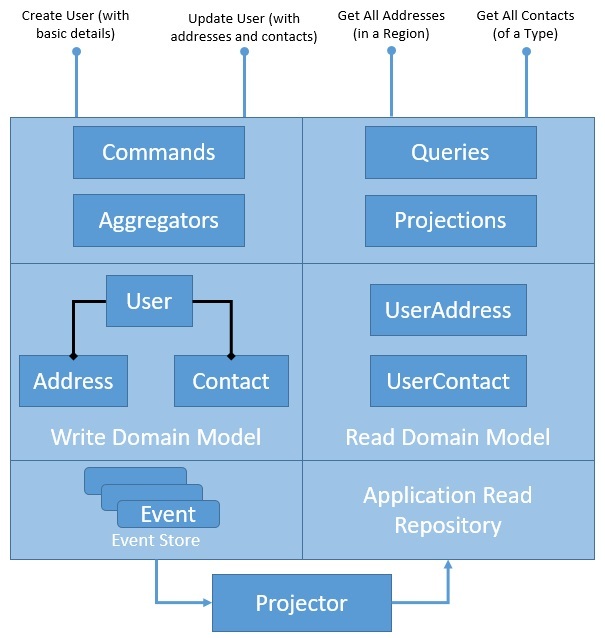
Это уже не должно быть сюрпризом. Мы заменили сторону записи репозитория на хранилище событий, в то время как сторона чтения репозитория осталась прежней.
Обратите внимание, что это не единственный способ использования Event Sourcing и CQRS в архитектуре приложения. Мы можем быть довольно новаторскими и использовать эти шаблоны вместе с другими шаблонами и придумать несколько вариантов архитектуры.
Здесь важно убедиться, что мы используем их для управления сложностью, а не просто для дальнейшего усложнения!
6.1. Объединение CQRS и Event Sourcing
Внедрив Event Sourcing и CQRS по отдельности, не должно быть сложно понять, как мы можем объединить их.
Мы начнем с приложения, в котором мы представили CQRS, и просто внесем соответствующие изменения , чтобы включить источник событий. Мы также будем использовать те же события и хранилище событий, которые мы определили в нашем приложении, где мы представили источники событий.
Есть только несколько изменений. Мы начнем с изменения агрегата для генерации событий вместо обновления состояния :
public class UserAggregate {
private EventStore writeRepository;
public UserAggregate(EventStore repository) {
this.writeRepository = repository;
}
public List<Event> handleCreateUserCommand(CreateUserCommand command) {
UserCreatedEvent event = new UserCreatedEvent(command.getUserId(),
command.getFirstName(), command.getLastName());
writeRepository.addEvent(command.getUserId(), event);
return Arrays.asList(event);
}
public List<Event> handleUpdateUserCommand(UpdateUserCommand command) {
User user = UserUtility.recreateUserState(writeRepository, command.getUserId());
List<Event> events = new ArrayList<>();
List<Contact> contactsToRemove = user.getContacts().stream()
.filter(c -> !command.getContacts().contains(c))
.collect(Collectors.toList());
for (Contact contact : contactsToRemove) {
UserContactRemovedEvent contactRemovedEvent = new UserContactRemovedEvent(contact.getType(),
contact.getDetail());
events.add(contactRemovedEvent);
writeRepository.addEvent(command.getUserId(), contactRemovedEvent);
}
List<Contact> contactsToAdd = command.getContacts().stream()
.filter(c -> !user.getContacts().contains(c))
.collect(Collectors.toList());
for (Contact contact : contactsToAdd) {
UserContactAddedEvent contactAddedEvent = new UserContactAddedEvent(contact.getType(),
contact.getDetail());
events.add(contactAddedEvent);
writeRepository.addEvent(command.getUserId(), contactAddedEvent);
}
// similarly process addressesToRemove
// similarly process addressesToAdd
return events;
}
}
Единственное другое изменение, которое требуется, — это проектор, который теперь должен обрабатывать события, а не состояния объекта домена :
public class UserProjector {
UserReadRepository readRepository = new UserReadRepository();
public UserProjector(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public void project(String userId, List<Event> events) {
for (Event event : events) {
if (event instanceof UserAddressAddedEvent)
apply(userId, (UserAddressAddedEvent) event);
if (event instanceof UserAddressRemovedEvent)
apply(userId, (UserAddressRemovedEvent) event);
if (event instanceof UserContactAddedEvent)
apply(userId, (UserContactAddedEvent) event);
if (event instanceof UserContactRemovedEvent)
apply(userId, (UserContactRemovedEvent) event);
}
}
public void apply(String userId, UserAddressAddedEvent event) {
Address address = new Address(
event.getCity(), event.getState(), event.getPostCode());
UserAddress userAddress = Optional.ofNullable(
readRepository.getUserAddress(userId))
.orElse(new UserAddress());
Set<Address> addresses = Optional.ofNullable(userAddress.getAddressByRegion()
.get(address.getState()))
.orElse(new HashSet<>());
addresses.add(address);
userAddress.getAddressByRegion()
.put(address.getState(), addresses);
readRepository.addUserAddress(userId, userAddress);
}
public void apply(String userId, UserAddressRemovedEvent event) {
Address address = new Address(
event.getCity(), event.getState(), event.getPostCode());
UserAddress userAddress = readRepository.getUserAddress(userId);
if (userAddress != null) {
Set<Address> addresses = userAddress.getAddressByRegion()
.get(address.getState());
if (addresses != null)
addresses.remove(address);
readRepository.addUserAddress(userId, userAddress);
}
}
public void apply(String userId, UserContactAddedEvent event) {
// Similarly handle UserContactAddedEvent event
}
public void apply(String userId, UserContactRemovedEvent event) {
// Similarly handle UserContactRemovedEvent event
}
}
Если мы вспомним проблемы, которые мы обсуждали при работе с проекцией на основе состояния, это потенциальное решение.
The event-based projection is rather convenient and easier to implement . All we have to do is process all occurring domain events and apply them to all read domain models. Typically, in an event-based application, the projector would listen to domain events it's interested in and would not rely on someone calling it directly.
This is pretty much all we have to do to bring Event Sourcing and CQRS together in our simple application.
7. Conclusion
In this tutorial, we discussed the basics of Event Sourcing and CQRS design patterns. We developed a simple application and applied these patterns individually to it.
In the process, we understood the advantages they bring and the drawbacks they present. Finally, we understood why and how to incorporate both of these patterns together in our application.
The simple application we've discussed in this tutorial does not even come close to justifying the need for CQRS and Event Sourcing. Our focus was to understand the basic concepts, hence, the example was trivial. But as mentioned before, the benefit of these patterns can only be realized in applications that have a reasonably complex domain model.
As usual, the source code for this article can be found over on GitHub .