1. Обзор
Кластеризация — это общий термин для класса неконтролируемых алгоритмов для обнаружения групп вещей, людей или идей, которые тесно связаны друг с другом .
В этом, казалось бы, простом однострочном определении мы увидели несколько модных словечек. Что такое кластеризация? Что такое неконтролируемый алгоритм?
В этом уроке мы собираемся, во-первых, пролить свет на эти концепции. Затем мы увидим, как они могут проявить себя в Java.
2. Неконтролируемые алгоритмы
Прежде чем использовать большинство алгоритмов обучения, мы должны каким-то образом передать им некоторые образцы данных и позволить алгоритму учиться на этих данных. В терминологии машинного обучения мы называем этот пример обучающими данными. Кроме того, весь процесс известен как процесс обучения.
В любом случае, мы можем классифицировать алгоритмы обучения на основе количества контроля, необходимого им в процессе обучения. Два основных типа алгоритмов обучения в этой категории:
- Обучение с учителем : в алгоритмах с учителем данные обучения должны включать фактическое решение для каждой точки. Например, если мы собираемся обучить наш алгоритм фильтрации спама, мы передаем алгоритму как примеры писем, так и их метки, т. е. спам или не спам. С математической точки зрения мы собираемся вывести
f(x)из тренировочного набора, включающего какxs, так иys. - Неконтролируемое обучение : когда в обучающих данных нет меток, алгоритм является неконтролируемым. Например, у нас есть много данных о музыкантах, и мы собираемся обнаружить в этих данных группы похожих музыкантов.
3. Кластеризация
Кластеризация — это неконтролируемый алгоритм для обнаружения групп похожих вещей, идей или людей. В отличие от контролируемых алгоритмов, мы не обучаем алгоритмы кластеризации на примерах известных меток. Вместо этого кластеризация пытается найти структуры в обучающем наборе, где ни одна точка данных не является меткой.
3.1. Кластеризация K-средних
K-Means — это алгоритм кластеризации с одним фундаментальным свойством: количество кластеров определяется заранее . В дополнение к K-средним существуют другие типы алгоритмов кластеризации, такие как иерархическая кластеризация, распространение сходства или спектральная кластеризация.
3.2. Как работает K-средство
Предположим, наша цель — найти несколько похожих групп в наборе данных, например:

K-Means начинается с k случайно расположенных центроидов. Центроиды, как следует из их названия, являются центральными точками кластеров . Например, здесь мы добавляем четыре случайных центроида:

Затем мы назначаем каждую существующую точку данных ее ближайшему центроиду:

После присвоения мы перемещаем центроиды в среднее расположение назначенных ему точек. Помните, что центроиды должны быть центральными точками кластеров:

Текущая итерация завершается каждый раз, когда мы завершаем перемещение центроидов. Мы повторяем эти итерации до тех пор, пока назначение между несколькими последовательными итерациями не перестанет меняться:
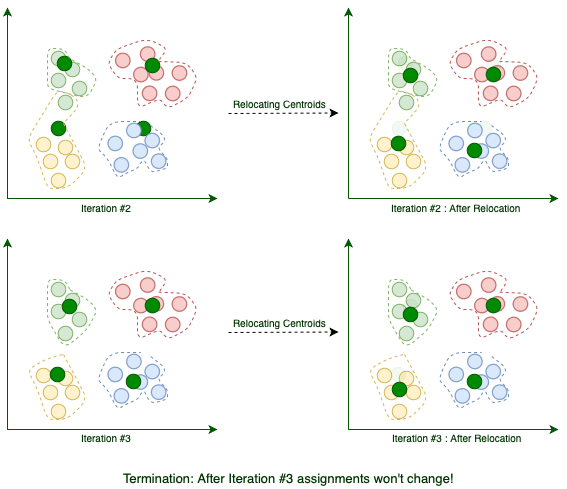
Когда алгоритм завершится, эти четыре кластера будут найдены, как и ожидалось. Теперь, когда мы знаем, как работает K-Means, давайте реализуем его на Java.
