1. Введение
В этой статье мы создадим простую нейронную сеть с помощью библиотеки deeplearning4j (dl4j) — современного и мощного инструмента для машинного обучения.
Прежде чем мы начнем, не то, чтобы это руководство не требовало глубоких знаний линейной алгебры, статистики, теории машинного обучения и множества других тем, необходимых хорошо подготовленному инженеру машинного обучения.
2. Что такое глубокое обучение?
Нейронные сети — это вычислительные модели, состоящие из взаимосвязанных слоев узлов.
Узлы — это нейроноподобные процессоры числовых данных. Они берут данные со своих входов, применяют к этим данным некоторые веса и функции и отправляют результаты на выходы. Такую сеть можно обучить на некоторых примерах исходных данных.
По сути, обучение — это сохранение некоторого числового состояния (веса) в узлах, которое впоследствии влияет на вычисления. Обучающие примеры могут содержать элементы данных с признаками и определенными известными классами этих элементов (например, «этот набор 16×16 пикселей содержит написанную от руки букву «а»).
После завершения обучения нейронная сеть может извлекать информацию из новых данных, даже если она раньше не видела эти конкретные элементы данных . Хорошо смоделированная и хорошо обученная сеть может распознавать изображения, рукописные буквы, речь, обрабатывать статистические данные для получения результатов для бизнес-аналитики и многое другое.
Глубокие нейронные сети стали возможны в последние годы с развитием высокопроизводительных и параллельных вычислений. Такие сети отличаются от простых нейронных сетей тем, что состоят из множества промежуточных (или скрытых ) слоев . Эта структура позволяет сетям обрабатывать данные гораздо более сложным образом (рекурсивно, рекуррентно, сверточно и т. д.) и извлекать из них намного больше информации.
3. Настройка проекта
Чтобы использовать библиотеку, нам нужна как минимум Java 7. Также из-за некоторых нативных компонентов она работает только с 64-битной версией JVM.
Прежде чем начать с руководства, давайте проверим, выполнены ли требования:
$ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
Во-первых, давайте добавим необходимые библиотеки в наш файл Maven pom.xml . Мы извлечем версию библиотеки в запись свойства (последнюю версию библиотек можно найти в репозитории Maven Central ):
<properties>
<dl4j.version>0.9.1</dl4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${dl4j.version}</version>
</dependency>
</dependencies>
Обратите внимание, что зависимость nd4j-native-platform является одной из нескольких доступных реализаций.
Он основан на собственных библиотеках, доступных для многих различных платформ (macOS, Windows, Linux, Android и т. д.). Мы также могли бы переключить серверную часть на nd4j-cuda-8.0-platform , если бы хотели выполнять вычисления на видеокарте, поддерживающей модель программирования CUDA.
4. Подготовка данных
4.1. Подготовка файла набора данных
Напишем «Hello World» машинного обучения — классификацию набора данных цветка ириса . Это набор данных, собранных с цветков разных видов ( Iris setosa , Iris versicolor и Iris virginica ).
Эти виды отличаются длиной и шириной лепестков и чашелистиков. Было бы трудно написать точный алгоритм, который классифицирует элемент входных данных (т. е. определяет, к какому виду принадлежит тот или иной цветок). Но хорошо обученная нейронная сеть может классифицировать его быстро и с небольшими ошибками.
Мы собираемся использовать версию этих данных в формате CSV, где столбцы 0..3 содержат различные характеристики видов, а столбец 4 содержит класс записи или виды, закодированные значением 0, 1 или 2:
5.1,3.5,1.4,0.2,0
4.9,3.0,1.4,0.2,0
4.7,3.2,1.3,0.2,0
…
7.0,3.2,4.7,1.4,1
6.4,3.2,4.5,1.5,1
6.9,3.1,4.9,1.5,1
…
4.2. Векторизация и чтение данных
Мы кодируем класс числом, потому что нейронные сети работают с числами. Преобразование реальных элементов данных в ряды чисел (векторов) называется векторизацией — для этого deeplearning4j использует библиотеку datavec .
