1. Введение
В этом руководстве мы поймем, как проводить распределенное тестирование производительности с помощью Gatling . В процессе мы создадим простое приложение для тестирования с помощью Gatling, поймем обоснование использования распределенного тестирования производительности и, наконец, поймем, какая поддержка доступна в Gatling для достижения этой цели.
2. Тестирование производительности с помощью Gatling
Тестирование производительности — это метод тестирования, который оценивает скорость отклика и стабильность системы при определенной рабочей нагрузке . Существует несколько типов тестов, которые обычно относятся к тестированию производительности. К ним относятся нагрузочное тестирование, стресс-тестирование, тестирование выдержки, пиковое тестирование и некоторые другие. Все они имеют свои конкретные цели для достижения.
Однако одним из общих аспектов любого тестирования производительности является моделирование рабочих нагрузок, и такие инструменты, как Gatling , JMeter и K6 , помогают нам в этом. Но, прежде чем мы продолжим, нам нужно приложение, которое мы можем протестировать на производительность.
Затем мы разработаем простую модель рабочей нагрузки для тестирования производительности этого приложения.
2.1. Создание приложения
В этом руководстве мы создадим простое веб-приложение Spring Boot с использованием Spring CLI:
spring init --dependencies=web my-application
Далее мы создадим простой REST API, который предоставляет случайное число по запросу:
@RestController
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@GetMapping("/api/random")
public Integer getRandom() {
Random random = new Random();
return random.nextInt(1000);
}
}
В этом API нет ничего особенного — он просто возвращает случайное целое число в диапазоне от 0 до 999 при каждом вызове.
Запустить это приложение довольно просто с помощью команды Maven:
mvnw spring-boot:run
2.2. Создание модели рабочей нагрузки
Если нам нужно развернуть этот простой API в рабочей среде, мы должны убедиться, что он может справиться с ожидаемой нагрузкой и по-прежнему обеспечивать желаемое качество обслуживания. Здесь нам нужно выполнить различные тесты производительности. Модель рабочей нагрузки обычно определяет один или несколько профилей рабочей нагрузки для имитации реального использования .
Для веб-приложения с пользовательским интерфейсом определение подходящей модели рабочей нагрузки может быть довольно сложной задачей. Но для нашего простого API мы можем сделать предположения о распределении нагрузки для нагрузочного тестирования.
Gatling предоставляет Scala DSL для создания сценариев для тестирования в моделировании . Давайте начнем с создания базового сценария для API, который мы создали ранее:
package randomapi
import io.gatling.core.Predef._
import io.gatling.core.structure.ScenarioBuilder
import io.gatling.http.Predef._
import io.gatling.http.protocol.HttpProtocolBuilder
class RandomAPILoadTest extends Simulation {
val protocol: HttpProtocolBuilder = http.baseUrl("http://localhost:8080/")
val scn: ScenarioBuilder = scenario("Load testing of Random Number API")
.exec(
http("Get Random Number")
.get("api/random")
.check(status.is(200))
)
val duringSeconds: Integer = Integer.getInteger("duringSeconds", 10)
val constantUsers: Integer = Integer.getInteger("constantUsers", 10)
setUp(scn.inject(constantConcurrentUsers(constantUsers) during (duringSeconds))
.protocols(protocol))
.maxDuration(1800)
.assertions(global.responseTime.max.lt(20000), global.successfulRequests.percent.gt(95))
}
Давайте обсудим основные моменты этой базовой симуляции:
- Начнем с добавления некоторых необходимых импортов Gatling DSL.
- Далее мы определяем конфигурацию протокола HTTP
- Затем мы определяем сценарий с одним запросом к нашему API.
- Наконец, мы создаем определение моделирования для нагрузки, которую мы хотим ввести; здесь мы вводим нагрузку, используя 10 одновременных пользователей в течение 10 секунд.