3.3. Представление функции
При моделировании различных обучающих наборов данных нам нужна структура данных для представления атрибутов модели и соответствующих им значений. Например, у музыканта может быть атрибут жанра со значением Рок . Обычно мы используем термин функция для обозначения комбинации атрибута и его значения.
Чтобы подготовить набор данных для конкретного алгоритма обучения, мы обычно используем общий набор числовых атрибутов, которые можно использовать для сравнения различных элементов. Например, если мы позволим нашим пользователям отмечать каждого исполнителя в определенном жанре, то, в конце концов, мы сможем подсчитать, сколько раз каждому исполнителю был присвоен определенный жанр:

Вектор признаков для таких исполнителей, как Linkin Park, таков: [рок -> 7890, ню-метал -> 700, альтернатива -> 520, поп -> 3]. Итак, если бы мы могли найти способ представления атрибутов в виде числовых значений, то мы могли бы просто сравнить два разных элемента, например исполнителей, сравнив их соответствующие векторные записи.
Поскольку числовые векторы являются такими универсальными структурами данных, мы собираемся представлять объекты с их помощью . Вот как мы реализуем векторы признаков в Java:
public class Record {
private final String description;
private final Map<String, Double> features;
// constructor, getter, toString, equals and hashcode
}
3.4. Поиск похожих товаров
В каждой итерации K-Means нам нужен способ найти ближайший центроид к каждому элементу в наборе данных. Один из самых простых способов вычислить расстояние между двумя векторами признаков — использовать Евклидово расстояние . Евклидово расстояние между двумя векторами, такими как [p1, q1] и [p2, q2] , равно:
![]()
Давайте реализуем эту функцию на Java. Во-первых, абстракция:
public interface Distance {
double calculate(Map<String, Double> f1, Map<String, Double> f2);
}
В дополнение к евклидову расстоянию существуют и другие подходы к вычислению расстояния или сходства между различными элементами, такие как коэффициент корреляции Пирсона . Эта абстракция позволяет легко переключаться между различными показателями расстояния.
Давайте посмотрим на реализацию для евклидова расстояния:
public class EuclideanDistance implements Distance {
@Override
public double calculate(Map<String, Double> f1, Map<String, Double> f2) {
double sum = 0;
for (String key : f1.keySet()) {
Double v1 = f1.get(key);
Double v2 = f2.get(key);
if (v1 != null && v2 != null) {
sum += Math.pow(v1 - v2, 2);
}
}
return Math.sqrt(sum);
}
}
Сначала мы вычисляем сумму квадратов разностей между соответствующими записями. Затем, применяя функцию sqrt , мы вычисляем фактическое евклидово расстояние.
3.5. Представление центроида
Центроиды находятся в том же пространстве, что и обычные функции, поэтому мы можем представить их аналогично функциям:
public class Centroid {
private final Map<String, Double> coordinates;
// constructors, getter, toString, equals and hashcode
}
Теперь, когда у нас есть несколько необходимых абстракций, пришло время написать нашу реализацию K-средних. Вот краткий обзор сигнатуры нашего метода:
public class KMeans {
private static final Random random = new Random();
public static Map<Centroid, List<Record>> fit(List<Record> records,
int k,
Distance distance,
int maxIterations) {
// omitted
}
}
Давайте разберем сигнатуру этого метода:
- Набор
данныхпредставляет собой набор векторов признаков. Поскольку каждый вектор признаков являетсязаписью,тип набора данных —список<запись> . - Параметр
kопределяет количество кластеров, которое мы должны предоставить заранее Distanceинкапсулирует способ, которым мы собираемся вычислить разницу между двумя функциями- K-Means завершается, когда назначение перестает меняться в течение нескольких последовательных итераций. В дополнение к этому условию завершения мы также можем указать верхнюю границу числа итераций. Аргумент
maxIterationsопределяет верхнюю границу - Когда K-Means завершается, каждый центроид должен иметь несколько назначенных функций, поэтому мы используем
Map<Centroid, List<Record>>в качестве возвращаемого типа. По сути, каждая запись карты соответствует кластеру.