Во-первых, воспользуемся этой библиотекой для ввода файла с векторизованными данными. При создании CSVRecordReader мы можем указать количество пропускаемых строк (например, если в файле есть строка заголовка) и символ-разделитель (в нашем случае запятая):
try (RecordReader recordReader = new CSVRecordReader(0, ',')) {
recordReader.initialize(new FileSplit(
new ClassPathResource("iris.txt").getFile()));
// …
}
Для перебора записей мы можем использовать любую из нескольких реализаций интерфейса DataSetIterator . Наборы данных могут быть довольно большими, и может пригодиться возможность постраничного вывода или кэширования значений.
Но наш небольшой набор данных содержит всего 150 записей, поэтому давайте сразу прочитаем все данные в память вызовом iterator.next() .
Мы также указываем индекс столбца класса, который в нашем случае совпадает с количеством объектов (4) и общим количеством классов (3).
Также обратите внимание, что нам нужно перетасовать набор данных, чтобы избавиться от порядка классов в исходном файле.
Мы указываем постоянное случайное начальное число (42) вместо вызова System.currentTimeMillis() по умолчанию , чтобы результаты перетасовки всегда были одинаковыми. Это позволяет нам получать стабильные результаты при каждом запуске программы:
DataSetIterator iterator = new RecordReaderDataSetIterator(
recordReader, 150, FEATURES_COUNT, CLASSES_COUNT);
DataSet allData = iterator.next();
allData.shuffle(42);
4.3. Нормализация и разделение
Еще одна вещь, которую мы должны сделать с данными перед обучением, — это нормализовать их. Нормализация представляет собой двухэтапный процесс :
- сбор некоторой статистики о данных (подгонка)
- изменение (преобразование) данных каким-либо образом, чтобы сделать их однородными
Нормализация может отличаться для разных типов данных.
Например, если мы хотим обрабатывать изображения разных размеров, мы должны сначала собрать статистику размера, а затем масштабировать изображения до одинакового размера.
Но для чисел нормализация обычно означает преобразование их в так называемое нормальное распределение. В этом нам может помочь класс NormalizerStandardize :
DataNormalization normalizer = new NormalizerStandardize();
normalizer.fit(allData);
normalizer.transform(allData);
Теперь, когда данные подготовлены, нам нужно разделить набор на две части.
Первая часть будет использоваться на тренировке. Мы будем использовать вторую часть данных (которую сеть вообще не увидит) для тестирования обученной сети.
Это позволит нам убедиться, что классификация работает правильно. Возьмем 65% данных (0,65) для обучения, а остальные 35% оставим для тестирования:
SplitTestAndTrain testAndTrain = allData.splitTestAndTrain(0.65);
DataSet trainingData = testAndTrain.getTrain();
DataSet testData = testAndTrain.getTest();
5. Подготовка конфигурации сети
5.1. Свободный построитель конфигураций
Теперь мы можем создать конфигурацию нашей сети с помощью модного беглого компоновщика:
MultiLayerConfiguration configuration
= new NeuralNetConfiguration.Builder()
.iterations(1000)
.activation(Activation.TANH)
.weightInit(WeightInit.XAVIER)
.learningRate(0.1)
.regularization(true).l2(0.0001)
.list()
.layer(0, new DenseLayer.Builder().nIn(FEATURES_COUNT).nOut(3).build())
.layer(1, new DenseLayer.Builder().nIn(3).nOut(3).build())
.layer(2, new OutputLayer.Builder(
LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(3).nOut(CLASSES_COUNT).build())
.backprop(true).pretrain(false)
.build();
Даже при таком упрощенном беглом способе построения сетевой модели нужно многое переварить и настроить множество параметров. Давайте разберем эту модель.
5.2. Установка сетевых параметров
Метод построителя iterations() указывает количество итераций оптимизации.
Итеративная оптимизация означает выполнение нескольких проходов обучающего набора до тех пор, пока сеть не сойдется к хорошему результату.
Обычно при обучении на реальных и больших наборах данных мы используем несколько эпох (полные проходы данных по сети) и одну итерацию для каждой эпохи. Но поскольку наш исходный набор данных минимален, мы будем использовать одну эпоху и несколько итераций.
Активация () — это функция, которая запускается внутри узла для определения его выходных данных.