Создать такой сценарий для более сложных приложений с пользовательским интерфейсом может быть довольно сложно. К счастью, Gatling поставляется с еще одной утилитой, называемой рекордером . Используя этот рекордер, мы можем создавать сценарии, позволяя ему прокси-взаимодействия между браузером и сервером. Он также может использовать файл HAR (HTTP-архив) для создания сценариев.
2.3. Выполнение моделирования
Теперь мы готовы выполнить наш нагрузочный тест. Для этого мы можем поместить наш файл моделирования «RandomAPILoadTest.scala» в каталог «%GATLING_HOME%/user-file/randomapi/». Обратите внимание, что это не единственный способ выполнить симуляцию, но, безусловно, один из самых простых.
Мы можем запустить Gatling, выполнив команду:
$GATLING_HOME/bin/gatling.sh
Это предложит нам выбрать симуляцию для запуска:
Choose a simulation number:
[0] randomapi.RandomAPILoadTest
При выборе симуляции она запустит симуляцию и сгенерирует вывод со сводкой:
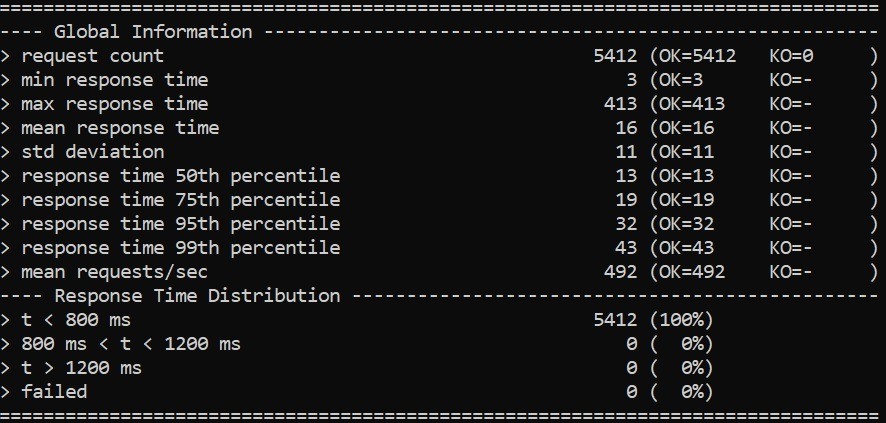
Далее генерирует отчет в формате HTML в каталоге «%GATLING_HOME%/results»:
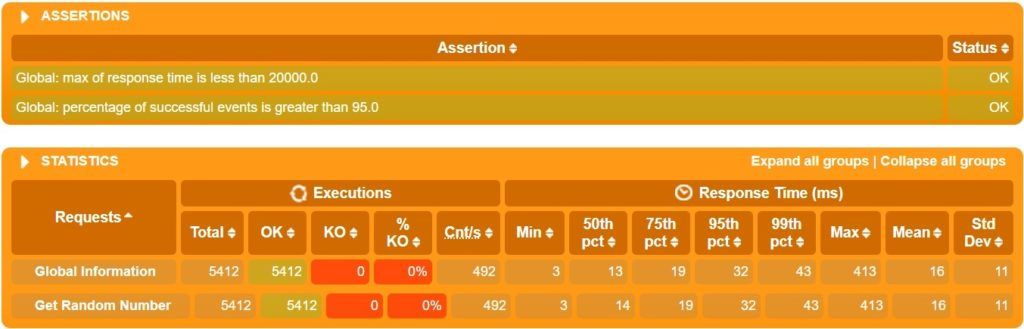
Это только одна часть сгенерированного отчета, но мы можем ясно видеть сводку результатов. Это довольно подробно и легко следовать.
3. Распределенное тестирование производительности
Все идет нормально. Но, если вспомнить, целью тестирования производительности является имитация реальных рабочих нагрузок. Это может быть значительно выше для популярных приложений, чем нагрузка, которую мы видели в нашем тривиальном случае здесь . Если мы заметим в сводке тестов, нам удалось достичь пропускной способности примерно 500 запросов в секунду. Для реального приложения, обрабатывающего реальные рабочие нагрузки, это может быть во много раз больше!
