1. Обзор
В этой статье мы сравним BitSet и boolean[] с точки зрения производительности в разных сценариях.
Обычно мы очень широко используем термин производительность, имея в виду разные значения. Поэтому начнем с рассмотрения различных определений термина «производительность».
Затем мы собираемся использовать две разные метрики производительности для тестов: объем памяти и пропускная способность. Чтобы оценить пропускную способность, мы сравним несколько распространенных операций с битовыми векторами.
2. Определение производительности
Производительность — это очень общий термин для обозначения широкого спектра понятий, связанных с «производительностью»!
Иногда мы используем этот термин, чтобы говорить о скорости запуска конкретного приложения; то есть количество времени, которое требуется приложению, прежде чем оно сможет ответить на свой первый запрос.
Помимо скорости запуска, когда мы говорим о производительности, мы можем думать об использовании памяти . Таким образом, объем памяти — еще один аспект этого термина.
Можно интерпретировать «производительность» как то, насколько «быстро» работает наш код . Таким образом, задержка — это еще один аспект производительности.
Для некоторых приложений очень важно знать пропускную способность системы с точки зрения операций в секунду. Таким образом, пропускная способность может быть еще одним аспектом производительности .
Некоторые приложения только после того, как отреагируют на несколько запросов и технически «прогреются», могут работать на своем пиковом уровне производительности. Следовательно, время достижения максимальной производительности является еще одним аспектом .
Список возможных определений можно продолжать и продолжать! Однако в этой статье мы сосредоточимся только на двух показателях производительности: объеме памяти и пропускной способности .
3. Объем памяти
Хотя мы могли бы ожидать, что логические значения будут потреблять только один бит, каждое логическое значение в логическом [] потребляет один байт памяти . В основном это делается для того, чтобы избежать разрывов слов и проблем с доступностью . Поэтому, если нам нужен вектор битов, boolean[] будет иметь довольно значительный объем памяти.
Чтобы сделать вещи более конкретными, мы можем использовать Java Object Layout (JOL) для проверки расположения памяти логического [] с, скажем, 10 000 элементов:
boolean[] ba = new boolean[10_000];
System.out.println(ClassLayout.parseInstance(ba).toPrintable());
Это напечатает макет памяти:
[Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (1)
4 4 (object header) 00 00 00 00 (0)
8 4 (object header) 05 00 00 f8 (-134217723)
12 4 (object header) 10 27 00 00 (10000)
16 10000 boolean [Z. N/A
Instance size: 10016 bytes
Как показано выше, это логическое значение [] потребляет около 10 КБ памяти.
С другой стороны, BitSet использует комбинацию примитивных типов данных (особенно long ) и побитовых операций для получения одного бита на отпечаток флага . Таким образом, BitSet с 10 000 битов будет потреблять гораздо меньше памяти по сравнению с логическим [] с тем же размером:
BitSet bitSet = new BitSet(10_000);
System.out.println(GraphLayout.parseInstance(bitSet).toPrintable());
Точно так же это напечатает макет памяти BitSet :
java.util.BitSet@5679c6c6d object externals:
ADDRESS SIZE TYPE PATH
76beb8190 24 java.util.BitSet
76beb81a8 1272 [J .words
Как и ожидалось, BitSet с тем же количеством битов потребляет около 1 КБ, что намного меньше, чем boolean[] .
Мы также можем сравнить объем памяти для разного количества битов:
Path path = Paths.get("footprint.csv");
try (BufferedWriter stream = Files.newBufferedWriter(path, StandardOpenOption.CREATE)) {
stream.write("bits,bool,bitset\n");
for (int i = 0; i <= 10_000_000; i += 500) {
System.out.println("Number of bits => " + i);
boolean[] ba = new boolean[i];
BitSet bitSet = new BitSet(i);
long baSize = ClassLayout.parseInstance(ba).instanceSize();
long bitSetSize = GraphLayout.parseInstance(bitSet).totalSize();
stream.write((i + "," + baSize + "," + bitSetSize + "\n"));
if (i % 10_000 == 0) {
stream.flush();
}
}
}
Приведенный выше код будет вычислять размер объекта для обоих типов битовых векторов с разной длиной. Затем он записывает и сбрасывает сравнения размеров в CSV-файл.
Теперь, если мы построим этот файл CSV, мы увидим, что абсолютная разница в занимаемой памяти увеличивается с количеством битов :

