1. Введение
С момента появления Java 8 многие люди начали использовать (новую) функциональность потоков. Конечно, бывают моменты, когда наши потоковые операции не работают должным образом.
В IntelliJ помимо обычных параметров отладки есть специальная функция потоковой отладки. В этом коротком руководстве мы рассмотрим эту замечательную функцию.
2. Диалоговое окно трассировки потока
Начнем с того, что покажем, как открыть диалоговое окно Stream Trace. На панели инструментов окна отладки есть значок Trace Current Stream Chain, который активируется только тогда, когда наше приложение приостанавливается в точке останова внутри вызова потокового API :
При нажатии на значок откроется диалоговое окно Stream Trace.
Диалог имеет два режима. Мы рассмотрим Flat Mode в первом примере. А во втором примере мы покажем режим по умолчанию, то есть режим разделения.
3. Примеры
Теперь, когда мы представили функцию потоковой отладки в IntelliJ, пришло время поработать с некоторыми примерами кода.
3.1. Базовый пример с отсортированным потоком
Давайте начнем с простого фрагмента кода, чтобы привыкнуть к диалогу Stream Trace:
int[] listOutputSorted = IntStream.of(-3, 10, -4, 1, 3)
.sorted()
.toArray();
Изначально. у нас есть поток неупорядоченного int . Затем мы сортируем этот поток и преобразуем его в массив.
Когда мы просматриваем трассировку потока в плоском режиме , она показывает нам обзор выполняемых шагов:
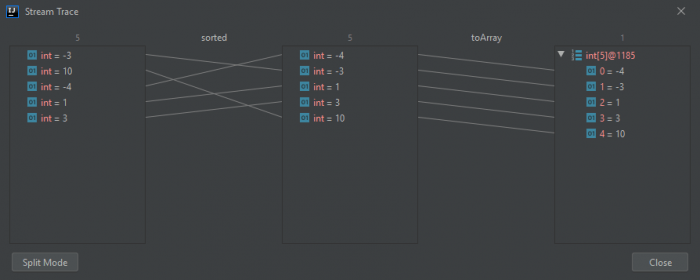
В крайнем левом углу мы видим начальный поток. Он содержит int в том порядке, в котором мы их написали.
Первый набор стрелок показывает нам новое расположение всех элементов после сортировки. И в крайнем правом углу мы видим наш вывод. Все элементы появляются там в отсортированном порядке.
Теперь, когда мы рассмотрели основы, пришло время для более сложного примера.
3.2. Пример использования flatMap и фильтра
В следующем примере используется flatMap . Stream.flatMap помогает нам, например, преобразовать список необязательных элементов в обычный список. В следующем примере мы начинаем со списка необязательных клиентов . Затем мы сопоставляем его со списком Customer и применяем некоторую фильтрацию:
List<Optional<Customer>> customers = Arrays.asList(
Optional.of(new Customer("John P.", 15)),
Optional.of(new Customer("Sarah M.", 78)),
Optional.empty(),
Optional.of(new Customer("Mary T.", 20)),
Optional.empty(),
Optional.of(new Customer("Florian G.", 89)),
Optional.empty()
);
long numberOf65PlusCustomers = customers
.stream()
.flatMap(c -> c
.map(Stream::of)
.orElseGet(Stream::empty))
.mapToInt(Customer::getAge)
.filter(c -> c > 65)
.count();
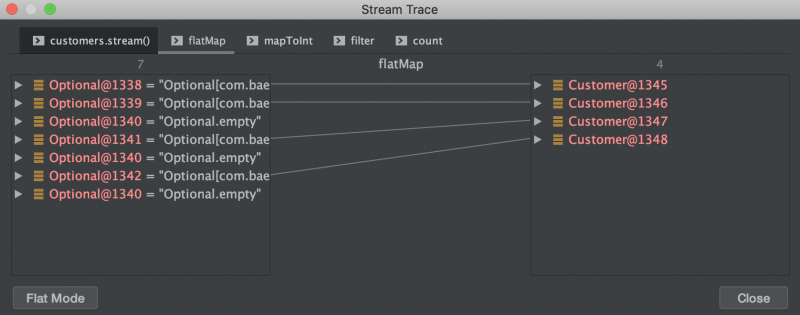
Далее, давайте просмотрим трассировку потока в режиме разделения, который дает нам лучший обзор этого потока.