Простейшая функция активации будет линейной f(x) = x. Но оказывается, что только нелинейные функции позволяют сетям решать сложные задачи с использованием нескольких узлов.
Доступно множество различных функций активации, которые мы можем найти в перечислении org.nd4j.linalg.activations.Activation . Мы также могли бы написать нашу функцию активации, если это необходимо. Но мы будем использовать предоставленную функцию гиперболического тангенса (tanh).
Метод weightInit() указывает один из многих способов установки начальных весов для сети. Правильные начальные веса могут сильно повлиять на результаты тренировки. Не вдаваясь слишком в математику, давайте установим его в форме распределения Гаусса ( WeightInit.XAVIER ), так как это обычно хороший выбор для начала.
Все другие методы инициализации веса можно найти в перечислении org.deeplearning4j.nn.weights.WeightInit .
Скорость обучения является важным параметром, который сильно влияет на способность сети к обучению.
Мы могли бы потратить много времени на настройку этого параметра в более сложном случае. Но для нашей простой задачи мы будем использовать довольно важное значение 0,1 и настроим его с помощью метода построения LearningRate() .
Одной из проблем обучения нейронных сетей является случай переобучения , когда сеть «запоминает» обучающие данные.
Это происходит, когда сеть устанавливает чрезмерно высокие веса для обучающих данных и дает плохие результаты для любых других данных.
Чтобы решить эту проблему, мы настроим регуляризацию l2 с помощью строки .regularization(true).l2(0.0001) . Регуляризация «наказывает» сеть за слишком большие веса и предотвращает переобучение.
5.3. Построение сетевых слоев
Затем мы создаем сеть плотных (также называемых полносвязными) слоев.
Первый слой должен содержать такое же количество узлов, как и столбцы в обучающих данных (4).
Второй плотный слой будет содержать три узла. Это значение мы можем варьировать, но количество выходов в предыдущем слое должно быть одинаковым.
Окончательный выходной слой должен содержать количество узлов, соответствующее количеству классов (3). Структура сети представлена на картинке:
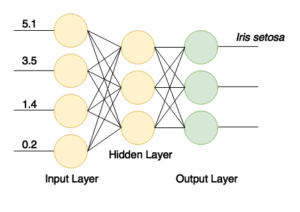
После успешного обучения у нас будет сеть, которая получает на свои входы четыре значения и отправляет сигнал на один из трех своих выходов. Это простой классификатор.
Наконец, чтобы закончить построение сети, мы настраиваем обратное распространение (один из самых эффективных методов обучения) и отключаем предварительное обучение с помощью строки .backprop(true).pretrain(false) .
6. Создание и обучение сети
Теперь создадим нейросеть из конфигурации, инициализируем и запустим:
MultiLayerNetwork model = new MultiLayerNetwork(configuration);
model.init();
model.fit(trainingData);
Теперь мы можем протестировать обученную модель, используя остальную часть набора данных, и проверить результаты с помощью метрик оценки для трех классов:
INDArray output = model.output(testData.getFeatureMatrix());
Evaluation eval = new Evaluation(3);
eval.eval(testData.getLabels(), output);
Если мы теперь распечатаем eval.stats() , мы увидим, что наша сеть довольно хорошо классифицирует цветы ириса, хотя она трижды ошибочно принимала класс 1 за класс 2.
Examples labeled as 0 classified by model as 0: 19 times
Examples labeled as 1 classified by model as 1: 16 times
Examples labeled as 1 classified by model as 2: 3 times
Examples labeled as 2 classified by model as 2: 15 times
==========================Scores========================================
# of classes: 3
Accuracy: 0.9434
Precision: 0.9444
Recall: 0.9474
F1 Score: 0.9411
Precision, recall & F1: macro-averaged (equally weighted avg. of 3 classes)
========================================================================
Свободный построитель конфигураций позволяет нам быстро добавлять или изменять уровни сети или настраивать некоторые другие параметры, чтобы увидеть, можно ли улучшить нашу модель.
7. Заключение
В этой статье мы создали простую, но мощную нейронную сеть, используя библиотеку deeplearning4j.
Как всегда, исходный код статьи доступен на GitHub .