1. Обзор
В этой статье мы сосредоточимся на создании файла . docx с помощью библиотеки docx4j .
Docx4j — это библиотека Java, используемая для создания файлов Office OpenXML и управления ими. Это означает, что она может работать только с файлами типа .docx , в то время как более старые версии Microsoft Word используют расширение .doc (двоичные файлы).
Обратите внимание, что формат OpenXML поддерживается Microsoft Office, начиная с версии 2007.
2. Настройка Мавена
Чтобы начать работать с docx4j, нам нужно добавить необходимую зависимость в наш pom.xml :
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>3.3.5</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.1</version>
</dependency>
Обратите внимание, что мы всегда можем посмотреть последние версии зависимостей в центральном репозитории Maven .
Зависимость JAXB необходима, так как docx4j использует эту библиотеку под капотом для маршаллинга/демаршаллинга XML-частей в файле docx .
3. Создайте документ в формате Docx
3.1. Текстовые элементы и стиль
Давайте сначала посмотрим, как создать простой файл docx — с текстовым абзацем:
WordprocessingMLPackage wordPackage = WordprocessingMLPackage.createPackage();
MainDocumentPart mainDocumentPart = wordPackage.getMainDocumentPart();
mainDocumentPart.addStyledParagraphOfText("Title", "Hello World!");
mainDocumentPart.addParagraphOfText("Welcome To ForEach");
File exportFile = new File("welcome.docx");
wordPackage.save(exportFile);
Вот полученный файл welcome.docx :
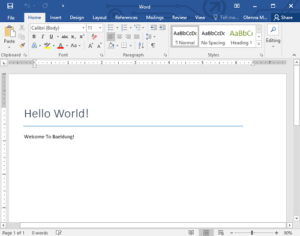
Чтобы создать новый документ, мы должны использовать WordprocessingMLPackage , который представляет файл docx в формате OpenXML , а класс MainDocumentPart содержит представление основной части document.xml .
Чтобы прояснить ситуацию, давайте разархивируем файл welcome.docx и откроем файл word/document.xml , чтобы увидеть, как выглядит XML-представление:
<w:body>
<w:p>
<w:pPr>
<w:pStyle w:val="Title"/>
</w:pPr>
<w:r>
<w:t>Hello World!</w:t>
</w:r>
</w:p>
<w:p>
<w:r>
<w:t>Welcome To ForEach!</w:t>
</w:r>
</w:p>
</w:body>
Как мы видим, каждое предложение представлено последовательностью ( r ) текста ( t ) внутри абзаца ( p ) , и для этого предназначен метод addParagraphOfText() .
addStyledParagraphOfText () делает немного больше; он создает свойства абзаца ( pPr ), которые содержат стиль, применяемый к абзацу.
Проще говоря, абзацы объявляют отдельные прогоны, и каждый прогон содержит несколько текстовых элементов:

Чтобы создать красиво выглядящий документ, нам нужно иметь полный контроль над этими элементами (абзацем, строкой и текстом).
Итак, давайте узнаем, как стилизовать наш контент с помощью объекта runProperties ( RPr ):
ObjectFactory factory = Context.getWmlObjectFactory();
P p = factory.createP();
R r = factory.createR();
Text t = factory.createText();
t.setValue("Welcome To ForEach");
r.getContent().add(t);
p.getContent().add(r);
RPr rpr = factory.createRPr();
BooleanDefaultTrue b = new BooleanDefaultTrue();
rpr.setB(b);
rpr.setI(b);
rpr.setCaps(b);
Color green = factory.createColor();
green.setVal("green");
rpr.setColor(green);
r.setRPr(rpr);
mainDocumentPart.getContent().add(p);
File exportFile = new File("welcome.docx");
wordPackage.save(exportFile);
Вот как выглядит результат:
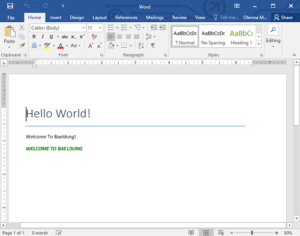
После того, как мы создали абзац, бег и текстовый элемент, используя createP() , createR() и createText() соответственно, мы объявили новый объект runProperties ( RPr ), чтобы добавить некоторые стили к текстовому элементу.
Объект rpr используется для установки свойств форматирования, полужирного ( B ), курсивного ( I ) и заглавного ( Caps ), эти свойства применяются к тексту, выполняемому с помощью метода setRPr() .