3.6. Генерация центроидов
Первым шагом является создание k случайно расположенных центроидов.
Хотя каждый центроид может содержать полностью случайные координаты, рекомендуется генерировать случайные координаты между минимальным и максимальным возможными значениями для каждого атрибута . Генерация случайных центроидов без учета диапазона возможных значений приведет к более медленной сходимости алгоритма.
Сначала мы должны вычислить минимальное и максимальное значение для каждого атрибута, а затем сгенерировать случайные значения между каждой их парой:
private static List<Centroid> randomCentroids(List<Record> records, int k) {
List<Centroid> centroids = new ArrayList<>();
Map<String, Double> maxs = new HashMap<>();
Map<String, Double> mins = new HashMap<>();
for (Record record : records) {
record.getFeatures().forEach((key, value) -> {
// compares the value with the current max and choose the bigger value between them
maxs.compute(key, (k1, max) -> max == null || value > max ? value : max);
// compare the value with the current min and choose the smaller value between them
mins.compute(key, (k1, min) -> min == null || value < min ? value : min);
});
}
Set<String> attributes = records.stream()
.flatMap(e -> e.getFeatures().keySet().stream())
.collect(toSet());
for (int i = 0; i < k; i++) {
Map<String, Double> coordinates = new HashMap<>();
for (String attribute : attributes) {
double max = maxs.get(attribute);
double min = mins.get(attribute);
coordinates.put(attribute, random.nextDouble() * (max - min) + min);
}
centroids.add(new Centroid(coordinates));
}
return centroids;
}
Теперь мы можем присвоить каждую запись одному из этих случайных центроидов.
3.7. Назначение
Во- первых, учитывая Record , мы должны найти ближайший к нему центр тяжести:
private static Centroid nearestCentroid(Record record, List<Centroid> centroids, Distance distance) {
double minimumDistance = Double.MAX_VALUE;
Centroid nearest = null;
for (Centroid centroid : centroids) {
double currentDistance = distance.calculate(record.getFeatures(), centroid.getCoordinates());
if (currentDistance < minimumDistance) {
minimumDistance = currentDistance;
nearest = centroid;
}
}
return nearest;
}
Каждая запись принадлежит своему ближайшему центроидному кластеру:
private static void assignToCluster(Map<Centroid, List<Record>> clusters,
Record record,
Centroid centroid) {
clusters.compute(centroid, (key, list) -> {
if (list == null) {
list = new ArrayList<>();
}
list.add(record);
return list;
});
}
3.8. Центроид Перемещение
Если после одной итерации центроид не содержит никаких назначений, то мы не будем его перемещать. В противном случае мы должны переместить координату центроида для каждого атрибута в среднее положение всех назначенных записей:
private static Centroid average(Centroid centroid, List<Record> records) {
if (records == null || records.isEmpty()) {
return centroid;
}
Map<String, Double> average = centroid.getCoordinates();
records.stream().flatMap(e -> e.getFeatures().keySet().stream())
.forEach(k -> average.put(k, 0.0));
for (Record record : records) {
record.getFeatures().forEach(
(k, v) -> average.compute(k, (k1, currentValue) -> v + currentValue)
);
}
average.forEach((k, v) -> average.put(k, v / records.size()));
return new Centroid(average);
}
Поскольку мы можем переместить один центроид, теперь можно реализовать метод relocateCentroids :
private static List<Centroid> relocateCentroids(Map<Centroid, List<Record>> clusters) {
return clusters.entrySet().stream().map(e -> average(e.getKey(), e.getValue())).collect(toList());
}
Этот простой однострочный код перебирает все центроиды, перемещает их и возвращает новые центроиды.