Как смоделировать такую рабочую нагрузку с помощью любого инструмента производительности? Реально ли достичь этих цифр, вводя нагрузку только с одной машины? Возможно нет. Даже если инструмент внедрения нагрузки может справиться с гораздо более высокими нагрузками, базовая операционная система и сеть имеют свои собственные ограничения .
Здесь мы должны распределить нашу инъекцию нагрузки по нескольким машинам. Конечно, как и любая другая модель распределенных вычислений, у нее есть свои проблемы:
- Как мы распределяем рабочую нагрузку между участвующими машинами?
- Кто координирует их завершение и устранение возможных ошибок?
- Как мы собираем и обобщаем результаты для консолидированной отчетности?
Типичная архитектура распределенного тестирования производительности использует главные и подчиненные узлы для решения некоторых из этих проблем:
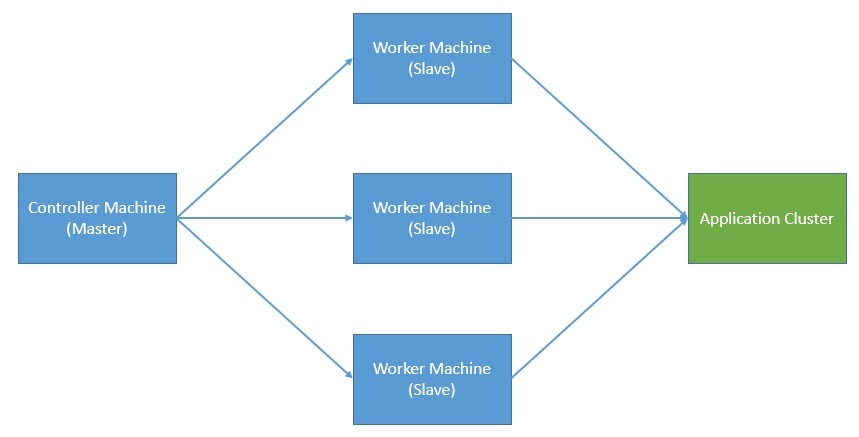
Но, опять же, что произойдет, если мастер сломается? В задачи этого руководства не входит рассмотрение всех проблем, связанных с распределенными вычислениями , но мы, безусловно, должны подчеркнуть их последствия при выборе распределенной модели для тестирования производительности.
4. Распределенное тестирование производительности с помощью Gatling
Теперь, когда мы поняли необходимость распределенного тестирования производительности, мы посмотрим, как мы можем добиться этого с помощью Gatling. Режим кластеризации — это встроенная функция Gatling Frontline . Однако Frontline является корпоративной версией Gatling и недоступна с открытым исходным кодом. Frontline поддерживает развертывание инжекторов локально или у любого из популярных поставщиков облачных услуг.
Тем не менее, с помощью Gatling с открытым исходным кодом этого все еще можно достичь . Но большую часть тяжелой работы нам придется делать самим. В этом разделе мы рассмотрим основные шаги для его достижения. Здесь мы будем использовать ту же симуляцию, которую мы определили ранее, для создания нагрузки с несколькими машинами.
4.1. Настраивать
Мы начнем с создания компьютера-контроллера и нескольких удаленных рабочих компьютеров либо локально , либо в любом из облачных сервисов. Есть определенные предпосылки, которые мы должны выполнить на всех этих машинах. К ним относятся установка Gatling с открытым исходным кодом на всех рабочих машинах и настройка некоторых переменных среды контроллера.
Чтобы добиться стабильного результата, мы должны установить одну и ту же версию Gatling на всех рабочих машинах с одинаковой конфигурацией на каждой из них. Это включает в себя каталог, в который мы устанавливаем Gatling, и пользователя, которого мы создаем для его установки.
