1. Введение
Apache Kafka — самая популярная распределенная и отказоустойчивая система обработки потоков с открытым исходным кодом. Kafka Consumer предоставляет основные функции для обработки сообщений. Kafka Streams также обеспечивает потоковую обработку в реальном времени поверх клиента Kafka Consumer.
В этом руководстве мы объясним функции Kafka Streams, чтобы упростить и упростить обработку потоков.
2. Разница между потоками и потребительскими API
2.1. Потребительский API Кафки
Вкратце, Kafka Consumer API позволяет приложениям обрабатывать сообщения из тем. Он предоставляет основные компоненты для взаимодействия с ними, включая следующие возможности :
- Разделение ответственности между потребителями и производителями
- Одиночная обработка
- Поддержка пакетной обработки
- Только поддержка без гражданства. Клиент не сохраняет предыдущее состояние и оценивает каждую запись в потоке отдельно
- Для написания приложения требуется много кода
- Отсутствие использования потоков или параллелизма
- Можно писать в несколько кластеров Kafka
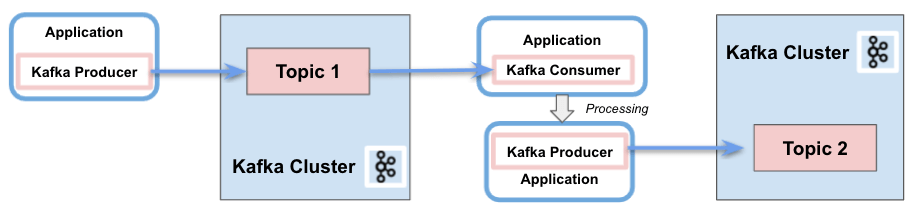
2.2. API потоков Kafka
Kafka Streams значительно упрощает обработку потоков из топиков. Построенный на основе клиентских библиотек Kafka, он обеспечивает параллелизм данных, распределенную координацию, отказоустойчивость и масштабируемость . Он работает с сообщениями как с неограниченным, непрерывным потоком записей в реальном времени со следующими характеристиками:
- Единый поток Kafka для потребления и производства
- Выполнять сложную обработку
- Не поддерживать пакетную обработку
- Поддержка операций без сохранения состояния и с сохранением состояния
- Для написания приложения требуется несколько строк кода
- Многопоточность и параллелизм
- Взаимодействуйте только с одним кластером Kafka.
- Потоковые разделы и задачи как логические единицы для хранения и транспортировки сообщений
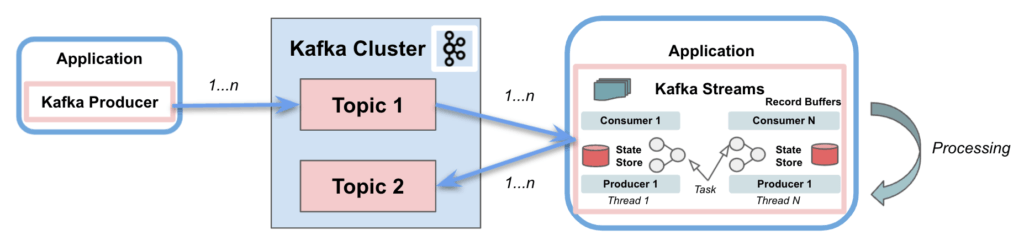
Kafka Streams использует концепцию разделов и задач как логических единиц, тесно связанных с тематическими разделами . Кроме того, он использует потоки для распараллеливания обработки внутри экземпляра приложения. Еще одна важная поддерживаемая возможность — это хранилища состояний, используемые Kafka Streams для хранения и запроса данных, поступающих из тем. Наконец, Kafka Streams API взаимодействует с кластером, но не работает непосредственно поверх него.
В следующих разделах мы сосредоточимся на четырех аспектах, которые имеют значение по отношению к базовым клиентам Kafka: двойственность потоковой таблицы, предметно-ориентированный язык Kafka Streams (DSL), семантика обработки Exactly-Once (EOS) и интерактивные запросы. .
2.3. Зависимости
Чтобы реализовать примеры, мы просто добавим зависимости Kafka Consumer API и Kafka Streams API в наш pom.xml :
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.8.0</version>
</dependency>
3. Двойственность потоковой таблицы
Kafka Streams поддерживает потоки, а также таблицы, которые можно преобразовывать в двух направлениях. Это так называемая двойственность потоковой таблицы . Таблицы представляют собой набор изменяющихся фактов. Каждое новое событие перезаписывает старое, тогда как потоки представляют собой набор неизменных фактов.