3.9. Собираем все вместе
На каждой итерации, после присвоения всех записей их ближайшему центроиду, сначала мы должны сравнить текущие присвоения с последней итерацией.
Если назначения были идентичными, то алгоритм завершает работу. В противном случае, прежде чем перейти к следующей итерации, мы должны переместить центроиды:
public static Map<Centroid, List<Record>> fit(List<Record> records,
int k,
Distance distance,
int maxIterations) {
List<Centroid> centroids = randomCentroids(records, k);
Map<Centroid, List<Record>> clusters = new HashMap<>();
Map<Centroid, List<Record>> lastState = new HashMap<>();
// iterate for a pre-defined number of times
for (int i = 0; i < maxIterations; i++) {
boolean isLastIteration = i == maxIterations - 1;
// in each iteration we should find the nearest centroid for each record
for (Record record : records) {
Centroid centroid = nearestCentroid(record, centroids, distance);
assignToCluster(clusters, record, centroid);
}
// if the assignments do not change, then the algorithm terminates
boolean shouldTerminate = isLastIteration || clusters.equals(lastState);
lastState = clusters;
if (shouldTerminate) {
break;
}
// at the end of each iteration we should relocate the centroids
centroids = relocateCentroids(clusters);
clusters = new HashMap<>();
}
return lastState;
}
4. Пример: поиск похожих исполнителей на Last.fm
Last.fm создает подробный профиль музыкальных вкусов каждого пользователя, записывая сведения о том, что пользователь слушает. В этом разделе мы собираемся найти кластеры похожих исполнителей. Чтобы создать набор данных, подходящий для этой задачи, мы будем использовать три API от Last.fm:
- API для получения коллекции лучших исполнителей на Last.fm.
- Еще один API для поиска популярных тегов . Каждый пользователь может пометить исполнителя чем-либо, например,
роком.Итак, Last.fm поддерживает базу данных этих тегов и их частоты. - И API для получения лучших тегов для исполнителя , упорядоченных по популярности. Так как таких тегов много, мы сохраним только те теги, которые входят в число самых популярных глобальных тегов.
4.1. API Last.fm
Чтобы использовать эти API, мы должны получить ключ API от Last.fm и отправлять его в каждом HTTP-запросе. Мы собираемся использовать следующую службу модернизации для вызова этих API:
public interface LastFmService {
@GET("/2.0/?method=chart.gettopartists&format=json&limit=50")
Call<Artists> topArtists(@Query("page") int page);
@GET("/2.0/?method=artist.gettoptags&format=json&limit=20&autocorrect=1")
Call<Tags> topTagsFor(@Query("artist") String artist);
@GET("/2.0/?method=chart.gettoptags&format=json&limit=100")
Call<TopTags> topTags();
// A few DTOs and one interceptor
}
Итак, найдем самых популярных исполнителей на Last.fm:
// setting up the Retrofit service
private static List<String> getTop100Artists() throws IOException {
List<String> artists = new ArrayList<>();
// Fetching the first two pages, each containing 50 records.
for (int i = 1; i <= 2; i++) {
artists.addAll(lastFm.topArtists(i).execute().body().all());
}
return artists;
}
Точно так же мы можем получить верхние теги:
private static Set<String> getTop100Tags() throws IOException {
return lastFm.topTags().execute().body().all();
}
Наконец, мы можем создать набор данных исполнителей вместе с частотами их тегов:
private static List<Record> datasetWithTaggedArtists(List<String> artists,
Set<String> topTags) throws IOException {
List<Record> records = new ArrayList<>();
for (String artist : artists) {
Map<String, Double> tags = lastFm.topTagsFor(artist).execute().body().all();
// Only keep popular tags.
tags.entrySet().removeIf(e -> !topTags.contains(e.getKey()));
records.add(new Record(artist, tags));
}
return records;
}
4.2. Формирование кластеров артистов
Теперь мы можем передать подготовленный набор данных в нашу реализацию K-средних:
List<String> artists = getTop100Artists();
Set<String> topTags = getTop100Tags();
List<Record> records = datasetWithTaggedArtists(artists, topTags);
Map<Centroid, List<Record>> clusters = KMeans.fit(records, 7, new EuclideanDistance(), 1000);
// Printing the cluster configuration
clusters.forEach((key, value) -> {
System.out.println("-------------------------- CLUSTER ----------------------------");
// Sorting the coordinates to see the most significant tags first.