3.2. Работа с изображениями
Docx4j предлагает простой способ добавления изображений в наш документ Word:
File image = new File("image.jpg" );
byte[] fileContent = Files.readAllBytes(image.toPath());
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage
.createImagePart(wordPackage, fileContent);
Inline inline = imagePart.createImageInline(
"ForEach Image (filename hint)", "Alt Text", 1, 2, false);
P Imageparagraph = addImageToParagraph(inline);
mainDocumentPart.getContent().add(Imageparagraph);
А вот как выглядит реализация метода addImageToParagraph() :
private static P addImageToParagraph(Inline inline) {
ObjectFactory factory = new ObjectFactory();
P p = factory.createP();
R r = factory.createR();
p.getContent().add(r);
Drawing drawing = factory.createDrawing();
r.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
return p;
}
Сначала мы создали файл, содержащий изображение, которое мы хотим добавить в нашу основную часть документа, затем мы связали массив байтов, представляющий изображение, с объектом wordMLPackage .
После создания части изображения нам нужно создать объект Inline с помощью метода createImageInline( ).
Метод addImageToParagraph() встраивает встроенный объект в рисунок , чтобы его можно было добавить в цикл.
Наконец, как и текстовый абзац, абзац, содержащий изображение, добавляется в mainDocumentPart .
И вот получившийся документ:
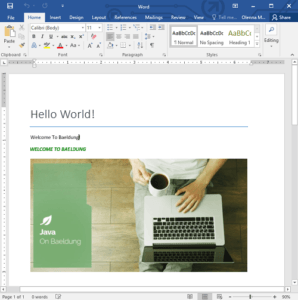
3.3. Создание таблиц
Docx4j также упрощает работу с таблицами (Tbl), строками (Tr) и столбцами (Tc).
Давайте посмотрим, как создать таблицу 3×3 и добавить в нее содержимое:
int writableWidthTwips = wordPackage.getDocumentModel()
.getSections().get(0).getPageDimensions().getWritableWidthTwips();
int columnNumber = 3;
Tbl tbl = TblFactory.createTable(3, 3, writableWidthTwips/columnNumber);
List<Object> rows = tbl.getContent();
for (Object row : rows) {
Tr tr = (Tr) row;
List<Object> cells = tr.getContent();
for(Object cell : cells) {
Tc td = (Tc) cell;
td.getContent().add(p);
}
}
Учитывая некоторые строки и столбцы, метод createTable() создает новый объект Tbl , третий аргумент относится к ширине столбца в твипах (что является измерением расстояния — 1/1440 дюйма).
После создания мы можем перебирать содержимое объекта tbl и добавлять объекты Paragraph в каждую ячейку.
Посмотрим, как выглядит окончательный результат:
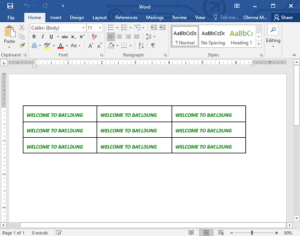
4. Чтение документа в формате Docx
Теперь, когда мы узнали, как использовать docx4j для создания документов, давайте посмотрим, как прочитать существующий файл docx и распечатать его содержимое:
File doc = new File("helloWorld.docx");
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage
.load(doc);
MainDocumentPart mainDocumentPart = wordMLPackage
.getMainDocumentPart();
String textNodesXPath = "//w:t";
List<Object> textNodes= mainDocumentPart
.getJAXBNodesViaXPath(textNodesXPath, true);
for (Object obj : textNodes) {
Text text = (Text) ((JAXBElement) obj).getValue();
String textValue = text.getValue();
System.out.println(textValue);
}
В этом примере мы создали объект WordprocessingMLPackage на основе существующего файла helloWorld.docx , используя метод load() .
После этого мы использовали выражение XPath ( //w:t ), чтобы получить все текстовые узлы из основной части документа.
Метод getJAXBNodesViaXPath() возвращает список объектов JAXBElement .
В результате все текстовые элементы внутри объекта mainDocumentPart печатаются в консоли.
Обратите внимание, что мы всегда можем разархивировать наши файлы docx, чтобы лучше понять структуру XML, что помогает в анализе проблем и дает лучшее представление о том, как их решать.
5. Вывод
В этой статье мы узнали, как docx4j упрощает выполнение сложных операций с документом MSWord, таких как создание абзацев, таблиц, частей документа и добавление изображений.
Фрагменты кода, как всегда, можно найти на GitHub .