Давайте посмотрим на важные переменные среды, которые нам нужно установить на машине контроллера:
HOSTS=( 192.168.x.x 192.168.x.x 192.168.x.x)
И давайте также определим список удаленных рабочих машин, которые мы будем использовать для ввода нагрузки:
GATLING_HOME=/gatling/gatling-charts-highcharts-1.5.6
GATLING_SIMULATIONS_DIR=$GATLING_HOME/user-files/simulations
SIMULATION_NAME='randomapi.RandomAPILoadTest'
GATLING_RUNNER=$GATLING_HOME/bin/gatling.sh
GATLING_REPORT_DIR=$GATLING_HOME/results/
GATHER_REPORTS_DIR=/gatling/reports/
Некоторые переменные указывают на каталог установки Gatling и другие скрипты, которые нам нужны для запуска симуляции. В нем также упоминается каталог, в котором мы хотим создавать отчеты. Позже мы увидим, где их использовать.
Важно отметить, что мы предполагаем, что машины имеют среду, подобную Linux . Но мы можем легко адаптировать процедуру для других платформ, таких как Windows.
4.2. Распределение нагрузки
Здесь мы скопируем один и тот же сценарий на несколько рабочих машин , созданных ранее. Может быть несколько способов скопировать симуляцию на удаленный хост. Самый простой способ — использовать scp для поддерживаемых хостов. Мы также можем автоматизировать это с помощью сценария оболочки:
for HOST in "${HOSTS[@]}"
do
scp -r $GATLING_SIMULATIONS_DIR/* $USER_NAME@$HOST:$GATLING_SIMULATIONS_DIR
done
Приведенная выше команда копирует содержимое каталога на локальном хосте в каталог на удаленном хосте. Для пользователей Windows PuTTY — лучший вариант, который также поставляется с PSCP (протокол защищенного копирования PuTTY). Мы можем использовать PSCP для передачи файлов между клиентами Windows и серверами Windows или Unix.
4.3. Выполнение моделирования
Как только мы скопировали симуляции на рабочие машины, мы готовы их запустить. Ключом к достижению совокупного числа одновременных пользователей является выполнение имитации на всех хостах почти одновременно .
Мы снова можем автоматизировать этот шаг, используя сценарий оболочки:
for HOST in "${HOSTS[@]}"
do
ssh -n -f $USER_NAME@$HOST \
"sh -c 'nohup $GATLING_RUNNER -nr -s $SIMULATION_NAME \
> /gatling/run.log 2>&1 &'"
done
Мы используем ssh для запуска симуляции на удаленных рабочих машинах. Здесь важно отметить, что мы используем параметр «без отчетов» (-nr). Это связано с тем, что на данном этапе нас интересует только сбор журналов, а позже мы создадим отчет, объединив журналы со всех рабочих машин.
4.4. Сбор результатов
Теперь нам нужно собрать файлы журналов, сгенерированные симуляциями на всех рабочих машинах . Это, опять же, то, что мы можем автоматизировать с помощью сценария оболочки и выполнить с компьютера-контроллера:
for HOST in "${HOSTS[@]}"
do
ssh -n -f $USER_NAME@$HOST \
"sh -c 'ls -t $GATLING_REPORT_DIR | head -n 1 | xargs -I {} \
mv ${GATLING_REPORT_DIR}{} ${GATLING_REPORT_DIR}report'"
scp $USER_NAME@$HOST:${GATLING_REPORT_DIR}report/simulation.log \
${GATHER_REPORTS_DIR}simulation-$HOST.log
done
Команды могут показаться сложными для тех из нас, кто не очень хорошо разбирается в сценариях оболочки. Но это не так сложно, когда мы разбиваем их на части. Сначала мы подключаемся по ssh к удаленному хосту, перечисляем все файлы в каталоге отчетов Gatling в обратном хронологическом порядке и берем первый файл.
Затем мы копируем выбранный файл журнала с удаленного хоста на компьютер с контроллером и переименовываем его, добавляя имя хоста. Это важно, так как у нас будет несколько лог-файлов с одинаковыми именами с разных хостов.