System.out.println(sortedCentroid(key));
String members = String.join(", ", value.stream().map(Record::getDescription).collect(toSet()));
System.out.print(members);
System.out.println();
System.out.println();
});
Если мы запустим этот код, он будет визуализировать кластеры в виде текстового вывода:
------------------------------ CLUSTER -----------------------------------
Centroid {classic rock=65.58333333333333, rock=64.41666666666667, british=20.333333333333332, ... }
David Bowie, Led Zeppelin, Pink Floyd, System of a Down, Queen, blink-182, The Rolling Stones, Metallica,
Fleetwood Mac, The Beatles, Elton John, The Clash
------------------------------ CLUSTER -----------------------------------
Centroid {Hip-Hop=97.21428571428571, rap=64.85714285714286, hip hop=29.285714285714285, ... }
Kanye West, Post Malone, Childish Gambino, Lil Nas X, A$AP Rocky, Lizzo, xxxtentacion,
Travi$ Scott, Tyler, the Creator, Eminem, Frank Ocean, Kendrick Lamar, Nicki Minaj, Drake
------------------------------ CLUSTER -----------------------------------
Centroid {indie rock=54.0, rock=52.0, Psychedelic Rock=51.0, psychedelic=47.0, ... }
Tame Impala, The Black Keys
------------------------------ CLUSTER -----------------------------------
Centroid {pop=81.96428571428571, female vocalists=41.285714285714285, indie=22.785714285714285, ... }
Ed Sheeran, Taylor Swift, Rihanna, Miley Cyrus, Billie Eilish, Lorde, Ellie Goulding, Bruno Mars,
Katy Perry, Khalid, Ariana Grande, Bon Iver, Dua Lipa, Beyoncé, Sia, P!nk, Sam Smith, Shawn Mendes,
Mark Ronson, Michael Jackson, Halsey, Lana Del Rey, Carly Rae Jepsen, Britney Spears, Madonna,
Adele, Lady Gaga, Jonas Brothers
------------------------------ CLUSTER -----------------------------------
Centroid {indie=95.23076923076923, alternative=70.61538461538461, indie rock=64.46153846153847, ... }
Twenty One Pilots, The Smiths, Florence + the Machine, Two Door Cinema Club, The 1975, Imagine Dragons,
The Killers, Vampire Weekend, Foster the People, The Strokes, Cage the Elephant, Arcade Fire,
Arctic Monkeys
------------------------------ CLUSTER -----------------------------------
Centroid {electronic=91.6923076923077, House=39.46153846153846, dance=38.0, ... }
Charli XCX, The Weeknd, Daft Punk, Calvin Harris, MGMT, Martin Garrix, Depeche Mode, The Chainsmokers,
Avicii, Kygo, Marshmello, David Guetta, Major Lazer
------------------------------ CLUSTER -----------------------------------
Centroid {rock=87.38888888888889, alternative=72.11111111111111, alternative rock=49.16666666, ... }
Weezer, The White Stripes, Nirvana, Foo Fighters, Maroon 5, Oasis, Panic! at the Disco, Gorillaz,
Green Day, The Cure, Fall Out Boy, OneRepublic, Paramore, Coldplay, Radiohead, Linkin Park,
Red Hot Chili Peppers, Muse
Поскольку центроидные координации сортируются по средней частоте тегов, мы можем легко определить доминирующий жанр в каждом кластере. Например, последний кластер — это кластер старых добрых рок-групп, или второй заполнен звездами рэпа.