Ключевым выводом здесь является то, что BitSet превосходит boolean[] с точки зрения занимаемой памяти, за исключением минимального количества битов.
4. Пропускная способность
Чтобы сравнить пропускную способность BitSet и boolean[] друг с другом, мы проведем три теста, основанные на трех разных, но повседневных операциях над битовыми векторами:
- Получение значения определенного бита
- Установка или очистка значения определенного бита
- Подсчет количества установленных битов
Это обычная установка, которую мы собираемся использовать для сравнения пропускной способности битовых векторов разной длины:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
public class VectorOfBitsBenchmark {
private boolean[] array;
private BitSet bitSet;
@Param({"100", "1000", "5000", "50000", "100000", "1000000", "2000000", "3000000",
"5000000", "7000000", "10000000", "20000000", "30000000", "50000000", "70000000", "1000000000"})
public int size;
@Setup(Level.Trial)
public void setUp() {
array = new boolean[size];
for (int i = 0; i < array.length; i++) {
array[i] = ThreadLocalRandom.current().nextBoolean();
}
bitSet = new BitSet(size);
for (int i = 0; i < size; i++) {
bitSet.set(i, ThreadLocalRandom.current().nextBoolean());
}
}
// omitted benchmarks
}
Как показано выше, мы создаем boolean[] и BitSet с длинами в диапазоне 100-1 000 000 000. Кроме того, после установки нескольких битов в процессе установки мы будем выполнять различные операции как с логическими значениями [] , так и с BitSet .
4.1. Получение немного
На первый взгляд, прямой доступ к памяти в boolean[] кажется более эффективным, чем выполнение двух побитовых операций на получение в BitSet s (сдвиг влево плюс операция and ). С другой стороны, компактность памяти BitSet может позволить им разместить больше значений внутри строки кэша.
Посмотрим, кто из них победит! Вот тесты, которые JMH будет запускать каждый раз с другим значением состояния размера :
@Benchmark
public boolean getBoolArray() {
return array[ThreadLocalRandom.current().nextInt(size)];
}
@Benchmark
public boolean getBitSet() {
return bitSet.get(ThreadLocalRandom.current().nextInt(size));
}
4.2. Получение бита: пропускная способность
Мы собираемся запустить тесты, используя следующую команду:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff get.csv getBitSet getBoolArray
Это запустит связанные с get тесты с использованием четырех потоков и двух ответвлений, профилирует их статистику выполнения с помощью инструмента perf в Linux и выводит результат в файл BenchGet.csv `` . « -prof perfnorm» профилирует эталонный тест с помощью инструмента perf в Linux и нормализует счетчики производительности на основе количества операций.
Так как результат команды очень подробный, мы собираемся изобразить их здесь. Перед этим давайте посмотрим на базовую структуру каждого результата теста:
"Benchmark","Mode","Threads","Samples","Score","Score Error (99.9%)","Unit","Param: size"
"getBitSet","thrpt",4,40,184790139.562014,2667066.521846,"ops/s",100
"getBitSet:L1-dcache-load-misses","thrpt",4,2,0.002467,NaN,"#/op",100
"getBitSet:L1-dcache-loads","thrpt",4,2,19.050243,NaN,"#/op",100
"getBitSet:L1-dcache-stores","thrpt",4,2,6.042285,NaN,"#/op",100
"getBitSet:L1-icache-load-misses","thrpt",4,2,0.002206,NaN,"#/op",100
"getBitSet:branch-misses","thrpt",4,2,0.000451,NaN,"#/op",100
"getBitSet:branches","thrpt",4,2,12.985709,NaN,"#/op",100
"getBitSet:dTLB-load-misses","thrpt",4,2,0.000194,NaN,"#/op",100
"getBitSet:dTLB-loads","thrpt",4,2,19.132320,NaN,"#/op",100
"getBitSet:dTLB-store-misses","thrpt",4,2,0.000034,NaN,"#/op",100
"getBitSet:dTLB-stores","thrpt",4,2,6.035930,NaN,"#/op",100
"getBitSet:iTLB-load-misses","thrpt",4,2,0.000246,NaN,"#/op",100
"getBitSet:iTLB-loads","thrpt",4,2,0.000417,NaN,"#/op",100
"getBitSet:instructions","thrpt",4,2,90.781944,NaN,"#/op",100
Как показано выше, результатом является список полей, разделенных запятыми, каждое из которых представляет показатель. Например, «thrpt» представляет пропускную способность, «L1-dcache-load-misses» — количество промахов кеша для кеша данных уровня 1, «L1-icache-load-misses» — это количество промахов кеша для уровня 1 кэш инструкций, а «инструкции» представляют собой количество инструкций ЦП для каждого теста. Кроме того, последнее поле представляет количество битов, а первое представляет имя метода эталонного теста.
Вот как выглядят результаты тестов пропускной способности типичной капли Digitial Ocean с 4-ядерным процессором Intel(R) Xeon(R) 2,20 ГГц:
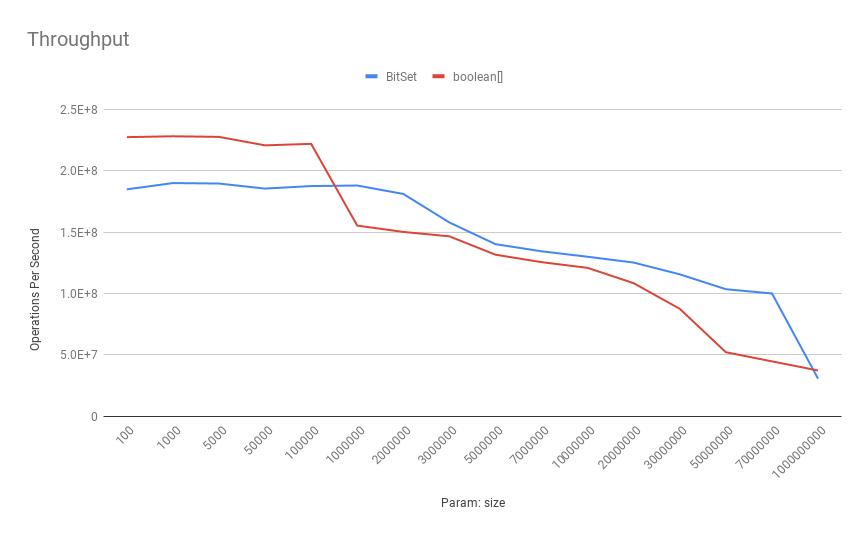
Как показано выше, boolean [] имеет лучшую пропускную способность при меньших размерах. Когда количество битов увеличивается, BitSet превосходит boolean[] с точки зрения пропускной способности . Чтобы быть более конкретным, после 100 000 бит BitSet показывает превосходную производительность.
4.3. Получение бита: инструкции по операции
Как мы и ожидали, операция get над boolean[] имеет меньше инструкций на операцию :