Потоки обрабатывают полный поток данных из темы. Таблицы сохраняют состояние, собирая информацию из потоков. Давайте представим игру в шахматы, как описано в Kafka Data Modeling . Поток непрерывных ходов агрегируется в таблицу, и мы можем переходить из одного состояния в другое:
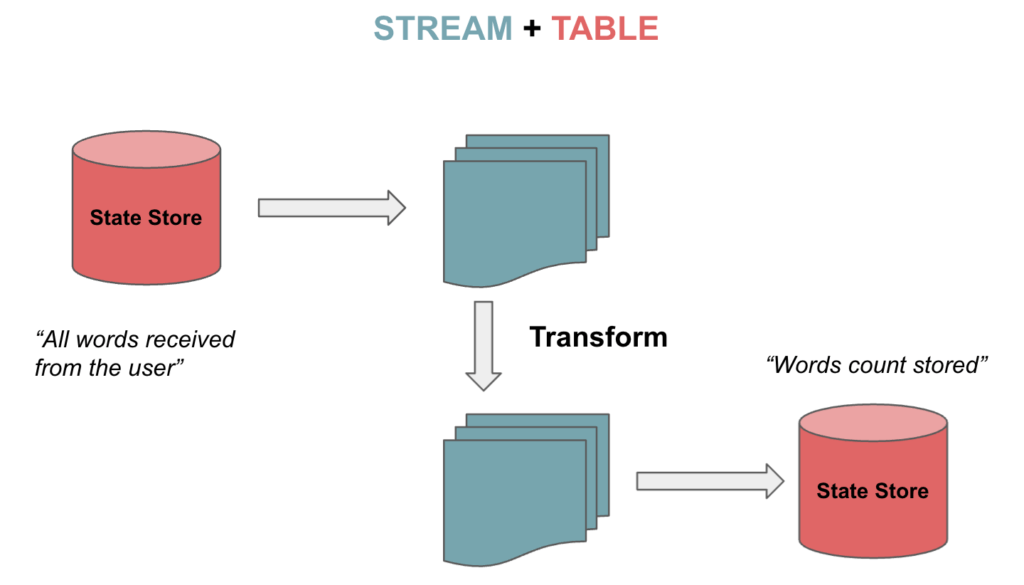
3.1. KStream , KTable и GlobalKTable
Kafka Streams предоставляет две абстракции для потоков и таблиц . KStream обрабатывает поток записей. С другой стороны, KTable управляет потоком журнала изменений с последним состоянием данного ключа. Каждая запись данных представляет собой обновление.
Есть еще одна абстракция для несекционированных таблиц. Мы можем использовать GlobalKTables для передачи информации всем задачам или для объединения без повторного разделения входных данных.
Мы можем прочитать и десериализовать тему как поток:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines =
builder.stream(inputTopic, Consumed.with(Serdes.String(), Serdes.String()));
Также возможно чтение темы для отслеживания последних слов, полученных в виде таблицы:
KTable<String, String> textLinesTable =
builder.table(inputTopic, Consumed.with(Serdes.String(), Serdes.String()));
Наконец, мы можем прочитать тему, используя глобальную таблицу:
GlobalKTable<String, String> textLinesGlobalTable =
builder.globalTable(inputTopic, Consumed.with(Serdes.String(), Serdes.String()));
4. Кафка Потоки DSL
Kafka Streams DSL — это декларативный и функциональный стиль программирования . Он построен на основе API Streams Processor . Язык предоставляет встроенные абстракции для потоков и таблиц, упомянутых в предыдущем разделе.
Кроме того, он также поддерживает преобразования без сохранения состояния ( карта , фильтр и т. д.) и преобразования с состоянием ( агрегации , объединения и управление окнами ). Таким образом, можно реализовать операции потоковой обработки всего несколькими строками кода.
4.1. Преобразования без сохранения состояния
Преобразования без сохранения состояния не требуют состояния для обработки. Точно так же в потоковом процессоре не требуется хранилище состояний. Примеры операций: filter , map , flatMap или groupBy .
Давайте теперь посмотрим, как сопоставить значения как UpperCase, отфильтровать их из темы и сохранить в виде потока:
KStream<String, String> textLinesUpperCase =
textLines
.map((key, value) -> KeyValue.pair(value, value.toUpperCase()))
.filter((key, value) -> value.contains("FILTER"));
4.2. Преобразования с отслеживанием состояния
Преобразования с отслеживанием состояния зависят от состояния выполнения операций обработки. Обработка сообщения зависит от обработки других сообщений (хранилище состояний). Другими словами, любую таблицу или хранилище состояний можно восстановить с помощью темы журнала изменений.