4.5. Создание отчета
Наконец, мы должны создать отчет из всех файлов журналов, собранных в результате симуляций, выполненных на разных рабочих машинах . К счастью, всю тяжелую работу здесь делает Гатлинг:
mv $GATHER_REPORTS_DIR $GATLING_REPORT_DIR
$GATLING_RUNNER -ro reports
Мы копируем все файлы журналов в стандартный каталог отчетов Gatling и выполняем команду Gating для создания отчета. Это предполагает, что у нас также установлен Gatling на компьютере с контроллером. Окончательный отчет похож на то, что мы видели ранее:
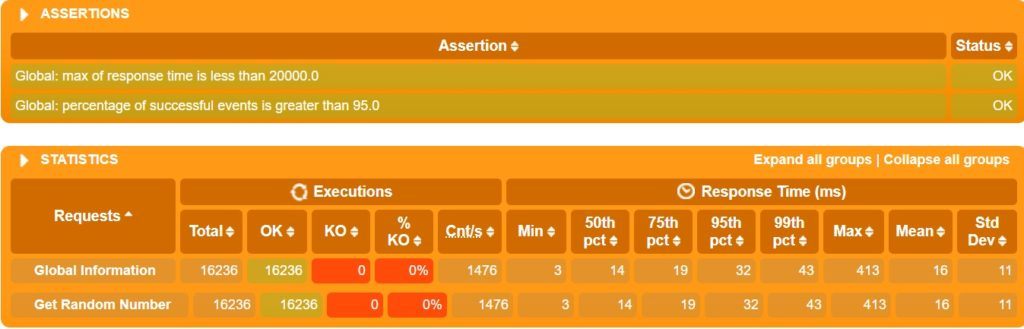
Здесь мы даже не осознаем, что на самом деле нагрузка была введена с нескольких машин! Мы можем ясно видеть, что количество запросов увеличилось почти втрое, когда мы использовали три рабочих машины. Однако в реальных сценариях масштабирование не будет таким идеально линейным!
5. Рекомендации по масштабированию тестирования производительности
Мы видели, что распределенное тестирование производительности — это способ масштабирования тестирования производительности для имитации реальных рабочих нагрузок. Теперь, хотя распределенное тестирование производительности полезно, у него есть свои нюансы. Следовательно, мы определенно должны попытаться максимально масштабировать возможности внедрения нагрузки по вертикали . Только когда мы достигнем вертикального предела на одной машине, мы должны рассмотреть возможность использования распределенного тестирования.
Как правило, ограничивающими факторами для масштабирования внедрения нагрузки на машину являются базовая операционная система или сеть. Есть определенные вещи, которые мы можем оптимизировать, чтобы сделать это лучше. В Linux-подобных средах количество одновременных пользователей, которых может создать инжектор загрузки, обычно ограничивается пределом открытых файлов . Мы можем рассмотреть возможность его увеличения с помощью команды ulimit .
Еще один важный фактор касается ресурсов, доступных на машине. Например, инъекция нагрузки обычно потребляет много пропускной способности сети. Если пропускная способность сети машины является ограничивающим фактором, мы можем рассмотреть возможность ее модернизации. Точно так же процессор или память, доступные на машине, могут быть другими ограничивающими факторами. В облачных средах довольно легко переключиться на более мощный компьютер .
Наконец, сценарии, которые мы включаем в нашу симуляцию, должны быть устойчивыми, поскольку мы не должны всегда предполагать положительный отклик под нагрузкой. Следовательно, мы должны быть осторожны и защищаться, записывая наши утверждения по ответу. Кроме того, мы должны свести количество утверждений к минимуму , чтобы сохранить наши усилия по увеличению пропускной способности.
6. Заключение
В этом руководстве мы рассмотрели основы выполнения распределенного теста производительности с помощью Gatling. Мы создали простое приложение для тестирования, разработали простую симуляцию в Gatling, а затем поняли, как мы можем выполнить это на нескольких машинах.
В процессе мы также поняли необходимость распределенного тестирования производительности и лучшие практики, связанные с ним.