4.4. Получение бита: промахи кэша данных
Теперь давайте посмотрим, как промахи кэша данных ищут эти битовые векторы:

Как показано выше, количество промахов кеша данных для логического [] увеличивается по мере увеличения количества битов.
Таким образом, промахи кэша обходятся намного дороже, чем выполнение дополнительных инструкций здесь . Таким образом, BitSet API в большинстве случаев превосходит boolean[] в этом сценарии.
4.5. Установка бита
Чтобы сравнить пропускную способность операций над множествами, мы будем использовать эти тесты:
@Benchmark
public void setBoolArray() {
int index = ThreadLocalRandom.current().nextInt(size);
array[index] = true;
}
@Benchmark
public void setBitSet() {
int index = ThreadLocalRandom.current().nextInt(size);
bitSet.set(index);
}
По сути, мы выбираем случайный битовый индекс и устанавливаем для него значение true . Точно так же мы можем запустить эти тесты, используя следующую команду:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff set.csv setBitSet setBoolArray
Давайте посмотрим, как выглядят результаты тестов для этих операций с точки зрения пропускной способности:
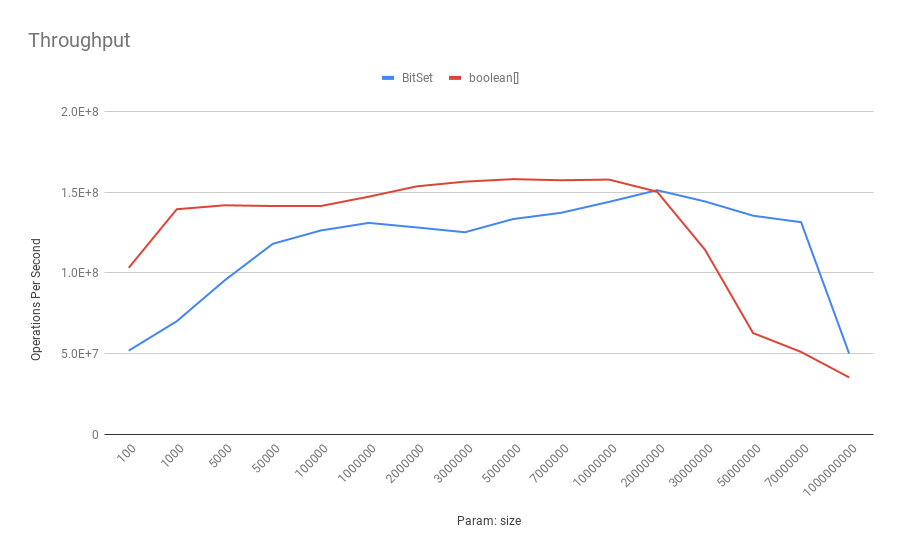
На этот раз boolean[] превосходит BitSet в большинстве случаев, за исключением очень больших размеров . Поскольку мы можем иметь больше битов BitSet внутри строки кэша, эффект промахов кэша и ложного совместного использования может быть более значительным в экземплярах BitSet .
Вот сравнение промахов кеша данных:

Как показано выше, количество промахов кэша данных для логического [] довольно мало для низкого и среднего количества битов. Опять же, когда количество битов увеличивается, логическое значение[] сталкивается с большим количеством промахов кеша.
Точно так же инструкции на операцию для boolean[] разумно меньше, чем для BitSet :

4.6. мощность
Одной из других распространенных операций с такими битовыми векторами является подсчет количества заданных битов. На этот раз мы собираемся запустить эти тесты:
@Benchmark
public int cardinalityBoolArray() {
int sum = 0;
for (boolean b : array) {
if (b) sum++;
}
return sum;
}
@Benchmark
public int cardinalityBitSet() {
return bitSet.cardinality();
}
Мы снова можем запустить эти тесты с помощью следующей команды:
$ java -jar jmh-1.0-SNAPSHOT.jar -f2 -t4 -prof perfnorm -rff cardinal.csv cardinalityBitSet cardinalityBoolArray
Вот как выглядит пропускная способность для этих тестов:

С точки зрения пропускной способности API BitSet почти всегда превосходит boolean[] , потому что у него намного меньше итераций . Чтобы быть более конкретным, BitSet должен повторять только свой внутренний long[] , который имеет гораздо меньше элементов по сравнению с соответствующим boolean[] .
Кроме того, из-за этой строки и случайного распределения наборов битов в наших битовых векторах:
if (b) {
sum++;
}
Стоимость неправильного предсказания перехода также может быть решающей:

Как показано выше, по мере увеличения количества бит количество ошибочных предсказаний для логического [] значительно возрастает.
5. Вывод
В этой статье мы сравнили пропускную способность BitSet и boolean[] с точки зрения трех распространенных операций: получение бита, установка бита и вычисление количества элементов. В дополнение к пропускной способности мы увидели, что BitSet использует гораздо меньше памяти по сравнению с логическим значением [] того же размера.
Напомним, что в однобитовых сценариях с интенсивным чтением логическое значение [] превосходит BitSet в меньших размерах. Однако, когда количество битов увеличивается, BitSet имеет более высокую пропускную способность.
Более того, в однобитовых сценариях с интенсивной записью логическое значение [] демонстрирует превосходную пропускную способность почти все время, за исключением очень большого количества битов. Кроме того, в сценариях пакетного чтения BitSet API полностью доминирует над логическим [] подходом.
Мы использовали интеграцию JMH-perf для сбора низкоуровневых показателей ЦП, таких как промахи кэша данных L1 или прогнозы пропущенных ветвей. Начиная с Linux 2.6.31, perf является стандартным профилировщиком Linux, способным отображать полезные счетчики мониторинга производительности или PMC. Также возможно использовать этот инструмент отдельно. Чтобы увидеть некоторые примеры этого автономного использования, настоятельно рекомендуется прочитать блог Branden Greg .
Как обычно, все примеры доступны на GitHub . Более того, CSV-результаты всех проведенных бенчмарков также доступны на GitHub .