Примером преобразования с отслеживанием состояния является алгоритм подсчета слов:
KTable<String, Long> wordCounts = textLines
.flatMapValues(value -> Arrays.asList(value
.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>> as("counts-store"));
Мы отправим эти две строки в тему:
String TEXT_EXAMPLE_1 = "test test and test";
String TEXT_EXAMPLE_2 = "test filter filter this sentence";
Результат:
Word: and -> 1
Word: test -> 4
Word: filter -> 2
Word: this -> 1
Word: sentence -> 1
DSL охватывает несколько функций преобразования. Мы можем объединить или объединить два входных потока/таблицы с одним и тем же ключом, чтобы создать новый поток/таблицу. Мы также можем агрегировать или объединять несколько записей из потоков/таблиц в одну запись в новой таблице. Наконец, можно применить управление окнами для группировки записей с одинаковым ключом в функциях соединения или агрегации.
Пример соединения с 5s windowing объединит сгруппированные по ключу записи из двух потоков в один поток:
KStream<String, String> leftRightSource = leftSource.outerJoin(rightSource,
(leftValue, rightValue) -> "left=" + leftValue + ", right=" + rightValue,
JoinWindows.of(Duration.ofSeconds(5))).groupByKey()
.reduce(((key, lastValue) -> lastValue))
.toStream();
Итак, мы поместим в левый поток value=left с ключом=1 и правый поток value=right и key=2 . Результат следующий:
(key= 1) -> (left=left, right=null)
(key= 2) -> (left=null, right=right)
Для примера агрегации мы вычислим алгоритм подсчета слов, используя в качестве ключа первые две буквы каждого слова:
KTable<String, Long> aggregated = input
.groupBy((key, value) -> (value != null && value.length() > 0)
? value.substring(0, 2).toLowerCase() : "",
Grouped.with(Serdes.String(), Serdes.String()))
.aggregate(() -> 0L, (aggKey, newValue, aggValue) -> aggValue + newValue.length(),
Materialized.with(Serdes.String(), Serdes.Long()));
Со следующими записями:
"one", "two", "three", "four", "five"
Результат:
Word: on -> 3
Word: tw -> 3
Word: th -> 5
Word: fo -> 4
Word: fi -> 4
5. Семантика однократной обработки (EOS)
Бывают случаи, когда нам нужно убедиться, что потребитель прочитает сообщение ровно один раз. Kafka представила возможность включения сообщений в транзакции для реализации EOS с помощью Transactional API . Та же функция реализована в Kafka Streams с версии 0.11.0.
Чтобы настроить EOS в Kafka Streams, мы включим следующее свойство:
streamsConfiguration.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG,
StreamsConfig.EXACTLY_ONCE);
6. Интерактивные запросы
Интерактивные запросы позволяют получить информацию о состоянии приложения в распределенных средах . Это означает возможность извлечения информации из локальных хранилищ, а также из удаленных хранилищ в нескольких экземплярах. По сути, мы соберем все хранилища и сгруппируем их вместе, чтобы получить полное состояние приложения.
Давайте рассмотрим пример с использованием интерактивных запросов. Во-первых, определим топологию обработки, в нашем случае алгоритм подсчета слов:
KStream<String, String> textLines =
builder.stream(TEXT_LINES_TOPIC, Consumed.with(Serdes.String(), Serdes.String()));
final KGroupedStream<String, String> groupedByWord = textLines
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word, Grouped.with(stringSerde, stringSerde));
Далее мы создадим хранилище состояний (ключ-значение) для всех вычисленных значений количества слов:
groupedByWord
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("WordCountsStore")
.withValueSerde(Serdes.Long()));
Затем мы можем запросить хранилище ключей и значений:
ReadOnlyKeyValueStore<String, Long> keyValueStore =
streams.store(StoreQueryParameters.fromNameAndType(
"WordCountsStore", QueryableStoreTypes.keyValueStore()));
KeyValueIterator<String, Long> range = keyValueStore.all();
while (range.hasNext()) {
KeyValue<String, Long> next = range.next();
System.out.println("count for " + next.key + ": " + next.value);
}
Результат примера следующий:
Count for and: 1
Count for filter: 2
Count for sentence: 1
Count for test: 4
Count for this: 1
7. Заключение
В этом руководстве мы показали, как Kafka Streams упрощает операции обработки при получении сообщений из тем Kafka. Это сильно упрощает реализацию при работе с потоками в Kafka. Не только для обработки без сохранения состояния, но и для преобразований с отслеживанием состояния.
Конечно, можно идеально создать потребительское приложение без использования Kafka Streams. Но нам нужно было бы вручную реализовать кучу дополнительных функций, предоставляемых бесплатно.
Как всегда, код доступен на GitHub .