Хотя эта кластеризация имеет смысл, по большей части она не идеальна, поскольку данные просто собираются на основе поведения пользователя.
5. Визуализация
Несколько мгновений назад наш алгоритм визуализировал кластер исполнителей удобным для терминала способом. Если мы преобразуем нашу конфигурацию кластера в JSON и скормим ее D3.js, то с помощью нескольких строк JavaScript у нас будет приятное и удобное для человека Radial Tidy-Tree :
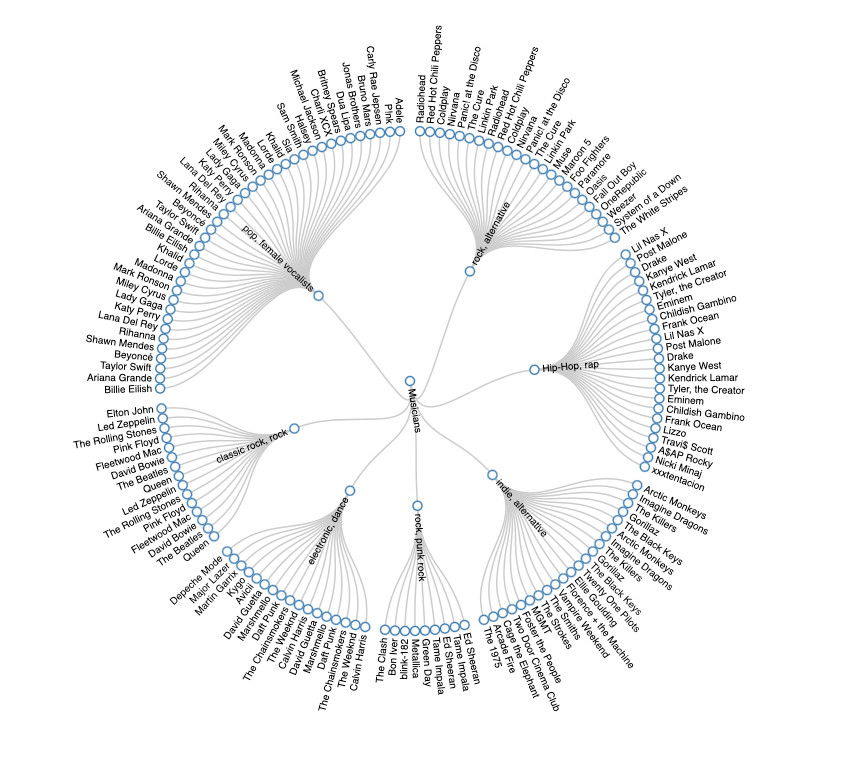
Нам нужно преобразовать нашу карту<Centroid, List<Record>> в JSON с аналогичной схемой, как в этом примере d3.js.
6. Количество кластеров
Одним из фундаментальных свойств K-средних является тот факт, что мы должны заранее определить количество кластеров. До сих пор мы использовали статическое значение k , но определение этого значения может оказаться сложной задачей. Существует два распространенных способа подсчета количества кластеров:
- Базовые знания
- Математическая эвристика
Если нам повезет, что мы так много знаем о домене, то мы сможем просто угадать правильное число. В противном случае мы можем применить несколько эвристик, таких как метод локтя или метод силуэта, чтобы получить представление о количестве кластеров.
Прежде чем идти дальше, мы должны знать, что эти эвристики, хотя и полезны, являются всего лишь эвристиками и могут не давать четких ответов.
6.1. Метод локтя
Чтобы использовать метод локтя, мы должны сначала вычислить разницу между центроидами каждого кластера и всеми его элементами. По мере того, как мы группируем в кластер больше несвязанных элементов, расстояние между центроидом и его элементами увеличивается, следовательно, качество кластера снижается.