Слева мы видим входной поток. Далее мы видим плоское сопоставление потока необязательных клиентов с потоком фактически существующих клиентов:
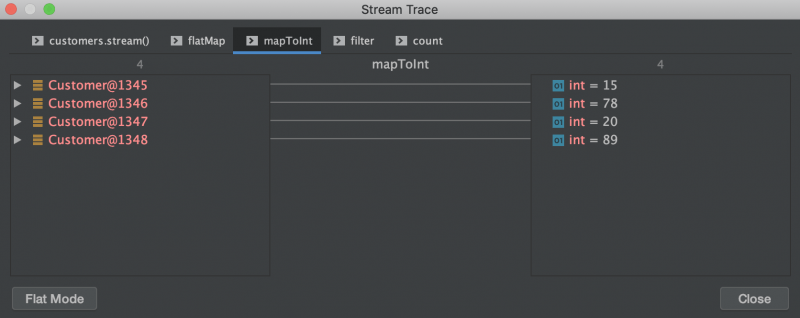
После этого мы сопоставляем наш поток клиентов с их возрастом:
Следующий шаг фильтрует наш поток возрастов до потока возрастов старше 65 лет:
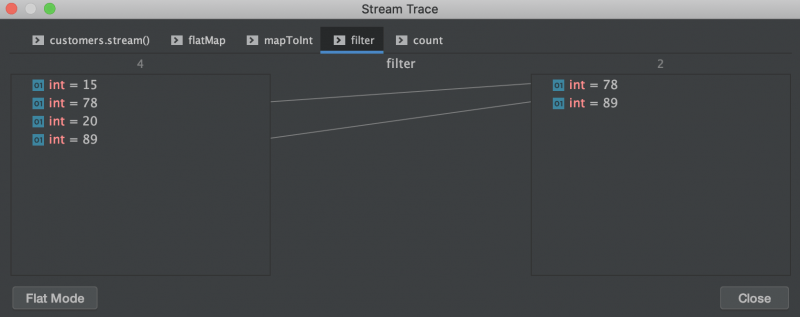
Наконец, мы подсчитываем количество элементов в нашем потоке возрастов:
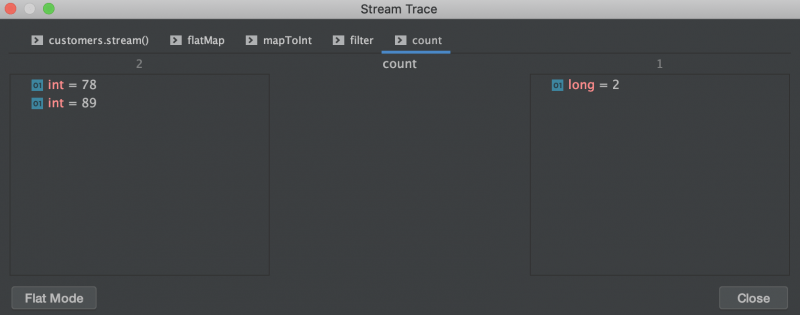
4. Предостережения
В приведенных выше примерах мы видели некоторые возможности, предлагаемые диалоговым окном Stream Trace. Тем не менее, есть некоторые важные детали, о которых следует знать. Большинство из них являются прямым следствием того, как работают потоки.
Во- первых, потоки всегда требуют выполнения терминальных операций . Это ничем не отличается при использовании диалогового окна Stream Trace. Также мы должны знать об операциях, которые не потребляют весь поток — например, anyMatch . В этом случае будут отображаться не все элементы, а только обработанные.
Во- вторых, имейте в виду, что поток будет потребляться . Если мы объявим поток отдельно от его операций, мы можем столкнуться с ошибкой «Поток уже обработан или закрыт» . Мы можем предотвратить эту ошибку, объединив объявление потока с его использованием.
5. Вывод
В этом кратком руководстве мы увидели, как использовать диалоговое окно IntelliJ Stream Trace.
Сначала мы рассмотрели простой случай, демонстрирующий сортировку и сбор. Затем мы рассмотрели более сложный сценарий, включающий плоское сопоставление, сопоставление, фильтрацию и подсчет.
Наконец, мы рассмотрели некоторые предостережения, с которыми мы можем столкнуться при использовании функции потоковой отладки.
Как всегда, полный исходный код статьи доступен на GitHub .