Один из способов выполнить это вычисление расстояния состоит в том, чтобы использовать Sum of Squared Errors . Сумма квадратов ошибок или SSE равна сумме квадратов разностей между центроидом и всеми его элементами :
public static double sse(Map<Centroid, List<Record>> clustered, Distance distance) {
double sum = 0;
for (Map.Entry<Centroid, List<Record>> entry : clustered.entrySet()) {
Centroid centroid = entry.getKey();
for (Record record : entry.getValue()) {
double d = distance.calculate(centroid.getCoordinates(), record.getFeatures());
sum += Math.pow(d, 2);
}
}
return sum;
}
Затем мы можем запустить алгоритм K-средних для разных значений k и вычислить SSE для каждого из них:
List<Record> records = // the dataset;
Distance distance = new EuclideanDistance();
List<Double> sumOfSquaredErrors = new ArrayList<>();
for (int k = 2; k <= 16; k++) {
Map<Centroid, List<Record>> clusters = KMeans.fit(records, k, distance, 1000);
double sse = Errors.sse(clusters, distance);
sumOfSquaredErrors.add(sse);
}
В конце концов, можно найти подходящее k , построив график количества кластеров в зависимости от SSE:
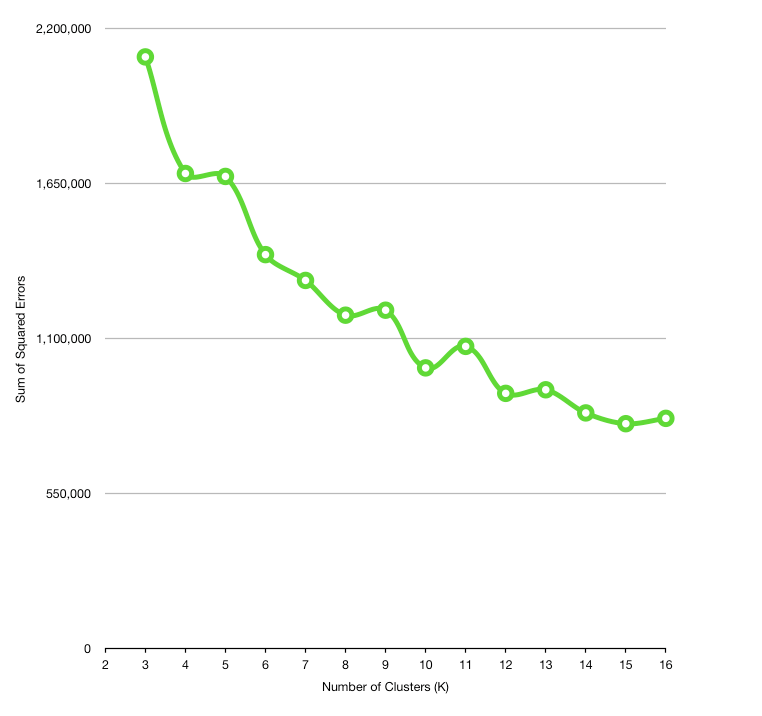
Обычно по мере увеличения числа кластеров расстояние между членами кластера уменьшается. Однако мы не можем выбрать какие-либо произвольно большие значения для k, так как наличие нескольких кластеров, состоящих всего из одного члена, сводит на нет всю цель кластеризации.
Идея метода локтя состоит в том, чтобы найти подходящее значение k таким образом, чтобы SSE резко уменьшалась вокруг этого значения. Например, k=9 может быть здесь хорошим кандидатом.
7. Заключение
В этом уроке мы сначала рассмотрели несколько важных концепций машинного обучения. Затем мы познакомились с механикой алгоритма кластеризации K-Means. Наконец, мы написали простую реализацию для K-средних, протестировали наш алгоритм с реальным набором данных из Last.fm и визуализировали результат кластеризации в приятном графическом виде.
Как обычно, пример кода доступен в нашем проекте GitHub , так что обязательно ознакомьтесь с ним!